DOM对象、javascript,jQuery的关系是什么
发布时间:2025-05-23 15:41:42 发布人:远客网络
一、DOM对象、javascript,jQuery的关系是什么
1、jQuery与JavaScript的关系,是基于JavaScript的框架,提供了一组封装的函数集合,简化了JavaScript的使用,使得前端开发更为便捷。
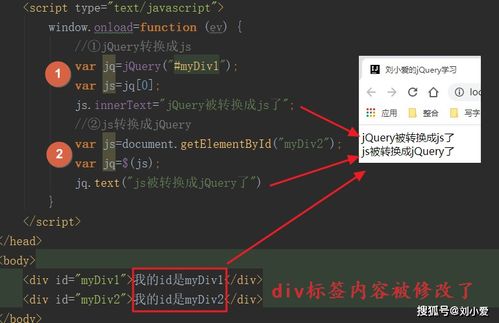
2、jQuery对象与DOM对象,是两个不同的概念。DOM对象是通过传统的JavaScript方法获取的,而jQuery对象则是利用jQuery类库的选择器获取的。
3、jQuery对象是由DOM对象通过jQuery包装后产生的,具备了jQuery特有的方法,例如$("#id").html()用于获取或设置元素的HTML内容,而不能使用DOM对象的方法,如innerHTML或checked。
4、在jQuery对象与DOM对象之间的转换,jQuery提供了简单的方法。将jQuery对象转换为DOM对象,可通过[index]或get(index)实现,因jQuery对象实际上是一个数组。而将DOM对象转换为jQuery对象,则只需调用$()函数包装DOM对象,即可获得jQuery对象。
5、在实际开发中,jQuery对象和DOM对象的转换为开发者提供了更多的灵活性。通过合理转换,可以充分利用jQuery和DOM各自的优势,实现更高效和便捷的开发。
6、建议在开发过程中,明确使用jQuery对象和DOM对象的边界,并在变量前加$符号以区分,提高代码可读性和开发效率。
二、为什么说JavaScript中的DOM操作很慢
在浏览器中,DOM和JS的实现,用的并不是同一个“东西”。比如说,我们最熟悉的chrome,JS引擎是V8,而DOM和渲染,靠的是WebCore库。也就是说,DOM和JS是两个独立的个体。
把DOM和JavaScript各自想象成一个岛屿,它们之间用收费桥梁连接。
--《高性能JavaScript》1、添加页面元素,innerHTMLvsDOM方法。
document.getElementById('test').innerHTML='<div>test</div>';
document.getElementById('test').innerHTML='<div>test</div>';
vart=document.createElement('div');
t.appendChild(document.createTextNode('test'));
document.getElementById('test').appendChild(t);
以上分别使用两种方法,向id='test'的元素中添加一个div。之前,大家可能一直被灌输的思想是innerHTML更快一些,真的是这样么?
以上分别使用两种方法,向id='test'的元素中添加一个div。之前,大家可能一直被灌输的思想是innerHTML更快一些,真的是这样么?
还真是,至少在IE中是这样,但在基于webkit的新版浏览器中,使用DOM方法会稍快一些。所以,到底使用哪一种方法,还是应该有点争议的。我个人是喜欢innerHTML,因为用起来更简单。
此外,当需要添加大量相同的元素时,cloneNode比直接创建元素,稍微快一点。
当我们使用document.getElementsByName、document.getElementsByTagName、document.getElementsByClassName、docuemnt.images等方式来获取DOM元素时,我们得到的是一个HTML集合,这个集合始终与底层文档保持连接,每次去获取集合的信息时,都会重复执行一次查询。
vardivs=document.getElementByTagName('div');
for(vari=0;i<divs.length;i++){
document.body.append(document.createElement('div'))
}
如果不去运行,我们可能以为上面的代码会新添加几个div元素在页面中,但实际上,因为每次添加完一个div后,divs.length都会被更新(加一),所以,这个循环永远不会停止。解决办法非常简单
如果不去运行,我们可能以为上面的代码会新添加几个div元素在页面中,但实际上,因为每次添加完一个div后,divs.length都会被更新(加一),所以,这个循环永远不会停止。解决办法非常简单
vardivs=document.getElementByTagName('div');
for(vari=0,len=divs.length;i<len;i++){
document.body.append(document.createElement('div'))
}
另外,HTML集合并不是一个数组,如果我们需要对这个集合进行遍历,可以先把它拷贝进一个数组,这样再遍历的时候,效率更高。
另外,HTML集合并不是一个数组,如果我们需要对这个集合进行遍历,可以先把它拷贝进一个数组,这样再遍历的时候,效率更高。
for(vari=0,a=[],len=coll.length;i<len;i++){
当遍历一个集合时,length属性应被缓存在循环外部,能够避免2.1中的逻辑错误;集合存储在局部变量中,也能够提高效率。此外,当对同一个DOM元素的属性进行访问时,把这个DOM缓存成一个局部变量,是更好的选择。
//只是做演示,真实情况中,当然没有这样的需求
for(vari=0;i<document.getElementsByTagName('div');i++){
name=document.getElementsByTagName('div').nodeName;
name=document.getElementsByTagName('div').nodeType;
varcoll=document.getElementsByTagName('div');
for(vari=0,len=coll.length;i<len;i++){
varcoll=document.getElementsByTagName('div');
for(vari=0,len=coll.length;i<len;i++){
}3、选择器
前面已经提到,document.getElementsByName、document.getElementsByTagName、document.getElementsByClassName、docuemnt.images等方式,获取到的是HTML集合,效率低下;而querySelector以及querySelectorAll与之相比,得到的是一个NodeList,它是一个类数组对象,不会带来HTML集合的问题。而且,这个API在获取元素时,更加方便。唯一的问题,是要考虑目标浏览器是否提供支持。
前面已经提到,document.getElementsByName、document.getElementsByTagName、document.getElementsByClassName、docuemnt.images等方式,获取到的是HTML集合,效率低下;而querySelector以及querySelectorAll与之相比,得到的是一个NodeList,它是一个类数组对象,不会带来HTML集合的问题。而且,这个API在获取元素时,更加方便。唯一的问题,是要考虑目标浏览器是否提供支持。
重绘并不一定导致重排,比如修改某个元素的颜色,只会导致重绘;而重排之后,浏览器需要重新绘制受重排影响的部分。导致重排的原因有:
因为重排和重绘的操作十分昂贵,浏览器会通过队列化修改并批量执行的方式,来进行优化(我的理解是,浏览器通过队列化和批量执行的方式,减少了重绘的次数)。比如:
varbodyStyle=document.body.style;
bodyStyle.color='red';
bodyStyle.color='black';
bodyStyle.color='green';
获取布局的操作,会导致队列刷新,浏览器的优化效果也就没有了。要避免在布局信息改变时,获取下列属性:
获取布局的操作,会导致队列刷新,浏览器的优化效果也就没有了。要避免在布局信息改变时,获取下列属性:
offsetTop,offsetLeft,offsetWidth,offsetHeight;
scrollTop,scrollLeft,scrollWidth,scrollHeight;
clientTop,clientLeft,clientWidth,clientHeight;
getComputedStyle()/currentStyle
建议:不要再修改布局信息的时候,去查询布局信息
varbodyStyle=document.body.style;
if(document.body.currentStyle){
computed=document.body.currentStyle
computed=document.defaultView.getComputedStyle(document.body,'')
bodyStyle.color='red';
bodyStyle.color='green';
bodyStyle.color='red';
bodyStyle.color='green';
tmp=computed.backgroundImage;
修改一个元素的多个style时,一次性修改,而不是多次(虽然多次修改,经过现代浏览器的优化,也只会导致一次重排,但在老旧的浏览器中,仍然会导致多次)。建议:能用css的class解决的,就尽量不用内联样式。
修改一个元素的多个style时,一次性修改,而不是多次(虽然多次修改,经过现代浏览器的优化,也只会导致一次重排,但在老旧的浏览器中,仍然会导致多次)。建议:能用css的class解决的,就尽量不用内联样式。
:hover会降低响应速度,在处理很大的列表时,避免使用。
每绑定一个事件处理器,都是有代价的。如果有大量的元素需要绑定时间,尝试使用事件委托。分三步
document.querySelector('#nav').onclick=function(e){
if(e.target.nodeName=='A'){
多次访问同一DOM,应该用局部变量缓存该DOM
尽可能使用querySelector,而不是使用获取HTML集合的API
使用事件委托,减少绑定事件的数量
更多内容,可以阅读《高性能JavaScript》
以上内容来自:cnblogs,www.cnblogs.com/yepbug/p/5427213.html
三、javascript的dom访问页面元素常见的方法有哪些
(1) document.getElementById(elementId):该方法通过节点的ID,可以准确获得需要的元素,是比较简单快捷的方法。如果页面上含有多个相同id的节点,那么只返回第一个节点。
如今,已经出现了如prototype、Mootools等多个JavaScript库,它们提供了更简便的方法:$(id),参数仍然是节点的id。这个方法可以看作是document.getElementById()的另外一种写法,不过$()的功能更为强大,具体用法可以参考它们各自的API文档。
(2)document.getElementsByName(elementName):该方法是通过节点的name获取节点,从名字可以看出,这个方法返回的不是一个节点元素,而是具有同样名称的节点数组。然后,我们可以通过要获取节点的某个属性来循环判断是否为需要的节点。
例如:在HTML中checkbox和radio都是通过相同的name属性值,来标识一个组内的元素。如果我们现在要获取被选中的元素,首先获取改组元素,然后循环判断是节点的checked属性值是否为true即可。
(3)document.getElementsByTagName(tagName):该方法是通过节点的Tag获取节点,同样该方法也是返回一个数组,例如:document.getElementsByTagName('A')将会返回页面上所有超链接节点。在获取节点之前,一般都是知道节点的类型的,所以使用该方法比较简单。但是缺点也是显而易见,那就是返回的数组可能十分庞大,这样就会浪费很多时间。那么,这个方法是不是就没有用处了呢?当然不是,这个方法和上面的两个不同,它不是document节点的专有方法,还可以应用其他的节点,下面将会提到。
(1)parentObj.firstChild:如果节点为已知节点(parentObj)的第一个子节点就可以使用这个方法。这个属性是可以递归使用的,也就是支持parentObj.firstChild.firstChild.firstChild...的形式,如此就可以获得更深层次的节点。
(2)parentObj.lastChild:很显然,这个属性是获取已知节点(parentObj)的最后一个子节点。与firstChild一样,它也可以递归使用。
在使用中,如果我们把二者结合起来,那么将会达到更加令人兴奋的效果,即:parentObj.firstChild.lastChild.lastChild...
(3)parentObj.childNodes:获取已知节点的子节点数组,然后可以通过循环或者索引找到需要的节点。
注意:经测试发现,在IE7上获取的是直接子节点的数组,而在Firefox2.0.0.11上获取的是所有子节点即包括子节点的子节点。
(4)parentObj.children:获取已知节点的直接子节点数组。
注意:经测试,在IE7上,和childNodes效果一样,而Firefox2.0.0.11不支持。这也是为什么我要使用和其他方法不同样式的原因。因此不建议使用。
(5)parentObj.getElementsByTagName(tagName):使用方法不再赘述,它返回已知节点的所有子节点中类型为指定值的子节点数组。例如:parentObj.getElementsByTagName('A')返回已知的子节点中的所有超链接。
(1)neighbourNode.previousSibling:获取已知节点(neighbourNode)的前一个节点,这个属性和前面的firstChild、lastChild一样都似乎可以递归使用的。
(2)neighbourNode.nextSibling:获取已知节点(neighbourNode)的下一个节点,同样支持递归。
(1)childNode.parentNode:获取已知节点的父节点。
上面提到的方法,只是一些基本的方法,如果使用了Prototype等JavaScript库,可能还获得其他不同的方法,例如通过节点的class获取等等。不过,如果能够灵活运用上面的各种方法,相信应该可以应付大部分的程序。
【注意】这是转载的文档:其中通过firstChild和lastChild获得HTML Node是不可取的。因为,根据浏览器的不同,firstChild有可能返回parentObj的属性对象。