R-数据处理 丨 正则表达式
发布时间:2025-05-22 01:44:56 发布人:远客网络
一、R-数据处理 | 正则表达式
1、Web内容主要为无结构文本,网络抓取的关键在于从文本数据中提取与研究相关的信息。此过程通常包括三个步骤:收集无结构文本、识别信息背后的规律以及应用规律提取信息。以HTML网页为例,理论上可以通过XPath提取关键数据,但某些关键信息可能隐藏在网页深层或分布于各部分,使网页结构分析方法失效。此时,正则表达式成为分析文本中规律的强大工具。
2、正则表达式是一种描述字符串集合的模式,分为扩展基本正则表达式和Perl正则表达式两种类型。R语言中主要使用的是扩展基本正则表达式。
3、正则表达式主要用于匹配和提取文本中的特定模式。在R中,主要通过`stringr`包中的`str_extract`和`str_extract_all`函数实现。`str_extract`函数用于在一个字符串中查找第一个与正则表达式匹配的实例,而`str_extract_all`则可以对多个字符串进行操作,返回所有匹配结果。
4、例如,对于一个包含多个字符串的向量,使用`str_extract_all`函数可以提取所有匹配的结果。函数的输出通常是一个列表,每个列表元素对应一个字符串的结果。如果结果列表长度为1(即输入字符串长度为1),可以通过`unlist`函数解析。此外,还可以通过设置参数`simplify`为`TRUE`,将结果转换为矩阵形式。
5、正则表达式不仅用于匹配单词,还可以匹配任意字符序列。特定符号如`^`和`$`用于标记字符串的开始和结束,而`|`表示“或”操作,使正则表达式能够匹配多个可能的模式。
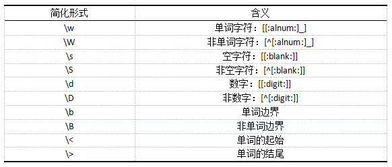
6、在字符序列中,可以通过特定符号如`-`在字符范围内匹配特定字符,如`a-g`表示匹配从a到g的任意字符。此外,正则表达式可以包含数字、标点符号和空格,R中预定义了一些常用的字符类,如`\w`匹配单词字符,`\b`匹配单词边界。
7、通过在字符类前加入`^`,可以反转字符类的匹配规则,使其匹配除该字符类包含字符之外的所有字符。在字符类中使用 `{n}`表示重复特定字符 n次,如 `a{4}`表示匹配连续4个字符a。加号(+)表示匹配前面条目至少一次,如 `A.+sentence`可以提取以A开头,以sentence结尾的序列。
8、R语言默认采用贪婪量化模式,即尽可能匹配最大合法序列。如果希望匹配最短序列,可以通过添加`?`来表示可选匹配,最多匹配一次。
9、元字符如`.;|;(); [];{}; ^;$;*;+;?;-`在正则表达式中具有特殊含义。为了在字符串中匹配这些元字符,可以使用双斜杠或`fixed()`函数进行转义。
10、正则表达式的应用包括反向引用(backreferencing),即在匹配模式中引用之前匹配的子字符串。例如,`[[:alpha:]]+.+?\1`表示在匹配出的字符下一次出现时进行引用。
11、实例:提取电话目录中的人名和号码。人名模式中包含字母、句点、逗号和空格,可使用`[[:alpha:.], ]`表示。号码提取需要分析号码的组成,包括区号、括号、破折号和数字等。
12、通过这些方法,正则表达式为从复杂文本数据中提取信息提供了强大而灵活的工具。
二、正则表达式(stringr包)
1、 stringr包里面的函数主要分为 6大类,包括:
2、接下来,我们将逐个演示这些函数的使用方法。
3、 str_detect可以检测pattern是否包括在某个字符串中,并返回TRUE和FALSE
4、 str_count检测pattern是否包括在某个字符串中的数目
5、 str_which告诉pattern的索引位置
6、 str_locate和 str_locate_all返回pattern的开始和终止位置;
7、区别是 str_locate只返回字符串里面的首个匹配到的pattern;
8、 str_locate_all返回字符串里面的所有匹配到的pattern;
9、 str_view和 str_view_all函数都可以以可视化的方式,返回字符串中匹配到的pattern;
10、 str_sub在给定起始和终止参数的基础上对字符串进行截取或者替换
11、 str_subset返回pattern所在的字符串
12、 str_extract函数返回每个字符串中首个匹配到的pattern
13、 str_extract_all函数返回每个字符串中所有匹配到的pattern str_extract_all函数中 simplify默认为False,默认返回list;当 simplify为True,则返回matrix
14、 str_match函数返回每个字符串中首个匹配到的pattern,以matrix的形式呈现
15、 str_match_all函数返回每个字符串中所有匹配到的pattern,以list的形式呈现
16、 str_length函数可以计算字符串的长度
17、 str_trim函数去除字符串的空白部分
18、 str_squish函数作用和 str_trim函数作用一致,但除了去除字符串前、后的空格,它还可以去除字符串中间出现的重复的空格。这一点上, str_trim函数无法办到。
19、 str_trunc函数可以把字符串切割到指定长度
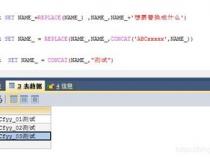
20、 str_replace函数可以替换pattern为新的字符,仅限于第一个匹配到的
21、 str_replace_all函数可以替换所有匹配到的pattern
22、 str_replace_na可以将缺失值替换成‘NA’,这样na.omit函数就无法将缺失值删除了
23、在 str_replace和 str_replace_all函数中,replacement可以用\1, \2中表示模式中的捕获
24、 str_to_upper函数可以将小写字母转成大写字母
25、 str_to_lower函数可以将大写字母转成小写字母
26、 str_remove可以移除字符串中首个匹配到的pattern
27、 str_remove_all可以移除字符串中所有匹配到的pattern
28、 str_split按照pattern分割字符串
29、 str_split_fixed按照pattern将字符串分割成指定个数
30、 str_order函数和 str_sort函数都可以对字符串进行排序,两者之前的区别在于前者返回排序后的索引(下标),而后者返回排序后的实际值。
31、原来是它!正则表达式揪出生信分析中没有报错的内鬼错误
三、r语言表示或者用什么符号
1、R语言中用于表示字符串的符号有两种选择:单引号和双引号。例如,可以写成'hello'或"world"。尽管在R语言中这两种符号都可以用来定义字符串,但并没有严格的规则要求必须使用某一种。这种选择性很大程度上取决于个人的偏好或者团队内部的编码规范。
2、除了使用单引号和双引号来定义字符串之外,R语言还提供了一些特殊的符号,用于表示特定的数据类型或执行特定的操作。比如,$用于从数据框中提取变量;而%in%则用来判断某个元素是否存在于某个向量中。这些符号可以根据具体的应用场景灵活使用。
3、值得注意的是,虽然R语言中的字符串可以用单引号或双引号表示,但当字符串中包含引号本身时,使用另一类引号会更加方便。例如,如果字符串内容包含双引号,则使用单引号定义字符串会更简单,反之亦然。
4、尽管R语言提供了这些特殊符号,用户还是需要根据具体需求来选择合适的符号。例如,当处理涉及到变量名称的字符串时,使用$符号会非常方便;而在需要进行复杂的模式匹配或者正则表达式操作时,可以使用%%或者%*%等符号。