notepad++正则表达式 字符串详解
发布时间:2025-05-21 03:07:58 发布人:远客网络
一、notepad++正则表达式 字符串详解
正则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它能很好提高工作效率。
文本编辑器 Notepad++ v6.3.3绿色多国语言版 点击下载
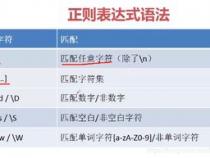
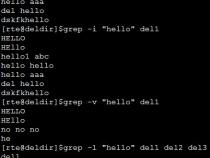
|匹配表达式左边和右边的字符.例如,“ab|bc”匹配“ab”或者“bc”.
[]匹配列表之中的任何单个字符.例如,“[ab]”匹配“a”或者“b”.“[0-9]”匹配任意数字.
[^]匹配列表之外的任何单个字符.例如,“[^ab]”匹配“a”和“b”以外的字符.“[^0-9]”匹配任意非数字字符.
*其左边的字符被匹配任意次(0次,或者多次).例如“be*”匹配“b”,“be”或者“bee”.
+其左边的字符被匹配至少一次(1次,或者多次).例如“be+”匹配“be”或者“bee”但是不匹配“b”.
?其左边的字符被匹配0次或者1次.例如“be?”匹配“b”或者“be”但是不匹配“bee”.
^其右边的表达式被匹配在一行的开始.例如“^A”仅仅匹配以“A”开头的行.
()影响表达式匹配的顺序,并且用作表达式的分组标记.
/转义字符.如果你要使用“/”本身,则应该使用“//”.
【1】正则表达式应用——替换指定内容到行尾
希望每次遇到“abc”,则替换“abc”以及其后到行尾的内容为“abc efg”
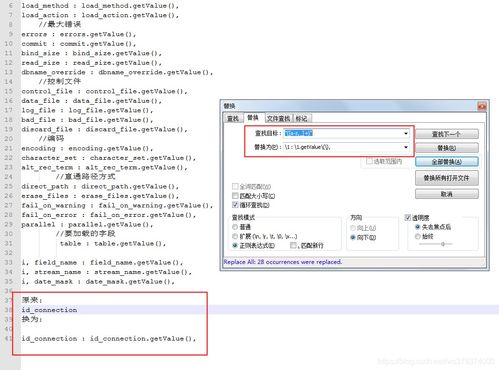
①在替换对话框,查找内容里输入“abc.*”
②同时勾选“正则表达式”复选框,然后点击“全部替换”按钮
注意:其实就是正则表达式替换,这里只是把一些曾经提出的问题加以整理,单纯从正则表达式本身来说,就可以引申出成千上万种特例。
【2】正则表达式应用——数字替换
asdadas123asdasdas456asdasdasd789asdasd
asdadas[123]asdasdas[456]asdasdasd[789]asdasd
在替换对话框里面,勾选“正则表达式”复选框;
在查找内容里面输入“[0-9][0-9][0-9]”,不含引号
“替换为:”里面输入“[/0/1/2]”,不含引号
范围为你所操作的范围,然后选择替换即可。
实际上这也是正则表达式的使用特例,“[0-9]”表示匹配0~9之间的任何特例,同样“[a-z]”就表示匹配a~z之间的任何特例
上面重复使用了“[0-9]”,表示连续出现的三个数字
“/0”代表第一个“[0-9]”对应的原型,“/1”代表第二个“[0-9]”对应的原型,依此类推
“[”、“]”为单纯的字符,表示添加“[”或“]”,如果输入“其它/0/1/2其它”,则替换结果为:
asdadas其它123其它asdasdas其它456其它asdasdasd其它789其它asdasd
如果将查找内容“[0-9][0-9][0-9]”改为“[0-9]*[0-9]”,对应1或 123或 12345或…
相关内容还有很多,可以自己参考正则表达式的语法仔细研究一下
【3】正则表达式应用——删除每一行行尾的指定字符
因为这几个字符在行中也是出现的,所以肯定不能用简单的替换实现
这个也算正则表达式的用法,其实仔细看正则表达式应该比较简单,不过既然有这个问题提出,说明对正则表达式还得有个认识过程,解决方法如下
在替换对话框中,启用“正则表达式”复选框
在查找内容里面输入“345”表示从行尾匹配
如果从行首匹配,可以用“^”来实现,不过 EditPlus有另一个功能可以很简单的删除行首的字符串
c.在弹出对话框里面输入要清除的行首字符,确定
【4】正则表达式应用——替换带有半角括号的多行
几百个网页中都有下面一段代码:
在替换对话框启用“正则表达式”选项,这时就可以完成替换了
【5】正则表达式应用——删除空行
启动EditPlus,打开待处理的文本类型文件。
①、选择“查找”菜单的“替换”命令,弹出文本替换对话框。选中“正则表达式”复选框,表明我们要在查找、替换中使用正则表达式。然后,选中“替换范围”中的“当前文件”,表明对当前文件操作。
②、单击“查找内容”组合框右侧的按钮,出现下拉菜单。
③、下面的操作添加正则表达式,该表达式代表待查找的空行。(技巧提示:空行仅包括空格符、制表符、回车符,且必须以这三个符号之一作为一行的开头,并且以回车符结尾,查找空行的关键是构造代表空行的正则表达式)。
直接在”查找”中输入正则表达式“^[/t]*/n”,注意/t前有空格符。
(1)选择“从行首开始匹配”,“查找内容”组合框中出现字符“^”,表示待查找字符串必须出现在文本中一行的行首。
(2)选择“字符在范围中”,那么在“^”后会增加一对括号“[]”,当前插入点在括号中。括号在正则表达式中表示,文本中的字符匹配括号中任意一个字符即符合查找条件。
(3)按一下空格键,添加空格符。空格符是空行的一个组成成分。
(4)选择“制表符”,添加代表制表符的“/t”。
(5)移动光标,将当前插入点移到“]”之后,然后选择“匹配 0次或更多”,该操作会添加星号字符“*”。星号表示,其前面的括号“[]”内的空格符或制表符,在一行中出现0个或多个。
(6)选择“换行符”,插入“/n”,表示回车符。
④、“替换为”组合框保持空,表示删除查找到的内容。单击“替换”按钮逐个行删除空行,或单击“全部替换”按钮删除全部空行(注意:EditPlus有时存在“全部替换”不能一次性完全删除空行的问题,可能是程序BUG,需要多按几次按钮)。
1.在汉化的时候,是否经常碰到这样的语句需要翻译:
“Error adding the comment!”;
如果有很多类似的文件一个一个翻译显然很累而且感觉很无聊。
其实可以这样处理,在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
这样替换之后发生了什么?结果是:
“在增加the post时发生错误!”;
“在增加the comment时发生错误!”;
“在增加the user时发生错误!”;
ok,接下来你会怎么做?当然再替换一次把the post、the comment、the user替换成你要翻译的词。得到最后的结果:
在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
这样替换之后发生了什么?结果是:
在汉化量很大而且句式比较单调的情况下对效率的提高很明显!
解释一下:([^!|"|;]*)的意思是不等于!和”和;中的任何一个,意思就是这3个字符之外的所有字符将被选中(替换区域);
/1即被选中的替换区域所在的新位置(复制到这个新位置)。
3.经常手工清理一行一行地删除文本文件里面的空白行,其实可以交给Editplus更好的完成,在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
替换部分为空就可以删除空白行了,执行一下看看:)
abandon[2''b9nd2n]v.抛弃,放弃
abandonment[2''b9nd2nm2nt]n.放弃
abbreviation[2bri:vi''ei62n]n.缩写
abeyance[2''bei2ns]n.缓办,中止
ability[2''biliti]n.能力
able[''eibl]adj.有能力的,能干的
abnormal[9b''n0:m2l]adj.反常的,变态的
aboard[2''b0:d]adv.船(车)上
替换:@@@@@”/1″,”/2″,”/3″,
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
@@@@@”abide”,”[2''baid]“,”v.遵守”,
@@@@@”ability”,”[2''biliti]“,”n.能力”,
@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,
@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,@@@@@”abide”,”[2''baid]“,”v.遵守”,@@@@@”ability”,”[2''biliti]“,”n.能力”,@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,@@@@@”abolish”,”[2''b0li6]“,”v.废除,取消”,@@@@@”abolition”,”[9b2''li62n]“,”n.废除,取消”
“abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
“abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
“abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
“abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
“abide”,”[2''baid]“,”v.遵守”,
“ability”,”[2''biliti]“,”n.能力”,
“able”,”[''eibl]“,”adj.有能力的,能干的”,
“abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
“aboard”,”[2''b0:d]“,”adv.船(车)上”,
“abolish”,”[2''b0li6]“,”v.废除,取消”,
二、在正则表达式中“/”和“\”符号的区别!
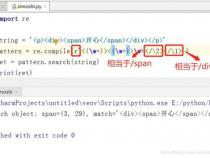
1、正则表达式中"/"是表达式开始和结束的标记,“\”可以将后面出现的字符标记为特殊字符,接下来在PHP中具体演示一下:
2、1,正则表达式是以/作为开始和结束的标记,表达式语法在两个/中间包裹,如下图所示
3、2,接着演示一下\,像下面的表达式匹配的是n
4、3,但是如果在n前面加上\匹配的就是换行符号了,如下图所示
5、4,可以用\进行转义的字符主要有以下几种
三、身份证号码的正则表达式及验证详解(JavaScript,Regex)
在进行用户实名验证时,常需利用身份证号码的正则表达式及校验方案。本文提供两种方案,使用者可依据项目需求选择适用方案。
身份证号码由十七位数字构成,包括地址码、出生日期码、顺序码与校验码。以北京市朝阳区女性身份证号码为例,其结构如下图所示。
方案1采用分步验证方法,设定如下规则:
1.1地址码规则:正则表达式为/^[1-9]\d{5}/。
1.2年份码规则:正则表达式为/(18|19|20)\d{2}/。若无需18开头年份,可去除18。
1.3月份码规则:正则表达式为/((0[1-9])|(1[0-2]))/。
1.4日期码规则:正则表达式为/(([0-2][1-9])|10|20|30|31)/。
1.5顺序码规则:正则表达式为/\d{3}/。
1.6校验码规则:正则表达式为/[0-9Xx]/。
方案1正则表达式整合如下,并附有测试程序。
方案2则在方案1基础上,引入省级地址码校验,提升验证准确性。并提供出生日期码校验、校验码校验的函数与测试程序。校验码计算较为复杂,公式如下所示:
公式:其中 ai表示身份证本体码的第 i位值,Wi表示第 i位的加权因子值。
校验码计算程序与测试代码如下。
以上内容系三胖对身份证号码验证的理解与分析,如有不妥之处,请指正。