C语言调用汇编程序时,使用哪些寄存器来传递参数
发布时间:2025-05-13 22:24:42 发布人:远客网络
一、C语言调用汇编程序时,使用哪些寄存器来传递参数
C语言与汇编语言混合编程应遵守的规则
ARM编程中使用的C语言是标准C语言,ARM的开发环境实际上就是嵌入了一个C语言的集成开发环境,只不过这个开发环境与ARM的硬件紧密相关。
在使用C语言时,要用到和汇编语言的混合编程。若汇编代码较为简洁,则可使用直接内嵌汇编的方法;否则要将汇编程序以文件的形式加入到项目中,按照ATPCS(ARM/Thumb过程调用标准,ARM/Thumb Procedure Call Standard)的规定与C程序相互调用与访问。
在C程序和ARM汇编程序之间相互调用时必须遵守ATPCS规则。ATPCS规定了一些子程序间调用的基本规则,哪寄存器的使用规则,堆栈的使用规则和参数的传递规则等。
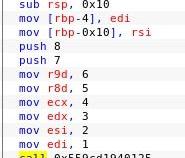
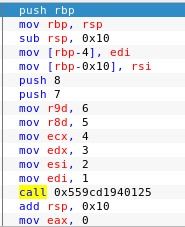
子程序之间通过寄存器r0~r3来传递参数,当参数个数多于4个时,使用堆栈来传递参数。此时r0~r3可记作A1~A4。
在子程序中,使用寄存器r4~r11保存局部变量。因此当进行子程序调用时要注意对这些寄存器的保存和恢复。此时r4~r11可记作V1~V8。
寄存器r12用于保存堆栈指针SP,当子程序返回时使用该寄存器出栈,记作IP。
寄存器r13用作堆栈指针,记作SP。寄存器r14称为链接寄存器,记作LR。该寄存器用于保存子程序的返回地址。
寄存器r15称为程序计数器,记作PC。
ATPCS规定堆栈采用满递减类型(FD,Full Descending),即堆栈通过减小存储器地址而向下增长,堆栈指针指向内含有效数据项的最低地址。
整数参数的前4个使用r0~r3传递,其他参数使用堆栈传递;浮点参数使用编号最小且能够满足需要的一组连续的FP寄存器传递参数。
子程序的返回结果为一个32位整数时,通过r0返回;返回结果为一个64位整数时,通过r0和r1返回;依此类推。结果为浮点数时,通过浮点运算部件的寄存器F0、D0或者S0返回。
汇编程序的书写要遵循ATPCS规则,以保证程序调用时参数正确传递。在汇编程序中调用C程序的方法为:首先在汇编程序中使用IMPORT伪指令事先声明将要调用的C语言函数;然后通过BL指令来调用C函数。
例如在一个C源文件中定义了如下求和函数:
调用add()函数的汇编程序结构如下:
当进行函数调用时,使用r0和r1实现参数传递,返回结果由r0带回。函数调用结束后,r0的值变成3。
C程序调用汇编程序时,汇编程序的书写也要遵循ATPCS规则,以保证程序调用时参数正确传递。在C程序中调用汇编子程序的方法为:首先在汇编程序中使用EXPORT伪指令声明被调用的子程序,表示该子程序将在其他文件中被调用;然后在C程序中使用extern关键字声明要调用的汇编子程序为外部函数。
例如在一个汇编源文件中定义了如下求和函数:
EXPORT add;声明add子程序将被外部函数调用
在一个C程序的main()函数中对add汇编子程序进行了调用:
extern int add(int x,int y);//声明add为外部函数
当main()函数调用add汇编子程序时,变量a、b的值会给了r0和r1,返回结果由r0带回,并赋值给变量c。函数调用结束后,变量c的值变成3。
在C语言中内嵌汇编语句可以实现一些高级语言不能实现或者不容易实现的功能。对于时间紧迫的功能也可以通过在C语言中内嵌汇编语句来实现。内嵌的汇编器支持大部分ARM指令和Thumb指令,但是不支持诸如直接修改PC实现跳转的底层功能,也不能直接引用C语言中的变量。
嵌入式汇编语句在形式上独立定义的函数体,其语法格式为:
其中“__asm”为内嵌汇编语句的关键字,需要特别注意的是前面有两个下划线。指令之间用分号分隔,如果一条指令占据多行,除最后一行外都要使用连字符“\”。
5、基于ARM的C语言与汇编语言混合编程举例
下面给出了一个向串口不断发送0x55的例子:
该工程的启动代码使用汇编语言编写,向串口发送数据使用C语言实现,下面是启动代码的整体框架:
BL Main;跳转到Main()函数处的C/C++程序
#include"..\inc\config.h"//将有关硬件定义的头文件包含进来
unsigned char data;//定义全局变量
Target_Init();//对目标板的硬件初始化
Uart_Printf("%x",data);//向串口送数
二、C语言中,如何定义单片机的寄存器
位地址在汇编语言中,只能直接寻址,不支持间接寻址。那么,在
语言中,也就不能用指针来操作。所以不能定义单片机的寄存器。
访问寄存器可以通过直接地址引用来完成。
例如52单片机的寄存器有4组,分别为00H-07H,08H-0FH,10H-17H,18H-1FH,各组均8字节,要结合程序状态字寄存器PSW(D0H)中的RS0,RS1的组合来确定是哪一组。
uchar dacRn(uchar n)//n=[0..7]
n+=(PSW& 0x18);//PSW 7:CY 6:AC 5:F0 4:RS1 3:RS0 2:OV 1:F1 0:P
//本来要右移三位变为0-3,但由于是8个一组要乘以8(左移3位),所以直接加上寄存器编号就可以了
三、C语言问题 在线等
这个表达式的求值顺序为从右到左:
首先计算a/a的值为1,然后计算下一部分赋值语句,也就是a+=1,a的值变成5+1也就是6;下一步是a*=6,a自乘一次变成36;接下来计算a-=36,于是a=a-36,结果为0。
测试如图,环境为Windows XP SP3+ MinGW(gcc4.3),以及ubuntu9.04(Linux 2.6)gcc4.3
实际上如图所示,gcc在-Wall开关下会提示a的这种赋值可能是未定义的行为,因而可能不同的编译器实现会有不同的结果。也就是说,尽管ANSI C99标准中规定了表达式求值的顺序是从右到左,但是并没有规定在一个表达式中一个变量出现多次时,这个变量的值在计算过程中是不是会变。
上面给出的gcc的实现方式是对a随时求值并赋值,然而另一个编译器可能会这样做:(首先咱们通俗的说一下^_^)
我们记住了a的值是5,然后开始从右到左计算:a/a值是1;接下来计算a+=1,根据我们的记忆,a的值是5,于是这部分的值就是6;同样,计算a*=6时,根据我们的记忆,a的值是5,所以结果变成30;然后a-=30,便计算出5-30也就是-25的结果。
这一种理解方式可能跟我们看到的表达式不同,毕竟我们见到的表达式中是随时赋值,而编译器理解成a-=(a*(a+(a/a)))并不是我们想说的计算,——正因为这个原因,大部分编译器实现时都采用的是第一种理解方式,也就是说,尽管C99中没有明确规定,但是大家已经比较统一的采用了第一种也是比较自然的理解方式来编译这段代码。
存在第二种理解方式的原因在于,我们的变量是在内存中的,然而参与计算时大部分数据位于CPU的寄存器中。因而,如果我以这样一种方式去实现运算和优化,即将我们认为经常用到的数据存储在寄存器中,以便提高速度,就会变成这种情况。可能的运行过程如下:
编译器发现a在语句中多次出现,于是将a的值直接mov到某个寄存器中,比如EBX,然后开始计算:a/a也就是EBX/EBX(甚至这句没有而直接就是1),将结果1放在EAX中,然后下一步把EBX加到EAX上,就是那个a+=什么什么,然后再把EBX乘到EAX上,结果仍在EAX,最后EBX-EAX赋值给EAX,再将EAX mov到变量a,就得到了-25这样的结果。
当然,上面仅仅是通过分析得到的可能的运行过程,鉴于大部分编译器都不是这样实现的,而且我这里只有gcc环境,没有办法进行测试,因而我们只能说可能存在,但没有实例。
另外需要提醒楼主,所有牵扯到“未定义”(Undefined)行为的语句都是应该在编程中避免的,因为这些语句将依赖于您特定的编译环境。像上面的语句,如果我想要说明白,并且避免未定义行为,就将该拆开的赋值拆开成多个语句,写成这样:
也就是尽量保持语句的简单,一个语句中最多一个赋值。(KISS原则)
呵呵,没想到我速度不够快,楼主又增加了几个题目。看到这些我才想起来,这应该是某些测试题上面的东西了吧?很多测试题甚至包括二级考试的题目都会考察一些与编译器实现和特定环境相关的问题,而如果你不是要学习编译原理这种课程,那么这样的考察是没有任何意义的。很多这样的练习题都是,不会对个人的编程能力有任何提升,反倒使得大家经常钻入“未定义”的陷阱出不来。个人观点是,如果想学好编程,自己动手实践是最好的途径。很多东西可以通过实践去学习,比如您编程发现i++没问题但是1++会报错,于是您就知道了哦原来自增运算只能施加于左值(l-value)……当然一些基础的内容还是必要的。实际上后面这几个题目都很基础,这样的问题应该在学习C语言的前期就能够自己解答的。
废话说的不少,本来我看到第一个题目后只是想说明“未定义”行为的一些东西,所以就稀里哗啦写了这么多。但现在看看您下面的问题我觉得您可能只是想要答案而已,——于是我就顺便把其他题目也答了吧,虽然我的建议是您最好自己去发现,通过教材、实践。
第一个:未定义行为,大多数情况下会是0,具体原因前面说的比较清楚了。
第二个:再纠正一个观点,就是这种不确定的问题并不是机器或者系统的问题,而在于编译器的实现。比如我在32位机器上装32位系统,而运行16位的TC,或者64位机器装32位系统,运行16位程序TC,甚至64位机器装64位系统,运行16位TC,最终由TC编译出来的程序一定是被16位TC限定的只能使用寄存器中的AH, AL, AX, BX...而不能使用EAX, EBX,更不用提RAX(当然RAX们只有64位系统和64为程序才用得到),因而设计编译器时只能自然使用AX大小的变量,也就是16位,于是TC中的int长度为16比特或者说两个字节。我想说明的是这些不确定的问题都是编译器实现时造成的,跟系统无关。
好的言归正传,题目要求“值”所占的字节数,语句就是sizeof(a+4.5),然后您可以通过printf将这个结果输出,当然这个结果在大多数32位编译器上应该是8,因为a是整数,但是4.5是双精度浮点数,运算将默认对整数进行类型转换,变成同样的double型后和4.5进行运算。得到的结果当然也是double型,——而几乎所有32位编译器实现中,double型占8个字节。
这里不得不提到的是C99标准的一个可能会造成众多C程序员疑惑的地方,就是浮点数在程序中默认是双精度的,除非强加f标志表示float型。于是,我们可以测试,如果在前面的语句中将4.5这个数字后面加上f标志成为4.5f,那么结果可能是不一样的。事实上,大部分编译器将float规定为4字节,这样经过类型提升后,4字节的int变成4字节的float,和4字节的float运算,得到的仍然是4字节的float,于是就会得到结果为4。
好的我们继续,第三题是基础知识,很明显的C语言中的运算符有左结合与右结合之分,因而A是错误的,故选A。这个就不多说了。
第四题:关于自增和自减,我们从这个运算符的名字就能够看出,它们是针对一个东西的,而且这个东西要可以改变才行。专业一点儿就是,自增和自减运算仅施加于左值,所谓左值通俗讲就是可以放在等号左边的东西(比如变量,但不是全部变量都可以)另外有一种理解是可以在数据段定位(Locate)内存地址的东西,详细点就是可以被赋值的变量,非“只读变量”。或者就是我们通常所说的变量。(注意变量可以用const进行只读修饰。)
给出答案:单目运算符,只能作用在左值上(或者可以说变量,不过不确切),不能作用在右值(两个空就可以填成常量和表达式,但是注意这也是不确切的)。
这个问题很难给出一个确切的答案,——这也是好多这种题目的共同特征,个人感觉没有必要确切到什么地步,只要能理解就行。而C语言中很多标准的地方都是有争议的,比如左值右值的问题。这些在实际编程中真的都不造成影响,但是有些人就愿意把带有这种色彩的不确定性用来考试……