INDEX函数与MATCH函数嵌套使用技巧
发布时间:2025-05-24 01:15:07 发布人:远客网络

一、INDEX函数与MATCH函数嵌套使用技巧
这里分享一个对INDEX函数+MATCH函数嵌套的小总结~~
首先呢,INDEX函数+MATCH函数嵌套的最基本格式如下:
index(序列1,match(值,序列2,0))
根据“值”在序列2中的位置,得出序列1中相同位置的值(模糊查找时,最后参数也可能是1、-1)。
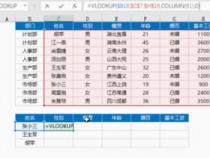
这个看似和vlookup函数很像,但它不需要源数据的严格对齐,也不需要查找值必须在首列,更为灵活一些~
这样的反向查找,其实用VLOOKUP、LOOKUP、INDEX+MATCH都是可以做到的,3个公式分别如下:
=VLOOKUP(E3,IF({1,0},$C$2:$C$9,$B$2:$B$9),2,FALSE)
=LOOKUP(1,0/($C$2:$C$9=E3),$B$2:$B$9)
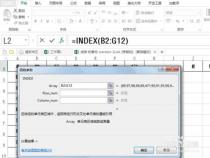
=INDEX($B$2:$B$9,MATCH(E3,$C$2:$C$9,0))
这个基本实例中,序列1就是B2:B9,序列2是C2:C9,查找值是E3。以上,可见3者异同。
除了以上的基本情景,INDEX+MATCH嵌套也可能会用在其他的怪异需求中。
要将B列内容各自重复C列指定的次数,形成一个新的序列。
首先,我们想到用INDEX来提取B列内容:
它得是一个在下拉的时候,前6个取值是1,然后2个2,然后5个3,然后3个4,这样的序列。
我们自然想到,先将频次序列{6,2,5,3}变成累计序列{6,8,13,16},然后从0开始对它进行模糊查找,如下:
=MATCH(ROW(A1)-1,{6,8,13,16},1)
{#N/A,#N/A,#N/A,#N/A,#N/A,#N/A,1,1,2,2,2,2,2,3,3,3}
这个序列,离我们想要的序列还有两点不同:1都变成了错误值,后面的取值也都少了1;据此可以在后面+1,前面增加IFERROR:
=IFERROR(MATCH(ROW(A1)-1,{6,8,13,16},1)+1,1)
此时,成功获得了想要的序列X,那么将它替换回原公式,即:
=INDEX($B$14:$B$17,IFERROR(MATCH(ROW(A1)-1,{6,8,13,16},1)+1,1))
最后,还有一个问题,即公式中的累计序列如何计算得到?
这可以用offset选定区域并求和获得:
=SUBTOTAL(9,OFFSET($C$14,,,ROW($1:$4),1))
即将C14分别向下1、2、3、4格的区域求和。
用以上公式替代掉{6,8,13,16},则最终的公式为:
=INDEX($B$14:$B$17,IFERROR(MATCH(ROW(A1)-1,SUBTOTAL(9,OFFSET($C$14,,,ROW($1:$4),1)),1)+1,1))
以上是数组公式,需三键结束,下拉。
二、...index+match查找函数用法-嵌套match函数-excel表格
1、在本系列有关INDEX-MATCH的第1部分中,我从以下两个示例开始:
2、公式1:= INDEX(Product,2,1)
3、我解释说,在我使用的特定工作簿中,两个公式返回的结果完全相同。
4、好吧,几十年前,Excel首次推出后不久,我就在电话上与Excel Program Manager进行了交谈。考虑到像这两个公式这样的示例,我告诉他INDEX是一个无用的函数,因为它要求我们为行和列参数输入数字。
5、我说:“如果我们知道要使用的行号和列号,那么我们也可以输入单元格地址。那么索引的意义是什么?”
6、他对我很耐心。他说:“查理,您看过MATCH函数吗?我们创建了MATCH专门用于INDEX。”
7、好吧,正如Excel的首席执行长在几年前建议我做的那样,今天,我们将看一下MATCH函数……该函数是专门为与INDEX配合使用而创建的。
8、(此链接使您可以在此处下载所有三个示例工作簿的zip文件。)
9、MATCH是一种查找功能,例如VLOOKUP,HLOOKUP和LOOKUP。但是与其他函数不同,MATCH不会返回找到的值。而是,MATCH返回单个行,列或一维数组中查找值的位置。
10、为了说明,如果您的查找值是查找数组中的第三项,则MATCH返回3。或者,如果您的查找值位于查找数组中的第67位,则MATCH返回67。
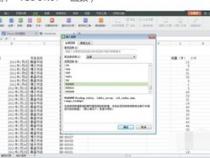
11、= MATCH(lookup_value,lookup_array,match_type)
12、lookup_array是单个行或列,或者是一维数组,MATCH在其中应查找lookup_value。
13、match_type是三个数字之一,用于指定数据的排序方式和MATCH的执行方式。
14、以下是有关您可以为match_type输入的三个数字的简短说明...
15、Match_Type=0。大约95%的时间将使用此类型。无论lookup_array的排序方式如何,它都会返回在lookup_array中找到的第一个匹配项的位置。如果Lookup_Array中是不是在你的查找数组,MATCH将返回#N/ A。
16、Match_Type=1。仅出于特定原因,并且仅对以升序排序的数据使用此类型。如果数据不是按升序排列,则MATCH可能返回错误的结果或错误的#N/ A值。如果lookup_value不在lookup_array中,则MATCH返回小于或等于lookup_value的最大值的位置。(我稍后将为您提供示例。)
17、Match_Type=-1。我认为我从未找到过将match_type用于实际工作的理由。您只能将此类型用于按降序排序的数据。如果lookup_value不在您的lookup_array中,则它将使MATCH返回大于或等于lookup_value的最小值的位置。
18、您大约有95%的时间会使用这种类型。无论您的lookup_array如何排序,它都会返回正确的结果。如果lookup_value不在您的lookup_array中,则MATCH返回#N/ A。
19、MATCH类型等于零本示例使用未排序的表。也就是说,数据是随机的。
20、公式3:= MATCH(6,Test,0) [结果= 3]
21、MATCH沿“测试”列向下移动,直到找到6,然后返回3,表示值6是列表中的第三项。
22、公式4:= MATCH(7,Test,0) [结果=#N/ A]
23、MATCH浏览整个列表,但是找不到值7。因此,它返回#N/ A。
24、对文本数据使用MATCH无论文本如何排序,MATCH都可以处理文本。
25、公式5:= MATCH(“ x”,Test,0) [结果= 5]
26、到这个时候,应该就不足为奇了。该公式搜索“ x”,并告诉我们它是列表中的第五项。
27、公式6:= MATCH(“ m”,Test,0) [结果=#N/ A]
28、在这里,我们正在搜索不在列表中的项目,并且MATCH可靠地为我们提供了#N/ A值。
29、仅出于特定原因使用此match_type,并且始终对数据以升序排序。如果数据不是按升序排列,则MATCH有时会返回错误的结果或错误的#N/ A值。
30、匹配类型为1的升序数据使用match_type为1的一个常见原因是与价格折扣表一起使用,我将在本系列的第3部分中向您展示。
31、公式7:= MATCH(4,Test,1) [结果= 2]
32、当您的数据正确排序时,使用match_type为1会给您可靠的正确结果。
33、公式8:= MATCH(3,Test,1) [结果= 1]
34、这是一种记住MATCH在搜索表中未包含的数据时如何工作的方法:MATCH查找下一个最大值,然后备份一个位置。
35、对文本数据使用MATCH公式9:= MATCH(“ m”,Test,1) [结果= 3]
36、即使文本正确排序,我也无法想到为什么您会对文本使用match_type为1的原因。例如,在公式9中,我们搜索“ m”,MATCH(正确!)返回“ f”的位置。
37、您只能将此类型用于按降序排序的数据...这是我从未发现过的理由。
38、但是,如果您确实需要查找以降序排列的数据,则MATCH是与MATCH功能配合使用的数据降序排列您唯一的选择。VLOOKUP或LOOKUP都不提供该功能。
39、公式10:= MATCH(6,Test,-1) [结果= 2]
40、公式11:= MATCH(3,Test,-1) [结果= 4]
41、如果列表中不存在lookup_value,则match_type为-1的MATCH返回大于或等于lookup_value的最小值的位置。也就是说,它找到小于lookup_value的第一个值,然后备份一个位置。
三、index和match函数怎么用
index(r,n)是一个索引函数,在区域r内,返回第n个单元格的值;
match(a,r,t)是一个匹配函数,t为0时,返回区域r内与a值精确匹配的单元格顺序位置;t为1时返回区域r内与a值最接近的单元格顺序位置(汉字通常按拼音字母比较,数字按值比较,数值符号按位值比较)。
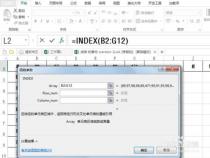
语法:INDEX(array, row_num, [column_num])
返回表格或数组中的元素值,此元素由行号和列号的索引值给定。当函数 INDEX的第一个参数为数组常量时,使用数组形式。
语法:INDEX(reference, row_num, [column_num], [area_num])
返回指定的行与列交叉处的单元格引用。如果引用由不连续的选定区域组成,可以选择某一选定区域。