Kinect与Ir相机外参标定与深度对齐
发布时间:2025-08-17 05:02:51 发布人:远客网络
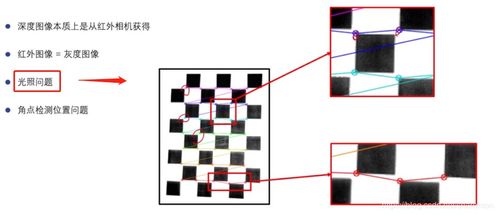
一、Kinect与Ir相机外参标定与深度对齐
1、在自动驾驶领域,DMS(Driver Monitoring System)系统扮演着至关重要的角色,其中,通过红外(IR)相机捕捉驾驶员信息,如头姿、视线和手势,结合深度图信息,能显著提高分析的准确性。本文聚焦于如何通过外参标定与深度对齐技术,实现普通IR相机图像与深度图之间的对应。
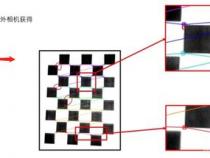
2、外参标定是关键步骤之一。它指的是两个坐标系之间的相对位置和姿态关系,如ARUCO板与相机间的关系。通过预先标定出IR相机与Kinect相机的内参,借助ARUCO板作为媒介,我们可以计算出IR相机与Kinect相机间的外参关系。
3、外参标定的具体步骤包括:首先,通过棋盘格标定获取相机内参;接着,利用ARUCO板,分别标定IR相机与ARUCO板、ARUCO板与Kinect相机之间的外参关系。最后,通过已知的两个外参关系,求解出IR相机与Kinect相机间的外参关系。
4、计算外参关系时,通过已知的ARUCO板大小和角点坐标,以及从图像中提取的角点坐标,可以建立方程解出外参R和t。这一过程类似于张正友的棋盘格标定算法,最终目标是将ARUCO板坐标系下的角点坐标转换至图像坐标系。
5、深度对齐是确保两幅图像深度一致性的重要环节。一旦外参标定准确,深度信息的对齐自然得以实现,确保了深度信息与图像信息的一致性。这一过程依赖于已知的内参、深度信息和像素坐标,最终计算出三维坐标。
6、在实践过程中,确保外参标定的准确性至关重要,它直接影响深度对齐的质量。正确标定外参,能够确保深度信息的精确对齐,从而提升分析的准确性和可靠性。
7、总结,本文详细阐述了如何通过外参标定与深度对齐技术,实现IR相机图像与深度图之间的对应。这一技术在自动驾驶领域,特别是在DMS系统中,具有广泛应用价值。通过精确的外参标定和有效的深度对齐,可以显著提升驾驶员状态监测的准确性和系统的整体性能。
二、关于深度相机的精度问题
深度相机主要分为三种类型:主动投射结构光的深度相机、被动双目相机以及飞行时间(ToF)相机。这些相机包括Kinect 1.0、Intel RealSense、Enshape和Ensenso等基于主动结构光的设备,STEROLABS的ZED 2K Stereo Camera和Point Grey的BumbleBee等被动双目相机,以及微软的Kinect 2.0、MESA的SR4000、Google Project Tango中使用的PMD Tech TOF相机、Intel的SoftKinect DepthSense、Basler基于松下芯片开发的TOF相机以及国内初创公司基于TI方案开发的TOF相机等。
Kinect V2的精度在2mm至4mm之间,近距离的精度更高,而Kinect V1的误差则在2mm至30mm之间。Kinect V2在垂直和平行于地面的方向上的精度分布表明,在3.5米内的绿色区域,误差小于2mm,黄色区域误差在2mm至4mm之间,红色区域误差大于4mm。因此,为了获得最佳效果,设计交互场景时应保持在黄色区域以内,若对精度要求极高,如控制机械,则最好在绿色区域进行交互。
Kinect V2的RGB视场为84.1 x 53.8度。关于FOV的建模和模型,可以参考相关资料。
4. Kinect和LeapMotion的精度比较
Kinect V1的误差随距离增加而指数性增加,在4米处误差接近0.2米,而Kinect V2的误差几乎不随距离增加而变化,其追踪准确度比Kinect V1提高了20%。Kinect V2能在户外进行人体跟踪,最远距离达到4米,近距离的精度是Kinect V1的两倍,在6米处则提高了数十倍。LeapMotion的控制器平均精度为0.7mm,无法达到声称的0.01mm。
5. Leap Motion控制器的精度分析
研究表明,Leap Motion控制器在静态设置下的精度与参考笔相结合时,可以获得小于0.2mm的与轴无关的偏差。在动态情况下,可以获得小于2.5mm的精度(平均1.2毫米),重复性平均小于0.17毫米。在实际条件下,无法实现0.01mm的理论精度,实际总平均精度为0.7mm。
与Kinect一代类似,深度相机的优点包括能够提供高精度的深度信息,适用于各种交互场景。然而,它们的缺点可能包括成本较高、对环境光线的敏感性以及可能存在的校准问题。
三、啥是KinectFusion
1、什么是KinectFusion?它是一种通过低成本深度摄像头获取的深度图进行三维重建的技术,即使Kinect设备已停产,其核心原理在三维重建领域的价值仍被广泛认可。本文主要围绕"KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera"这篇论文,梳理其关键步骤和算法流程。
2、深度图转换(Measurement):深度图转化为三维顶点和法向量,基于深度像素计算相机坐标系中的点云坐标。
3、相机跟踪(Pose Estimation):通过ICP算法确定相机的运动,找到匹配点并优化位姿。
4、体积融合(Volumetric Integration):利用体积表面建模,通过Truncated Signed Distance Functions(TSDFs)更新物体表面模型。
5、光线投射(Surface Prediction):通过光线追踪预测物体表面,用于渲染和相机追踪。
6、在实现过程中,可以参考Anatoly Baksheev的代码Nerei/kinfu_remake,但需要注意代码可能因年代问题存在配置问题,本文作者分享了自己配置和解决这些问题的经验。
7、最后,本文还提到了相关参考文献,如KinectFusion的原始论文和辅助阅读资源。