Linux shell 中如何从路径名提取指定字符串
发布时间:2025-05-21 14:19:22 发布人:远客网络
一、Linux shell 中如何从路径名提取指定字符串
在Linux shell中,提取路径名中的指定字符串,可以使用cut命令。例如,如果以-作为分隔符,取第二个字段,可以这样做:
echo"/home/lxy/hhhhh-a.bbb.cc.d"| cut-d'-'-f2
然而,为了更安全地处理路径名,可以先提取文件名,再进行处理。具体做法是使用awk命令,先按/分割路径,输出最后一个字段,然后再用cut命令处理:
echo"/home/lxy/hhhhh-a.bbb.cc.d"| awk-F/'{print$NF}'| cut-d'-'-f2
这样做可以避免路径名中包含-符号带来的问题。
此外,还可以使用其他方法来提取字符串,如使用sed命令。例如:
echo"/home/lxy/hhhhh-a.bbb.cc.d"| sed's|.*/||;s|-\.*||'
这条命令首先删除路径中的最后一部分,然后删除-及其后的所有字符。这种方法适用于路径名中包含-的情况。
总结来说,根据路径名的具体情况,可以选择使用cut、awk或sed等命令来提取所需的字符串,确保处理过程的稳定性和正确性。
值得注意的是,这些方法可以根据实际需求进行调整,以适应不同的场景。例如,如果需要提取特定位置的字符串,可以通过改变分隔符和字段号来实现。
在处理路径名时,确保代码的健壮性非常重要。通过采用不同的方法和策略,可以提高脚本的灵活性和可靠性。
此外,还可以结合正则表达式来提取路径中的特定部分。例如:
echo"/home/lxy/hhhhh-a.bbb.cc.d"| sed-n's|.*/\([^/]*\)-[^/]*$|\1|p'
这条命令使用正则表达式匹配并提取路径名中的文件名前部分,即-a.bbb.cc.d。
总之,Linux shell提供了多种工具和方法来处理路径名中的字符串提取任务,可以根据具体需求灵活选择和应用。
二、Linux的shell编程中,如何将一段字符串进行截取
在Linux的shell编程中,截取字符串是一项常见的任务。通常,我们会使用多种工具和方法来实现这一目标。比如,使用grep命令,虽然它主要用于文本搜索,但也可以结合正则表达式来截取特定的字符串片段。当然,awk是一个更为强大的工具,它不仅可以处理字符串,还能进行复杂的文本分析和处理。
假设我们需要从一个字符串中截取某些特定的部分,例如,从一个包含电子邮件地址的字符串中提取用户名部分。可以使用如下命令:
首先,使用grep结合正则表达式来查找电子邮件地址:
grep-oE'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}' email.txt
这里,grep会输出所有匹配的电子邮件地址。接下来,我们可以用awk进一步处理,只提取用户名部分:
grep-oE'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}' email.txt| awk-F'@''{print$1}'
上述命令中,-F'@'指定了分隔符为'@',awk会将字符串按照指定分隔符分割,并打印出第一部分,即用户名。
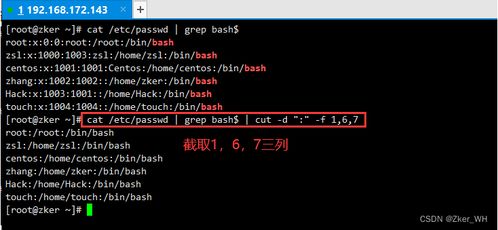
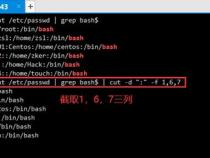
除了grep和awk,还有一些其他的方法可以用来截取字符串,如cut命令和sed工具。例如,使用cut命令可以根据字段号或分隔符来截取字符串:
echo"username@example.com"| cut-d'@'-f1
这里,-d指定分隔符为'@',-f1指定输出第一字段,即用户名。
总结来说,在Linux shell编程中,截取字符串可以根据具体需求选择合适的工具。无论是使用grep结合正则表达式,还是使用awk、cut或sed,都有其适用场景和优势。选择合适的工具和方法可以大大提高工作效率。
值得注意的是,这些命令的使用需要对正则表达式有一定的了解,以确保能够准确地匹配和处理字符串。通过不断练习和实践,可以更好地掌握这些工具的用法。
此外,对于较为复杂的字符串处理任务,可以编写shell脚本来自动化处理流程,提高处理效率和准确性。
总之,掌握如何在Linux shell编程中截取字符串是一项重要的技能,它能够帮助你更高效地处理各种文本数据。
三、linux c语言 sscanf提取字符串中的数字乱码
1、在处理字符串时,有时需要从中提取数字。这里展示了一个使用sscanf函数的C语言示例,该函数可以从字符串中提取数字并将其存储在变量中。具体来说,代码中使用了两次sscanf函数,分别提取整数和浮点数。
2、第一次调用sscanf(cmt,"%*[^0-9]%[0-9]",imt);,其中cmt是源字符串,imt是用于存储提取的整数的变量。这个表达式的含义是忽略字符串中所有非数字字符,并从第一个数字开始提取整数,直到遇到非数字字符为止。这样,sscanf将忽略掉cmt中非数字的部分,只提取整数并赋值给imt。
3、第二次调用sscanf(cmt,"%*[^0-9]%[0-9]",imf);,其中imf是用于存储提取的浮点数的变量。同样地,该表达式首先忽略掉字符串中的非数字字符,然后提取紧跟其后的所有数字字符,形成一个浮点数,赋值给imf。
4、需要注意的是,这里的“%*[^0-9]”部分是用于跳过非数字字符的,而“%[0-9]”部分则用于提取数字。通过这种方式,我们可以有效地从字符串中提取出所需的数字信息,无论是整数还是浮点数。
5、然而,使用sscanf时也需要注意一些潜在的问题,比如输入字符串不符合预期格式可能会导致意外的结果。因此,在实际应用中,应该对输入进行适当的验证和处理,以确保程序的健壮性和正确性。
6、此外,对于更复杂的数据提取需求,可以考虑使用正则表达式或其他更强大的字符串处理方法。这将使得代码更加清晰和易于维护。
7、综上所述,sscanf是一个强大的工具,可以用于从字符串中提取数字信息。通过合理地使用其格式字符串,我们可以实现高效的字符串解析,但同时也需要关注潜在的问题和限制,以确保程序的可靠运行。




![正则表达式(r[0-9]){3}匹配哪些字符串](/d/file/2025-05-21/small228d62e92fc397baa710721093854383.jpg)