向量数据库有哪些国产
发布时间:2025-05-24 18:28:20 发布人:远客网络
一、向量数据库有哪些国产
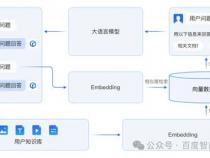
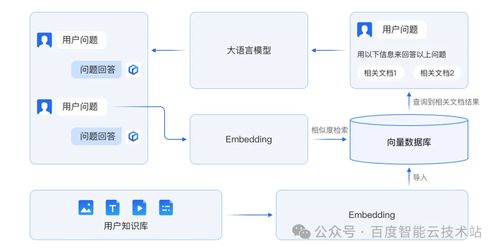
1、向量数据库是一种特殊类型的数据库,用于存储、索引和查询向量数据,这些数据通常用于机器学习、人工智能和相似性搜索等应用。在国产向量数据库方面,目前市场上有几款知名的产品。
2、首先,Milvus是一款由上海赜睿信息科技有限公司开源的向量数据库产品。作为全球首个开源的向量数据库,Milvus在GitHub上获得了极高的关注度,其设计专门用于处理对输入向量的查询,并能够以万亿级对向量进行索引。它的自下而上的设计使其非常适合处理从非结构化数据转换的嵌入向量,这与传统的关系数据库有显著的差异。
3、其次,还有如Vearch这样的分布式向量搜索系统,由京东研发,它基于Faiss实现并提供了快速的向量检索功能。Vearch通过类似Elasticsearch的Restful API,使用户可以方便地对数据及表结构进行管理查询等工作,广泛应用于图像、音视频处理和自然语言处理等领域。
4、再者,爱可生公司的TensorDB也是一个值得关注的向量数据库软件。它完全自主设计研发,实现了超大规模向量型数据的高效组织,并设计了易扩展的索引结构,以支撑时变环境下的向量数据快速比对。TensorDB在多个领域都有应用,包括互联网服务、工业制造、金融和安防等。
5、最后,杭州联汇科技股份有限公司的Om-iBASE也是一款重要的向量数据库产品。它基于智能算法提取需存储内容的特征,并将其转变成具有大小定义、特征描述、空间位置的多维数值进行向量化存储,使内容不仅可被存储,还可被智能检索与分析。
6、这些国产向量数据库产品各具特色,不仅支持大规模的向量数据存储,还提供了高效的搜索和分析能力,满足了不同行业和应用场景的需求,为大数据和人工智能领域的发展提供了强有力的支持。
二、国产向量数据库有哪些
1、国产向量数据库主要包括Milvus、Milvus Cloud、Tencent Cloud VectorDB、Zilliz Cloud、TensorDB、cVector、Om-iBASE、Vearch、Transwarp Hippo等。
2、其中,Milvus是国内首个支持海量向量数据存储和查询的开源向量数据库,它以高性能、高扩展性和易用性强的特点脱颖而出。Milvus还提供了一系列高级功能,如向量搜索、相似度计算、聚类等,可以满足不同领域的需求。Milvus Cloud则是Milvus的云服务版本,它提供了云端向量数据库服务,支持多种数据源接入和多种查询语言,同时还提供了可视化界面和API接口,方便用户进行数据管理和查询。
3、另外,Tencent Cloud VectorDB是腾讯云推出的向量数据库产品,它具有高性能、高扩展性和高安全性的特点,支持多种数据类型和多种查询语言,同时还提供了丰富的的高级功能,如相似度计算、搜索等。
4、除了上述数据库外,还有如Zilliz Cloud、TensorDB、cVector等其他优秀的国产向量数据库。这些数据库各具特色,都能满足不同场景下的数据处理需求。
5、值得一提的是,Transwarp Hippo作为一款企业级云原生分布式向量数据库,也备受关注。它支持存储、索引以及管理海量的向量式数据集,能够高效地解决向量相似度检索以及高密度向量聚类等问题。Hippo具备高可用、高性能、易拓展等特点,支持多种向量搜索索引,能很好地满足企业针对海量向量数据的高实时性检索等场景。
6、总的来说,国产向量数据库在近年来得到了快速发展,涌现出了许多优秀的产品。这些数据库在人工智能、图像处理、自然语言处理等领域发挥着越来越重要的作用。
三、主流向量数据库有哪些
1、主流向量数据库主要包括Faiss、Milvus、Pinecone、Weaviate、Qdrant和Vald等。
2、首先,Faiss是一个由Facebook开发的用于高效相似性搜索和密集向量聚类的库。它使用C++编写,提供Python接口,支持对10亿量级的索引进行毫秒级检索,性能卓越。Faiss包含的算法可以搜索任意大小的向量集,甚至处理那些无法完全加载到RAM中的大型向量集。
3、其次,Milvus是一款开源的向量数据库,专门设计用于管理大规模的向量数据集。它支持高性能的向量存储和检索功能,提供了丰富的向量索引和搜索功能,如IVF、HNSW和NSG等索引算法。Milvus能够轻松地处理大规模的向量数据集,并提供了易用的API和丰富的查询接口,便于用户进行向量相似性搜索和近似最近邻搜索等操作。
4、再者,Pinecone是一个专为机器学习应用程序设计的矢量数据库,它速度快、可扩展,并支持多种机器学习算法。Pinecone建立在Faiss之上,进一步提升了向量搜索的效率和可扩展性。
5、此外,Weaviate是一个开源的向量数据库,允许用户存储数据对象和来自机器学习模型的向量嵌入,并能无缝扩展到数十亿个数据对象。它提供了快速且精确的向量搜索功能,支持毫秒级的响应时间。
6、Qdrant也是一个值得关注的向量数据库,它提供了一个生产就绪的服务,配备方便的API来存储、搜索和管理点——这些点实际上是带有额外有效负载的向量。Qdrant特别适合进行扩展过滤支持,可用于各种神经网络或基于语义的匹配、分面搜索等应用。
7、最后,Vald是一个高度可扩展的分布式快速近似最近邻密集向量搜索引擎,它使用最快的ANN算法NGT进行搜索,具有自动向量索引和索引备份功能,支持水平缩放,并能从数十亿特征向量数据中进行搜索。
8、综上所述,这些主流向量数据库以其高性能、高效的向量存储和检索功能脱颖而出,适用于处理大规模的向量数据集和进行复杂的向量相似性搜索任务。根据具体需求和场景选择合适的向量数据库将大大提升数据处理和分析的效率。