c语言的子程序有过程和函数两种
发布时间:2025-05-13 19:56:30 发布人:远客网络
一、c语言的子程序有过程和函数两种
1、是的,C语言的子程序有两种,分别是过程(procedures)和函数(functions)。过程是一组具有特定功能的语句,可以接受输入参数并返回一个值。函数是一组具有特定功能的语句,不接受输入参数,但可以返回一个值。过程和函数在C语言中都是可重用的代码块,可以多次调用并执行。它们在程序中扮演着重要的角色,可以提高代码的可读性和可维护性。
2、过程和函数在C语言中的使用非常广泛,可以用于控制流程、计算、数据结构和算法等方面。通过使用过程和函数,可以将复杂的代码分解成更小的模块,使得代码更加清晰易懂。同时,过程和函数还可以提高代码的可重用性和可维护性,使得代码更加易于维护和修改。
3、在C语言中,过程和函数的定义通常使用关键字"void"来表示没有返回值。函数的定义通常包括函数名、参数列表和函数体。
4、例如,以下是一个简单的函数定义示例:
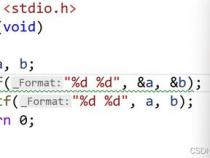
5、int add(int a, int b){ int sum= a+ b; return sum;}
6、在这个示例中,"add"是函数的名称,"int"是返回值的数据类型,"a"和"b"是函数的参数列表,"sum"是函数的局部变量,"return sum"是函数的返回语句。
7、过程和函数的调用也非常简单,只需要使用函数名加上参数列表即可。例如,以下是一个过程调用的示例:
8、在这个示例中,"add"是过程的名称,"3"和"5"是过程的参数列表,"result"是过程的返回值。
二、单片机编程语言一般有哪几种
单片机编程语言很多,大致分成三类:机器语言、汇编语言、高级语言。机器语言由于繁琐容易出错,大部分用户已经不再便用。
汇编语言是一种用文字助记符来表示机器指令的符号语言,是最接近机器码的一种语言。其主要优点是占用资源少,程序执行效率高,由于它一条指令就对应一条机器码,每一步的执行动作都很清楚,并且程序大小和堆栈调用情况都容易控制,调试起来也比较方便。但是不同的类型的单片机,其汇编语言可能有点差异,所以不易移植,因为他们的指令系统是有区别的。但懂得汇编语言可帮助了解影响川可语言效率的特殊规定。例如,懂得汇编语言指令就可以便用在片内ram作变量的优势,因为片外变量需要几条指令才能设署累加器和数据指针进行存取。同样的,当要求便用浮点数和启用函数时也只有具备汇编编程经验才能避免生成庞大的、效率低的程序,对于这方面的编程,没有汇编语言是做不到的。
单片机的C语言是一种编译型程序设计语言,它兼顾了多种高级语言的特点,并具备汇编语言的功能。C语言具有功能丰富的库函数,运算谏磨快,编译效率高,有良好的可移植性,而且可以实现直接对系统硬件的控制。此外,C语言程序具有完整的程序模块结构,从而为软件开发中栗用模块化程序设计方法提供了有力的保障。与汇编相比,有如下优点:
对单片机的指令系统不要求了解,仅要求对51的存储器结构有初步了解,至于寄存器分配、不同存储器的寻址及数据类型等细节均由编译器管理。程序有规范的结构,可分为不同的函数。这种方式可便程序结构化,将可变的选择与特殊操作组合在一起,改善了程序的可读性。
编程及程序调试时间显著缩短,从而提高效率。提供的库包含许多标准子程序,具有较强的数据处理能将已编好程序可容易的植入新程序,因为它具有方便的模块化编程技术。
功能强而有弹性,提供的库包含许多标准子程序,具有较强的数据处理能力,能将已编好程序容易的植入新程序,因为它具有方便的模块化编程技术。
单片机C语言作为一种非常方便的语言而得到广泛的支持,(语言程序本身并不依赖于机器硬件系统,基本上不做修改就可根据单片翻U均不同较快地移植过来。
用单片机c语言进行程序设计,已成为单片机软件开发的一个主流,作为一个技术全面并涉足较大规模的软件系统开发的单片机开发人员最好能够掌握基本的C语言编程。
单片机,全称单片微型计算机(英语:Single-Chip Microcomputer),又称微控制器(Microcontroller),是把中央处理器、存储器、定时/计数器(Timer/Counter)、各种输入输出接口等都集成在一块集成电路芯片上的微型计算机。与应用在个人电脑中的通用型微处理器相比,它更强调自供应(不用外接硬件)和节约成本。它的最大优点是体积小,可放在仪表内部,但存储量小,输入输出接口简单,功能较低。由于其发展非常迅速,旧的单片机的定义已不能满足,所以在很多应用场合被称为范围更广的微控制器;由于单芯片微电脑常用于当控制器故又名single chip microcontroller,但是目前在中国大陆仍多沿用“单片机”的称呼。
三、C语言8个实用方法有哪些
选择一种合适的数据结构很重要,如果在一堆随机存放的数中使用了大量的插入和删除指令,那使用链表要快得多。数组与指针语包莫有十分密切的关系,一般来说,指针比较灵活简洁,而数组则比较直观,容易理解。对于大部分的编译器,使用指针比使用数组生成的代码更短,执行效率更高
能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。当然,在定义变量后不要超过变量的作用范围,如果超过变量的范围赋值,C编译器并不报错,但程序运行结果却错了,而且这样的错误很难发现。
一个聪明的游戏大虾,基本上不会在自己的主循环里搞什么运算工作,绝对是先计算好了,再到循环里查表。如果表很大,不好写,就写一个init函数,在循环外临时生成表格。
位操作只需一个指令周期即可完成,而大部分的C编译器的“%”运算均是调用子程序来完成,代码长、执行速度慢。通常,只要求是求2n方的余数,均可使用位操作的方法来代替。
把结构体的成员按照它们的类型长度排序,声明成员时把长的类型放在短的前面。编译器要求把长型数据类型存放在偶数地址边界。
b、把结构体填充成最长类型长度的整倍数
把结构体填充成最长类型长度的整倍数。照这样,如果结构体的第一个成员对齐了,所有整个结构体自然也就对齐了。
要充分利用CPU的指令缓存,就要充分分解小的循环特别是当循环体本身很小的时候,分解循环可以提高性能。注意,很多编译器并不能自动分解循环。
对于一些不需要循环变量参加运算的任务可以把它们放到循环外面,这里的任务包括表达式、函数的调用、指针运算、数组访问等,应该将没有必要执行多次的操作全部集合在一起,放到一个init的初始化程序中进行。
尽可能把长的有依赖的代码链分解成几个可以在流水线执行单元中并行执行的没有依赖的代码链。很多高级语言,包括C++,并不对产生的浮点表达式重新排序,因为那是一个相当复杂的过程。
当数据保存到内存时存在读写依赖,即数据必须在正确写入后才能再次读取。虽然AMD Athlon等CPU有加速读写依赖延迟的硬件,允许在要保存的数据被写入内存前读取出来,但是,如果避免了读写依赖并把数据保存在内部寄存器中,速度会更快。
对干一些不需要循环变量参加运算的计算任务可以把它们放到循环外面,现在许多编译器还是能自己干这件事,不过对干中间使用了变量的算式它们就不敢动了,所以很多情况下你还得自己干。对于那些在循环中调用的函数,凡是没必要执行多次的操作通通提出来放到一个init函数里,循环前调用。另外尽量减少喂食次数,没必要的话尽量不给它传参,需要循环变量的话让它自己建立一个静态循环变量自己累加,速度会快一点。
与LISP之类的语言不同,C语言一开始就病态地喜欢用重复代码循环,许多C程序员都是除非算法要求,坚决不用递归。
事实上,C编译器们对优化递归调用一点都不反感,相反,它们还很喜欢干这件事。只有在递归函数需要传递大量参数,可能造成瓶颈的时候,才应该使用循环代码,其他时候,还是用递归好些。