如何将非结构化数据转化为结构化数据
发布时间:2025-05-20 06:55:20 发布人:远客网络

一、如何将非结构化数据转化为结构化数据
随着机器学习的发展,过去传统的结构化数据分析方法已经不能满足我们的需求了。如何在神经网络中利用非结构化数据是很重要的一点。所以很多研究者致力于将非结构化数据处理成结构化数据的工具开发。将非结构化数据转化为结构化数据有以下几个方法:
虽然绝大多数数据是非结构化格式的,但是结构化数据普遍存在于各类商业应用软件和系统中,例如产品数据存储,交易日志,ERP和CRM系统中都存在大量结构化数据,这些结构化数据仍应用着陈旧的数据技术处理,如基于规则的系统,决策树等。这样的方法需要人工进行特征提取,操作繁琐且需要耗费大量人力进行数据标签。
非结构化数据,也就是通常使用的杂乱无章的文本数据。非结构化数据通常是不能用结构化数据的常规方法以传统方式进行分析或处理的,所以这也成为AI领域一个常见的难题,要理解非结构化数据通常需要输入整段文字,以识别其潜在的特征,然后查看这些特征是否出现在池中的其他文本中。因此,在处理此类任务时,深度学习以其出色的特征提取能力一骑绝尘,于是所有人都开始想着把神经网络用在结构化数据上——建个全连接层,把每一列的内容作为输入,再有一个确定好的标签,就可以进行训练和推理了。
需要寻找结构化数据的语义,目前要解决的问题主要有:
①数据清洗。要在结构化数据 AI应用上有所成果,首先需要解决人工数据清洗和准备的问题,找到极少或者没有人为干预的自动化方法,才能使得这一应用可落地可拓展。
②异构数据。处理结构化数据的其中一大挑战在于,结构化数据可能是异构的,同时组合了不同类型的数据结构,例如文本数据、定类数据、数字甚至图像数据。其次,数据表有可能非常稀疏。想象一个 100列的表格,每列都有 10到 1000个可能值(例如制造商的类型,大小,价格等),行则有几百万行。由于只有一小部分列值的组合有意义,可以想象,这个表格可能的组合空间有多么「空」。
③语义理解。找到这些结构化数据的语义特征。处理结构化数据并不仅仅依赖于数据本身的特征(稀疏,异构,丰富的语义和领域知识),数据表集合(列名,字段类型,域和各种完整性约束等)可以解码各数据块之间的语义和可能存在的交互的重要信息。也就是说,存储在数据库表中的信息具有强大的底层结构,而现有的语言模型(例如 BERT)仅受过训练以编码自由格式的文本。
除了某些特定的需求外,经过预处理之后的结构化数据,应该满足以下特点:
①所有值都是数字–机器学习算法取决于所有数据都是数字;
②非数字值(在类别或文本列中的内容)需要替换为数字标识符;
③标识并清除具有无效值的记录;
⑤所有记录都需要使用相同的一致类别。
二、informix数据库如何导入导出数据表
1、Informix我之前是没有用到过的,因为这次需要采用Informix作为ETL的一个中间库,所以需要学习它。
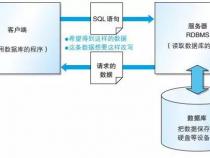
2、所谓中间库,就是说把从各个业务系统卸载下来的数据(通常是文本),装载到这个中间库Informix中,然后再然过ETL过程操作,最后装载到数据仓库中。
3、之所以要采用一个中间库,主要是为了使数据容易维护,因为从各业务系统卸载下来的数据(通常是文本),文本文件是比较难于维护的。还有解决一些乱码问题,Informix这里可以把乱码的数据去除掉。最后一个就是解决文本文件取定长数据的问题,很容易出错,不过这个具体我还是不是很明白。
4、其实也可以直接使用文本文件,就是说不经过这个中间库,然后需要解决上面说的三个问题。
5、Informix数据导出,也叫做卸数:unload to fileName.txt select* from tableName
6、语法比较简单,unload to后面接导出的文本文件名称,select后面接你所要导出的数据的条件。
7、Informix数据导入,也叫做装数:load fileName.txt insert into tableName
8、load后面接需要导入的文本文件名称,后面insert into后面接数据表名。
9、备份表结构dbschema-d database database.sql
10、-d表示导出整个数据库的表结构,-t表示导出某一个数据表的表结构。
三、informix表空间与数据库的关系
严格来说,数据库与表空间没有直接的关系,而是通过数据库的表与表空间关联
1、表空间是在整个INFORMIX实例下可见
2、创建数据库时,可以指定数据库的默认表空间
3、在数据库中创建表时,可以指定表所在的表空间,如不指定则默认为数据库创建时的默认表空间
4、在数据库中创建表时,可以使用实例中的所有表空间,采用分片表时,可以为一个表指定多个表空间。