StarRocks数据库FE——Catalog层
发布时间:2025-05-22 22:54:15 发布人:远客网络
一、StarRocks数据库FE——Catalog层
1、StarRocks数据库FE的Catalog层,实质上是通过MPP数据库架构的可扩展性,实现与外部存储的无缝对接,形成“仓外挂湖”的存储模式。这种设计旨在增强存储能力,提升查询性能,支持多种类型存储和多引擎兼容。核心挑战包括元数据管理的统一、存储的开放性、查询引擎的扩展、存算分离架构以及弹性伸缩能力。具体来说:
2、元数据管理:StarRocks通过统一Catalog,整合不同数据系统的元数据,支持跨库分析和数据共享,实现数据在不同平台间的透明流动,特别能管理外部存储如Hadoop和对象存储的元数据。
3、存储开放性:StarRocks支持多种存储介质,包括非自身存储格式,如Hudi、Iceberg、Delta Lake等开放格式,以及Parquet、ORC、CSV等标准格式,确保兼容性和数据格式的多样性。
4、扩展查询引擎:在保留原有MPP计算能力的基础上,引入批处理和实时数据处理能力,以提升性能和适应不同数据处理需求。
5、存算分离:与传统MPP架构分离,StarRocks采用云原生存算分离设计,以适应现代大数据环境的灵活性和扩展性。
6、弹性伸缩:借助K8S和Docker等技术,实现计算层和存储层的容器化管理,支持自动根据业务负载动态调整资源。
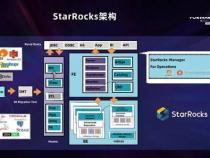
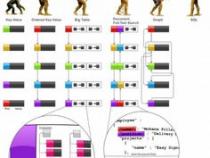
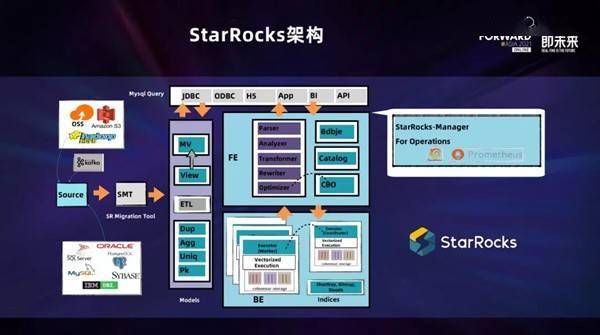
7、在内部,StarRocks提供Internal Catalog管理和External Catalog连接外部元数据的功能。Internal Catalog负责内部数据的管理,而External Catalog则允许用户直接查询外部数据源,如Hive、Iceberg等。Catalog类作为内存中管理这些元数据的中心,通过CatalogMgr管理和维护Catalog对象,包括CatalogName与Catalog对象的映射,以及外部元数据连接器的管理。通过一系列创建和加载Catalog的流程,StarRocks实现了高效且统一的元数据处理和数据访问。
二、1.StarRocks简介
1、StarRocks是新一代的全场景MPP数据库,它融合了关系型OLAP数据库和分布式存储系统的优势,通过优化升级和新增功能,打造了一款企业级的高性能数据库产品。其目标是提供统一且快速的分析体验,支持多种数据模型(明细、聚合和更新),导入方式多样,能无缝连接Spark、Flink、Hive等现有系统,并兼容MySQL协议,方便用户使用常见的BI工具进行数据分析。
2、StarRocks适用于多种企业级分析场景,包括OLAP多维分析(如用户行为分析、财务报表)、实时数据处理(如电商分析、物流监控)、高并发查询(如广告主表分析)以及统一分析,以简化系统复杂度和降低开发成本。它采用分布式架构,可扩展至10PB级别,支持MPP并行计算,具有副本机制以保证高可用性和弹性容错。
3、在StarRocks中,FE(前端节点)负责处理客户端连接、元数据管理、查询调度等任务,BE(后端节点)则负责数据存储和计算,还通过Broker服务实现外部数据接入。管理工具如StarRocksManager提供集群管理与监控功能。数据以表格形式存储,每个表划分为多个Tablet,分布在BE节点上,具有列式存储和高效的查询性能优化,如列式编码、压缩和向量化执行。
4、在表设计方面,StarRocks采用列式存储,通过稀疏索引和预聚合等技术提升数据处理速度。根据业务需求,支持四种数据模型:明细模型、聚合模型、更新模型和主键模型,以适应不同场景下的数据管理。
三、《StarRocks官方文档》
1、StarRocks是一个专门用于处理海量数据高速查询的数据库系统,兼容 MySQL协议,能实现与多种大数据组件的对接。其架构由前端节点(FE)和后端节点(BE)组成,类似于 Spark集群的 master-slave架构,无需用户直接关注其内部部署细节。
2、StarRocks的表设计是其性能优势的核心,它在建表语句中引入了特定的关键字声明,并支持四种不同的数据模型以适应不同查询需求。这四种模型包括明细模型、聚合模型、更新模型和主键模型,每种模型均有其特定用途,比如明细模型适合于需要保留数据原始粒度的场景,聚合模型则适用于统计和汇总数据,更新模型适合频繁更新的场景,而主键模型支持完整的更新和删除操作。合理选择数据模型能显著提升查询性能。
3、数据分布是优化 StarRocks性能的关键,合理的数据分布策略能减少数据扫描量,提高集群并发性能。常见的数据分布方式包括哈希分布等。排序键和前缀索引则能进一步优化数据查询效率,通过在写入数据前先按排序键排序,查询时无需全表扫描。
4、StarRocks支持多种数据导入和导出方式,便于与 HDFS、Spark、Flink等系统集成。其优化策略包括 CBO(成本基优化器)、物化视图和 Colocate Join等高级功能,但具体实现细节在使用过程中需深入了解。
5、用户在实际应用中,主要关注如何根据具体需求选择合适的数据模型、合理设计表结构、利用数据分布策略提高查询性能,以及在数据导入与导出过程中选择合适的工具和方法。StarRocks的强大功能为大数据分析提供了有力的支持,用户在学习和使用过程中,应根据具体应用场景灵活运用其特性和功能。