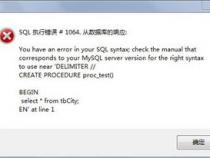
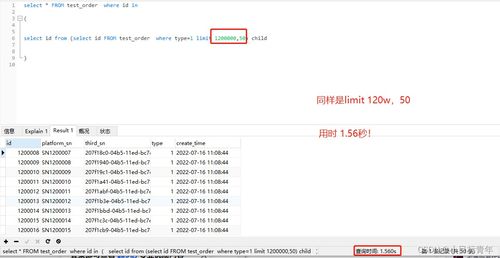
mysql 分页优化
发布时间:2025-05-14 07:48:54 发布人:远客网络
一、mysql 分页优化
你第二个会生成很多条记录,这个是多表查询了,你这么一查的话会生成很多条记录
比如说你 A表 5000条,记录 B表有 3000条记录
你一联合就会生成 5000* 3000条记录,然后在这里面进行 where查询符合条件的记录..
对于这个问题我们就应该这样查询
(select* from table where条件) as a,
(select* from table2 where条件) as b
原因是,我先把 a表和 b表里面符合条件的数据选择出来
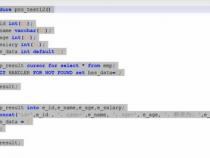
二、存储过程是多用还是少用
1、做项目的时候我们有时候会面临一个选择,我们到底是应该多写存储过程还是少写存储过程了?这个问题的争论也是由来已久,在不同的公司以及不同的技术负责人那里往往会得到不同的答案。在实际项目中我们最后所采取的方式,往往不外乎以下三种方式。
2、第一种方式是要求所有数据库操作不使用任何的存储过程,所有操作都采用标准sql语句来完成,即便是一个动作需要完成多步数据库操作,也不使用任何存储过程,而是在程序代码中采用事务的方式来完成;第二种方式就是就要求所有的数据库操作都用存储过程封装起来,哪怕是一个最简单的insert操作。在程序代码看不到一行 sql语句,如果采用分工合作的方式,程序员甚至都可以不懂sql语法。第三种方式是一般相对简单的数据库操作采用标准sql语句来完成,一些相对比较复杂的商务逻辑用存储过程来完成。
3、当然系统如果采用了hibernate或nhibernate之类的框架,不需要写sql语句的时候,我想还是应该属于第三种方式,因为在开发的时候hibernate框架允许我们在适当的时候,抛开其框架自己写存储过程和sql语句来完成数据库操作。其实这三种方式都各有所长,也各有不足。
4、第一种方式是所有的数据库操作都采用标准sql语句来完成的方式,在程序的执行效率上是肯定不如后面两种方式,系统如果是一个大型的ERP,这种方式就是绝对不可取的。因为在开发基本结束后,系统如果需要优化或者希望得到优化时,那对开发人员来说就是一件非常麻烦的事情了,因为优化的重点基本上都是集中数据库操作上,开发人员所能做的就是一个个sql语句去检查,是不是还能进一步优化,尤其是一些相对比较复杂的查询语句是我们所检查的重点。分页显示就是一个典型的存储过程提高程序效率的例子。如果使用存储过程来进行分页操作,就是利用存储过程从系统中提取我们所需要的记录集,分页的效率就大大提高了。反过来如果我们不用存储过程进行分页操作,是利用sql语句的方式把所有记录集都读入内存中,然后再从内存中获取我们所需要的记录集合,这样分页效率自然就降低了。当然利用sql语句也能得到我们所需要的记录,而不是所有记录,但是那样麻烦多了,不在我们讨论范围之内。
5、这种方式另外还有一个不足之处,一个系统或一个项目总会或多或少地存在有一些容易变化而又复杂的商务逻辑,如果把这些复杂的商务逻辑封装到存储过程中,商务逻辑的变化都只涉及存储过程变化,而与程序代码不发生关系,那么不用存储过程太可惜了。
6、这种方式虽然有不足,但是一旦采用这种方式的话,我们如果对该项目进行数据库移植的时候,开发人员就会觉得当时的决策人是多么的伟大与英明。而且我们知道access和mysql的以前版本是不提供存储过程支持的,所有一些中小项目在这个方面的选择往往也是不得已而为之。不用存储过程有一个优点,调试代码的时候没有存储过程可是要方便很多很多的哦,所以在很多很多的项目中都是采用标准的sql语句而不使用任何的存储过程。这可是大多程序员用标准sql而不用存储过程的直接原因,说白了,就是嫌麻烦。
7、第二种方式是所有的数据库操作全部采用存储过程封装的方式,如果采用这种方式,程序的执行效率相对要高,尤其面对在一些复杂的商务逻辑时候,不仅在效率方面有明显的提高,而且当商务逻辑发生变化时,我们开发人员做相应的修改的时候,往往都不用修改程序代码,仅仅修改存储过程就能满足系统变化了。
8、还有一个好处就是当我们开发好的一个系统后,如果发现一种模式或语言在某些方面难以满足需求时,我们就可以很快的用两外一种语言来重新开发,那个时候就非常方便了。比如在02年中科院下属的一个公司就用ASP开发了一个B/S结构的HIS,几乎所有的功能都是用存储过程实现的。杭州妇幼保健医院在使用过程中由于种种原因要求改成C/S结构的,改的时候就发现当初大量的使用存储过程真是好啊!
9、全部用存储过程的方式有一个缺点就是程序在开发时调式相当麻烦,因为大家都知道程序错误大部分是出在代码与数据库交互的时候。回想起来也真是感慨,依稀记得当年在烟台的时候,当时是网通的一个项目,月底时他们从用户那所收的费用在帐上的金额与实际所收金额对不上,结果熬了一个通宵才搞定,最后找出原因来就是在存储过程中犯了个不起眼的错误。
10、第三种方式就是部分使用存储过程。就是在处理一些复杂的商务逻辑的时候用存储过程封装,一般比较简单的数据库操作还是用标准sql语句的方式。这样能保证程序的执行效率,同时也能保证一定的开发效率。这种方式也是在实际项目应用最多的方式。
11、具体一个项目采用哪种方式来做,是需要我们根据具体情况来确定的,不能一概而论。如果项目小、对程序的执行效率要求也不高。而且将来项目还可能做数据库移植的话,那就采用第一重方式是最好的;如果项目运行一定时间可能采用别的语言来重新开发,那就用第二种方式比较好。
12、如果是一个很多因素都不太确定的项目,个人认为一般采用第三方式比较好,就是一般的数据库操作都采用sql语句来实现,当然sql语句最好是标准的 sql语句,而那些相对比较烦琐的商务逻辑就用存储过程来封装好了。其实就是只在项目的某些特定的功能模块中采用存储过程的方式而已。这样做出来的项目既能灵活升级与移植,又能保证程序的执行效率。
13、扯远一点,如果是一个比较大型的ERP之类的项目,个人建议hibernate是个不错的选择,.net是nhibernate。数据库操作就省心了。没有用过的朋友可能刚开始有点排斥,这很正常,但是用熟练就能感觉它好用。
三、sqlsever 2000 分页语句
SET@s='SELECT top'+RTRIM(@pageSize)+'* FROM enterprise WHERE ID not in(select top'+RTRIM((@pageNo-1)*@pageSize)+' from enterprise)'
可用存储过程,如以上ID为表唯一列时可调用
SQL2000可用邹建写法,最高效的写法还是针对性的写
楼主换SQL2005以上版本可用row_Number实现更简单
显示指定表、视图、查询结果的第X页
对于表中主键或标识列的情况,直接从原表取数查询,其它情况使用临时表的方法
如果视图或查询结果中有主键,不推荐此方法
--邹建 2003.09(引用请保留此信息)--*/
exec p_show'地区资料'
exec p_show'地区资料',5,3,'地区编号,地区名称,助记码','地区编号'
if exists(select* from dbo.sysobjects where id= object_id(N'[dbo].[p_show]') and OBJECTPROPERTY(id, N'IsProcedure')= 1)
@QueryStr nvarchar(4000),--表名、视图名、查询语句
@PageSize int=10,--每页的大小(行数)
@PageCurrent int=1,--要显示的页
@FdShow nvarchar(4000)='',--要显示的字段列表,如果查询结果有标识字段,需要指定此值,且不包含标识字段
@FdOrder nvarchar(1000)=''--排序字段列表
declare@FdName nvarchar(250)--表中的主键或表、临时表中的标识列名
,@Id1 varchar(20),@Id2 varchar(20)--开始和结束的记录号
declare@strfd nvarchar(2000)--复合主键列表
,@strjoin nvarchar(4000)--连接字段
,@strwhere nvarchar(2000)--查询条件
select@Obj_ID=object_id(@QueryStr)
,@FdShow=case isnull(@FdShow,'') when'' then'*' else''+@FdShow end
,@FdOrder=case isnull(@FdOrder,'') when'' then'' else' order by'+@FdOrder end
,@QueryStr=case when@Obj_ID is not null then''+@QueryStr else'('+@QueryStr+') a' end
--如果显示第一页,可以直接用top来完成
select@Id1=cast(@PageSize as varchar(20))
exec('select top'+@Id1+@FdShow+' from'+@QueryStr+@FdOrder)
--如果是表,则检查表中是否有标识更或主键
if@Obj_ID is not null and objectproperty(@Obj_ID,'IsTable')=1
select@Id1=cast(@PageSize as varchar(20))
,@Id2=cast((@PageCurrent-1)*@PageSize as varchar(20))
select@FdName=name from syscolumns where id=@Obj_ID and status=0x80
if@@rowcount=0--如果表中无标识列,则检查表中是否有主键
if not exists(select 1 from sysobjects where parent_obj=@Obj_ID and xtype='PK')
goto lbusetemp--如果表中无主键,则用临时表处理
select@FdName=name from syscolumns where id=@Obj_ID and colid in(
select colid from sysindexkeys where@Obj_ID=id and indid in(
select indid from sysindexes where@Obj_ID=id and name in(
select name from sysobjects where xtype='PK' and parent_obj=@Obj_ID
if@@rowcount>1--检查表中的主键是否为复合主键
select@strfd='',@strjoin='',@strwhere=''
select@strfd=@strfd+',['+name+']'
,@strjoin=@strjoin+' and a.['+name+']=b.['+name+']'
,@strwhere=@strwhere+' and b.['+name+'] is null'
from syscolumns where id=@Obj_ID and colid in(
select colid from sysindexkeys where@Obj_ID=id and indid in(
select indid from sysindexes where@Obj_ID=id and name in(
select name from sysobjects where xtype='PK' and parent_obj=@Obj_ID
select@strfd=substring(@strfd,2,2000)
,@strjoin=substring(@strjoin,5,4000)
,@strwhere=substring(@strwhere,5,4000)
/*--使用标识列或主键为单一字段的处理方法--*/
exec('select top'+@Id1+@FdShow+' from'+@QueryStr
+' where'+@FdName+' not in(select top'
+@Id2+''+@FdName+' from'+@QueryStr+@FdOrder
/*--表中有复合主键的处理方法--*/
exec('select'+@FdShow+' from(select top'+@Id1+' a.* from
(select top 100 percent* from'+@QueryStr+@FdOrder+') a
left join(select top'+@Id2+''+@strfd+'
from'+@QueryStr+@FdOrder+') b on'+@strjoin+'
where'+@strwhere+') a'
select@FdName='[ID_'+cast(newid() as varchar(40))+']'
,@Id1=cast(@PageSize*(@PageCurrent-1) as varchar(20))
,@Id2=cast(@PageSize*@PageCurrent-1 as varchar(20))
exec('select'+@FdName+'=identity(int,0,1),'+@FdShow+'
into#tb from'+@QueryStr+@FdOrder+'
select'+@FdShow+' from#tb where'+@FdName+' between'