js字符串最多存储多少字节
发布时间:2025-05-20 11:20:29 发布人:远客网络
一、js字符串最多存储多少字节
JavaScript字符串长度受下标限制,理论上最大值为2^53-1,相当于大约9PB的数据量,远超中国自甲骨文以来所有出版物字数总和。
实际引擎与电脑硬件限制意味着字符串无法达到如此大尺寸。V8引擎的堆上限约为2GB,单个字符串最大分配大小约为512MB,FF浏览器的限制大致相同。UTF16编码下,这意味着最多可存储约2.68亿字符。
对比现有数据,2000万字的网络小说对于JavaScript字符串而言绰绰有余,甚至《道藏》7000万字,《大藏经》1亿字的容量也足够。但《永乐大典》3.7亿字,《四库全书》8亿字的超大规模则超出JavaScript字符串的存储能力。
值得一提的是,IE11浏览器似乎能存储多达4GB的字符串,即21亿字,显著扩展了字符串的存储上限。
二、js判断字符串长度的5个方法(区分中文和英文)
这是最基本的方法,可以直接使用JavaScript的内置属性length来获取字符串的长度。无论中英文,该方法都会计算字符的实际长度。
由于中文和英文字符在Unicode编码中的范围不同,可以通过检查字符的Unicode编码范围来判断其是中文还是英文,并据此计算长度。
通过正则表达式可以匹配中文字符和英文字符,分别计算它们的数量,从而得到字符串的总长度。
中文和英文字符的字符编码不同,可以通过检测字符的编码来判断其类型,并计算长度。
根据字符所属的字符集来判断字符是中文还是英文,并计算字符串的长度。
这是最直接和简单的方法。JavaScript中的字符串对象有一个length属性,它返回字符串中的字符数。这个方法会将中英文都视为一个字符来计算长度。对于开发者来说,这是获取字符串长度的首选方式。
由于Unicode编码将不同语言的字符都赋予了独特的编码值范围,我们可以根据字符的Unicode编码范围来判断它是中文还是英文。中文通常在Unicode中的范围较大,英文则有自己的特定范围。根据这个特性可以区分中英文并计算长度。
正则表达式提供了强大的字符串匹配功能。我们可以创建一个匹配中文的正则表达式和一个匹配英文的正则表达式,然后使用它们来分别匹配字符串中的中文和英文字符,最后统计匹配到的次数即为各自的长度。此方法需要对正则表达式的使用有一定的了解。
字符编码也是区分中英文的一个有效方式。不同的字符有不同的编码值,我们可以根据这个编码值来判断字符的类型并计算长度。例如,常见的UTF-8编码中,英文字符通常占用一个字节,而中文字符则占用多个字节。根据这个特性可以判断字符的长度。但需要注意的是,这种方式可能受到编码环境的影响。
字符集如UTF-8、ASCII等定义了不同字符的编码规则。我们可以根据字符所属的字符集来判断它是中文还是英文。在UTF-8编码中,英文通常使用单字节表示,而中文字符则使用多字节表示。通过识别字符集的差异可以计算字符串的长度。但这种方法同样需要注意编码环境的影响。同时,现代的JavaScript环境对UTF-8的支持较好,通常不需要手动处理字符集问题。
三、js 字符串转数字
很多朋友都想知道js字符串转数字有哪些方法?下面就一起了解一下吧~
js字符串转数字的方法主要有三种:转换函数、强制类型转换、利用js变量弱类型转换。
js提供了parseInt()和parseFloat()两个转换函数。前者把值转换成整数,后者把值转换成浮点数。只有对String类型调用这些方法,这两个函数才能正确运行;对其他类型返回的都是NaN(Not a Number)。
parseInt("1234blue"); //returns 1234 parseInt("0xA"); //returns 10 parseInt("22.5"); //returns 22 parseInt("blue"); //returns NaN
parseInt()方法还有基模式,可以把二进制、八进制、十六进制或其他任何进制的字符串转换成整数。基是由parseInt()方法的第二个参数指定的,示例如下:
parseInt("AF", 16); //returns 175 parseInt("10", 2); //returns 2 parseInt("10", 8); //returns 8 parseInt("10", 10); //returns 10
如果十进制数包含前导0,那么最好采用基数10,这样才不会意外地得到八进制的值。例如:
parseInt("010"); //returns 8 parseInt("010", 8); //returns 8 parseInt("010", 10); //returns 10
parseFloat()方法与parseInt()方法的处理方式相似。
使用parseFloat()方法的另一不同之处在于,字符串必须以十进制形式表示浮点数,parseFloat()没有基模式。
下面是使用parseFloat()方法的示例:
parseFloat("1234blue"); //returns 1234.0 parseFloat("0xA"); //returns NaN parseFloat("22.5"); //returns 22.5 parseFloat("22.34.5"); //returns 22.34 parseFloat("0908"); //returns 908 parseFloat("blue"); //returns NaN
使用强制类型转换(type casting)处理转换值的类型。使用强制类型转换可以访问特定的值,即使它是另一种类型的。
ECMAScript中可用的3种强制类型转换如下:
Boolean(value)——把给定的值转换成Boolean型;
Number(value)——把给定的值转换成数字(可以是整数或浮点数);
String(value)——把给定的值转换成字符串。
用这三个函数之一转换值,将创建一个新值,存放由原始值直接转换成的值。这会造成意想不到的后果。
当要转换的值是至少有一个字符的字符串、非0数字或对象(下一节将讨论这一点)时,Boolean()函数将返回true。如果该值是空字符串、数字0、undefined或null,它将返回false。
可以用下面的代码段测试Boolean型的强制类型转换。
Boolean(""); //false – empty string Boolean("hi"); //true – non-empty string Boolean(100); //true – non-zero number Boolean(null); //false - null Boolean(0); //false - zero Boolean(new Object()); //true – object
Number()的强制类型转换与parseInt()和parseFloat()方法的处理方式相似,只是它转换的是整个值,而不是部分值。示例如下:
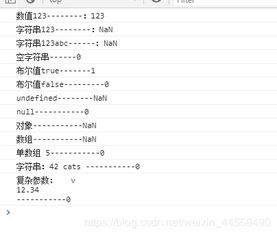
用法 结果
Number(false) 0 Number(true) 1 Number(undefined) NaN Number(null) 0 Number( "5.5 ") 5.5 Number( "56 ") 56 Number( "5.6.7 ") NaN Number(new Object()) NaN Number(100) 100
最后一种强制类型转换方法String()是最简单的,示例如下:
var s1 = String(null); //"null" var oNull = null; var s2 = oNull.toString(); //won’t work, causes an error