Mysql变成分布式数据库
发布时间:2025-05-20 06:56:40 发布人:远客网络
一、Mysql变成分布式数据库
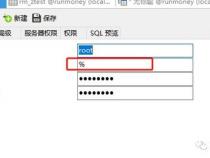
1、amoeba相当于一个SQL请求的路由器,目的是为负载均衡、读写分离、高可用性提供机制,而不是完全实现它们。用户需要结合使用MySQL的Replication等机制来实现副本同步等功能。amoeba对底层数据库连接管理和路由实现也采用了可插拨的机制,第三方可以开发更高级的策略类来替代作者的实现。这个程序总体上比较符合KISS的思想。
2、由上一条,建议使用MySQL的Replication机制建立Master-Slave来做副本。我一开始理解有误,使用了amoeba的virtual DB(负载均衡pool)做writePool,结果使得本应插入同一个表中的数据被拆分地写入了不同的物理数据库中。这样自然与副本的语义不符了。
3、amoeba已经实现了数据的垂直切分与水平切分。水平切分方面,粒度是行。使用SQLJEP语句可以设计出复杂的切分规则,个人认为是比较强大的。垂直切分的粒度是表,可以把针对不同表的请求发送到不同的节点上执行,但不能以列作为分片粒度。从作者的说法看,amoeba不做SQL解析和重写。在目前的机制下似乎是难以实现同一个表不同的列在不同节点上的分布。不过对开发人员来说,设计良好的表结构应该可以实现简单的基于关系属性的负载均衡的。
二、mysql分布式数据库适合做数据仓库么
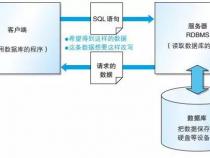
数据仓库就是数据库,只不过是按照业界不同的提法说法不同而已;一般的数据仓库的说法是要建立一个高性能的可查询数据库,一般说来是提供高效的查询而不是交互。
MySQL现有的几种数据库从5.5后缺省的数据引擎是Innodb,性能在查询上和MyISAM差不多,不过对事物的支持更加好。如果需要建立一个有规模的数据仓库首先必须考虑查询和聚合运算的效率问题,从MySQL内部的函数的使用效率出发选用innodb可以支持复杂的存储过程让运算集中在服务器上运行,可以高效的发挥服务器的运算性能和SQL集合运算的效率。
数据仓库的数据源可能来自不同的操作系统和数据库,怎么把数据同步到本地可以参考通用的方法,作为数据仓库需要考虑的是数据的一致性,比如一个流程的不同环节的数据来自不同的数据库,这时就需要考虑怎么来定制来保证数据的时效和一致,比如不允许第一步的数据还未进行同步,第二步的数据就已经同步到本地,这样的话后台的应用在读取数据的时候就会非常的混乱
数据仓库一般是从业务数据库导出到另外一个独立数据库作为计算分析,这样的好处在于把计算分开,避免非业务的大规模运算对正常业务的影响。即使软硬件崩溃也不会对正常业务造成影响,而数据重建只需要按照原来的方法恢复即可。在往数据仓库上同步数据的过程要灵活考虑数据同步的方法,缺省可直接使用Mysql的主从备份。如果不想对业务服务器造成太多影响,也可以采用自己定制的方法来进行增量备份和差异备份。
能够交由SQL完成的工作最好全部使用SQL来完成聚合,表和表进行联合的时候先进行添加约束,和外部的程序,比如统计分析的计算,尽量让SQL输出一个计算后的数据集给后台应用。
三、MySQL属于什么数据库
1、云数据库 MySQL(TencentDB for MySQL)是腾讯云基于开源数据库 MySQL专业打造的高性能分布式数据存储服务,让用户能够在云中更轻松地设置、操作和扩展关系数据库。
2、云存储服务,是腾讯云平台提供的面向互联网应用的数据存储服务。
3、完全兼容 MySQL协议,适用于面向表结构的场景;适用 MySQL的地方都可以使用云数据库。
4、提供高性能、高可靠、易用、便捷的 MySQL集群服务。
5、整合了备份、扩容、迁移等功能,同时提供新一代数据库工具DMC,用户可以方便的进行数据库的管理。