Spring Boot中使用时序数据库InfluxDB
发布时间:2025-05-24 17:12:05 发布人:远客网络
一、Spring Boot中使用时序数据库InfluxDB
除了最常用的关系数据库和缓存之外,之前我们已经介绍了在Spring Boot中如何配置和使用 MongoDB、 LDAP这些存储的案例。接下来,我们继续介绍另一种特殊的数据库:时序数据库InfluxDB在Spring Boot中的使用。
什么是时序数据库?全称为时间序列数据库。时间序列数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。时间序列数据主要由电力行业、化工行业等各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十GB的数据量)。虽然关系型数据库也可以存储基于时间序列的数据,但由于存储结构上的劣势,使得这些数据无法高效地实现高频存储和查询统计,因此就诞生了一种专门针对时间序列来做存储和优化的数据库,以满足更高的效率要求。(参考:百度百科:时序数据库)
InfluxDB就是目前比较流行的开源时序数据库(官网地址:),我们比较常见的使用场景就是一些与时间相关的高频的数据记录和统计需要,比如:监控数据的存储和查询。
在进行下面的动手环节之前,先了解一下InfluxDB中的几个重要名词:
其中,一个Point由三个部分组成:
在了解了什么是时序数据库以及InfluxDB一些基础概念之后,下面我们通过一个简单的定时上报监控数据的小案例,进一步理解InfluxDB的基础配置、数据组织和写入操作!
第一步:创建一个基础的Spring Boot项目(如果您还不会,可以参考这篇文章:快速入门()
第二步:在 pom.xml中引入influx的官方SDK
注意:这里因为Spring Boot 2.x版本的parent中有维护InfluxDB的SDK版本,所以不需要手工指明版本信息。如果使用的Spring Boot版本比较老,那么可能会缺少version信息,就需要手工写了。
第三步:配置要连接的influxdb信息
三个属性分别代表:连接地址、用户名、密码。到这一步,基础配置就完成了。
注意:虽然没有spring data的支持,但spring boot 2.x版本中也实现了InfluxDB的自动化配置,所以只需要写好配置信息,就可以使用了。具体配置属性可以查看源码: org.springframework.boot.autoconfigure.influx.InfluxDbProperties。
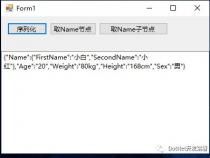
第四步:创建定时任务,模拟上报数据,并写入InfluxDB
第一步:启动InfluxDB,并通过命令行准备好要使用的数据库,主要涉及的命令如下;
第二步:启动Spring Boot应用,在定时任务的作用下,我们会看到类似下面的日志:
第三步:通过命令,查看一下InfluxDB中是否已经存在这些数据
可以看到,已经存在与日志中一样的数据了。
本文的完整工程可以查看下面仓库中 2.x目录下的 chapter6-3:
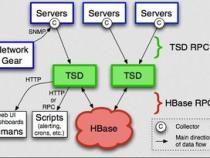
二、时序数据库技术体系 – InfluxDB TSM存储引擎之数据写入
1、关于时序数据库InfluxDB的TSM存储引擎,其数据写入过程涉及多个步骤。首先,用户可以使用多种接口协议如collected、opentsdb或http、udp批量写入数据,这些数据会经过批处理,按照InfluxDB的Sharding策略进行分组,即按照时间范围和SeriesKey的哈希值分配到不同的shard。单机InfluxDB主要基于时间范围进行分片,而分布式版本会包括哈希分片。
2、写入过程中,数据首先经过倒排索引引擎,构建LSM(Log-Structured Merge)结构。LSM引擎因其对写入性能的优化,适合写多读少的场景,如时序数据库。数据写入WAL(Write Ahead Log)后,会被缓存并返回给用户确认写入成功。当满足特定条件,数据会被从缓存flush到磁盘,形成文件并通过合并优化存储效率。
3、对于时序数据的写入,数据点会先按照SeriesKey进行处理,确认其是否已存在于倒排索引中。如果不存在,就将其写入内存的倒排索引中,这个索引包含了测量值与维度值的映射关系。写入过程会触发flush操作,将内存中的数据写入TSM文件,并在内存中构建Index Entry。
4、在删除操作上,InfluxDB采取了特殊的策略,通常不会删除单个记录,而是删除指定范围或维度的数据。删除操作在TSM Engine和倒排索引Engine中各有不同的处理方式,TSM Engine执行同步删除,而倒排索引Engine则标记删除。
5、总的来说,InfluxDB的写入流程复杂但设计巧妙,理解其内部结构对于深入掌握其工作原理至关重要。尽管写入过程可能显得繁琐,但理解了文件内部组织和倒排索引的结构,就能更好地掌握其工作原理。而新一代的WRITE-BUG平台提供了优秀的创作和协作体验,是理解时序数据库技术的好帮手。
三、时序数据库 -- InlfuxDB
InlfuxDB是一种高性能查询和存储的时序性数据库。
时间序列数据如同历史烙印,具有不变性、唯一性和时间排序性。
时间序列数据是基于时间的一系列数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放事件序列数据的数据库,需要支持时序数据的快速写入、持久化、多维度的聚合查询等基本功能。
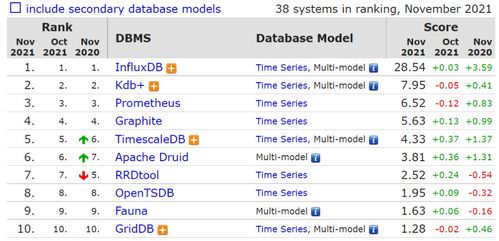
InfluxDB是一个由InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。
InfluxDB主要有以下图中的几个概念:Point,Measurement,Tags,Fields,Timestamp,Series,下面依次简单介绍下每个概念的含义。
InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。此外它还有如下特性:
TICK是由InfluxData开发的一套运维工具栈,由Telegraf, InfluxDB, Chronograf, Kapacitor四个工具的首字母组成。
这一套组件将收集数据和入库、数据库、绘图、告警四者囊括了。
Telegraf是一个数据收集和入库的工具。提供了很多input和output插件,比如收集本地的cpu、load、网络流量等数据,然后写入InfluxDB或者Kafka等。
Chronograf绘图工具,有点是绑定了Kapacitor,目前大多数选择了成熟很多的Grafana。
Kapacitor是InfluxData家的告警工具,通过读取InfluxDB中的数据,根据DLS类型配置TickScript来进行告警。
InfluxDB本身是支持集群化的,但是开源的不支持。InfluxDB在0.12版本开始不再开源cluster源码,而是被用作提供商业服务。
目前官方开源的InfluxDB-Relay采用的是双写模式,仅仅解决数据备份的问题,并为解决influxdb的读写性能问题。
即使是单机版,其性能也足以支撑大部分业务。
InfluxDB目前推出了2.0版本,由于改动较大,所以和1.x版本并存。目前官方推荐的稳定版本依旧是1.x版本。2.0主要的更改包括以下内容: