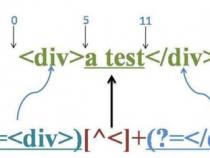
正则表达式(r[0-9]){3}匹配哪些字符串
发布时间:2025-05-21 05:16:57 发布人:远客网络
![正则表达式(r[0-9]){3}匹配哪些字符串](/d/file/2025-05-21/778903cf26ba623fcb38759b881179ad.jpg)
一、正则表达式(r[0-9]){3}匹配哪些字符串
假定您写的这个正则表达式语法上正确,那么有一个小问题:()代表一个子表达式,()本身不匹配任何东西,也不限制匹配任何东西,只是把括号里的东西作为同一个表达式来处理,例如(ab){1,3}这个正则表达式,指的是ab一起连续出现最少1次、最多3次;如果去掉括号就是ab{1,3},指的是a后面紧跟的b出现最少1次,最多3次。
所以您给出的正则表示里的(3),完全可以去掉括号,那整个正则就简化成r[0-9]3了。然后再分析语法:
[0-9]:匹配0到9之间、包含0和9的任意一个数字
于是,整个r[0-9]3的正则表达式能匹配的所有字符串就是:r03、r13、r23、r33、r43、r53、r63、r73、r83、r93。
更多关于正则表达式的入门知识,请参考《菜鸟教程的正则表达式》一章。
二、R-数据处理 | 正则表达式
1、Web内容主要为无结构文本,网络抓取的关键在于从文本数据中提取与研究相关的信息。此过程通常包括三个步骤:收集无结构文本、识别信息背后的规律以及应用规律提取信息。以HTML网页为例,理论上可以通过XPath提取关键数据,但某些关键信息可能隐藏在网页深层或分布于各部分,使网页结构分析方法失效。此时,正则表达式成为分析文本中规律的强大工具。
2、正则表达式是一种描述字符串集合的模式,分为扩展基本正则表达式和Perl正则表达式两种类型。R语言中主要使用的是扩展基本正则表达式。
3、正则表达式主要用于匹配和提取文本中的特定模式。在R中,主要通过`stringr`包中的`str_extract`和`str_extract_all`函数实现。`str_extract`函数用于在一个字符串中查找第一个与正则表达式匹配的实例,而`str_extract_all`则可以对多个字符串进行操作,返回所有匹配结果。
4、例如,对于一个包含多个字符串的向量,使用`str_extract_all`函数可以提取所有匹配的结果。函数的输出通常是一个列表,每个列表元素对应一个字符串的结果。如果结果列表长度为1(即输入字符串长度为1),可以通过`unlist`函数解析。此外,还可以通过设置参数`simplify`为`TRUE`,将结果转换为矩阵形式。
5、正则表达式不仅用于匹配单词,还可以匹配任意字符序列。特定符号如`^`和`$`用于标记字符串的开始和结束,而`|`表示“或”操作,使正则表达式能够匹配多个可能的模式。
6、在字符序列中,可以通过特定符号如`-`在字符范围内匹配特定字符,如`a-g`表示匹配从a到g的任意字符。此外,正则表达式可以包含数字、标点符号和空格,R中预定义了一些常用的字符类,如`\w`匹配单词字符,`\b`匹配单词边界。
7、通过在字符类前加入`^`,可以反转字符类的匹配规则,使其匹配除该字符类包含字符之外的所有字符。在字符类中使用 `{n}`表示重复特定字符 n次,如 `a{4}`表示匹配连续4个字符a。加号(+)表示匹配前面条目至少一次,如 `A.+sentence`可以提取以A开头,以sentence结尾的序列。
8、R语言默认采用贪婪量化模式,即尽可能匹配最大合法序列。如果希望匹配最短序列,可以通过添加`?`来表示可选匹配,最多匹配一次。
9、元字符如`.;|;(); [];{}; ^;$;*;+;?;-`在正则表达式中具有特殊含义。为了在字符串中匹配这些元字符,可以使用双斜杠或`fixed()`函数进行转义。
10、正则表达式的应用包括反向引用(backreferencing),即在匹配模式中引用之前匹配的子字符串。例如,`[[:alpha:]]+.+?\1`表示在匹配出的字符下一次出现时进行引用。
11、实例:提取电话目录中的人名和号码。人名模式中包含字母、句点、逗号和空格,可使用`[[:alpha:.], ]`表示。号码提取需要分析号码的组成,包括区号、括号、破折号和数字等。
12、通过这些方法,正则表达式为从复杂文本数据中提取信息提供了强大而灵活的工具。
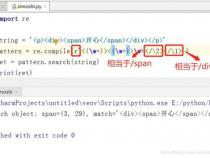
三、正则表达式中的\ r\ n的用法是什么
1、最前面的“/”与最后面的“/”是分隔符,表示正则表达式的开始与结束。
2、最后的“g”标志则表示正则表达式使用的global(全局)的状态。使用 global标志表明在被查找的字符串中搜索操作将查找所有符合的项,而不仅仅是第一个。这也被称为全局匹配。【相关的标志还有i(ignoreCase,表示忽略大小写)、m(multiline,表示允许跨行)】
3、然后我们再来看中间的主体部分:\{\{(.+?)\}\}花括号{}是正则里的限定符。但是我们这里是要找字符串里的花括号,所以前面加个“\”来表示是要找字符的花括号。“\{\{”“\}\}”就是找前后两组花括号。
4、“.”表示任意字符。“+”表示前面表达式一次乃至多次。“?”表示匹配模式是非贪婪的。
5、/\{\{(.+?)\}\}/g完整的意思就是:在全部范围内查找匹配前后有两组花括号的字符串。
6、例如:“{{}}”、“{{asdfasdfasdf56745}}”、“{{yuyuy#$%8787 9+_)(*)87}}”
7、正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
8、许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
![正则表达式(r[0-9]){3}匹配哪些字符串](/d/file/2025-05-21/small228d62e92fc397baa710721093854383.jpg)