浅谈时序数据库TDengine
发布时间:2025-05-24 06:19:27 发布人:远客网络
一、浅谈时序数据库TDengine
1、近期,时序数据库TDengine备受瞩目,尽管官方测试表现优异,但在使用过程中,我发现存在一些挑战。首要问题在于写入策略,设计中要求用户为每个Tag组合自定义表名,虽然初衷是将同类数据聚合,但这种操作实际上增加了用户的负担。如果系统内部能自动处理Tag唯一性,通过内部隐藏的表名,用户只需操作一个超级表STable,将简化操作,提升写入性能。
2、不支持乱序写入是TDengine的一个局限,它牺牲了一定的灵活性,以保证写入性能。例如,数据写入时需要保持时间顺序,否则可能导致复杂的数据调整。这不仅影响了写入效率,还省去了类似RocksDB的compact操作,减少了查询时的数据量。因此,用户在使用时需要遵循特定的写入规则,以保证性能。
3、查询方面,对于常见的需求如topN group,例如查询CPU利用率最高的三台机器,TDengine目前无法满足。此外,对于每个appId的总连接数曲线,通过downsampling和aggregation来聚合数据时,TDengine的SQL功能受限,无法处理复杂的函数嵌套,这也成为了一个痛点。
4、在group by操作中,比如依据host和disk进行分组,当数据量庞大,如30万个表时,TDengine的性能将大打折扣。查询过程需先获取大量表的meta信息,然后逐个表查询,这在数据节点众多时会成为瓶颈。
5、查询聚合架构方面,两阶段查询方式可能导致效率问题,尤其是当满足条件的表超过百万时。这促使我们考虑使用分布式查询方案,如Presto或Impala,以解决客户端聚合的性能瓶颈。
二、数据库-涛思-TDengine
数据库-涛思-TDengine的直观概述
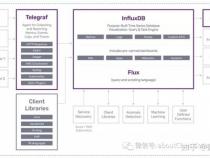
在探索时序数据库领域时,我曾接触过Influxdb和OpenTSDB,而现在又遇到了一个新兴平台——涛思数据的开源大数据处理平台TDengine。专为物联网、车联网等场景设计,TDengine以其出色的高效性能和全面的功能脱颖而出。它不仅拥有核心的时序数据库功能,速度比传统数据库快10倍以上,还提供了缓存、数据订阅和流式计算等功能,旨在简化研发和运维工作,且所有核心代码和集群功能均开源。
官网的介绍中,包含了一系列关键特性,值得深入研究。首先,从容器化部署开始,包括下载镜像、运行容器、输入初始样例数据,如在35.68秒内成功插入1亿条数据,每秒处理速度达到280万条,显示出其高效性能。接着,通过查询数据和访问REST接口,体验了其数据库操作的便捷性。
在初步体验中,我观察到TDengine的操作模式与MySQL类似,但后续仍需深入研究其时序数据库、缓存、数据订阅和流式计算等功能,以全面了解其优势。毕竟,周五到了,是时候享受一下其他兴趣爱好,比如玩一局太华。不过,周末我将继续研究,期待发现更多亮点。
三、clickhouse可以替代tdengine的
题主是否想询问“clickhouse可以替代tdengine的什么?”clickhouse可以替代tdengine的部分功能。根据查询相关信息显示,clickhouse可以替代tdengine并非完全替代。ClickHouse和TDengine都是高性能的时序数据库,但设计和使用场景略有不同。ClickHouse是一种OLAP(联机分析处理)数据库,适用于大量数据的分析和查询。支持复杂的查询和聚合操作,可以快速处理海量数据。但是,在写入数据的速度方面,ClickHouse相对较慢,因此不适合需要实时处理大量数据的场景。