正则表达式匹配指定字符之间的内容
发布时间:2025-05-25 11:02:27 发布人:远客网络

一、正则表达式匹配指定字符之间的内容
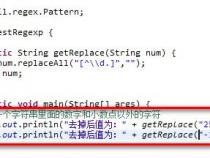
1、要在正则表达式中匹配两个指定字符(如<style>和</style>)之间的内容,并确保只匹配到第一次出现的</style>,您可以使用懒惰(非贪婪)匹配。以下是修改后的正则表达式:
2、(?<=<style>).*?(?=</style>)
3、这里的.*?是一个懒惰匹配,它会尽可能少地匹配字符,直到满足后面的条件。在这个例子中,它会匹配到第一次出现的</style>之间的内容。
4、请注意,某些正则表达式引擎可能不支持零宽度断言(如(?<=)和(?=))。在这种情况下,您可以使用以下正则表达式,并在处理匹配结果时删除<style>和</style>标签:
5、<style>(.*?)</style>
6、在这个例子中,.*?仍然是一个懒惰匹配,用于匹配两个标签之间的内容。
二、正则表达式:匹配中间有特定字符串字符串
1、正则表达式是一种强大的文本处理工具,用于匹配字符串中的特定模式。在本文中,我们讨论了一个简单的正则表达式模式:^.*\[2014\].*$。这个模式的功能是,如果字符串中包含"[2014]"这一特定子串,那么该字符串就会被认为是匹配成功的。
2、这里的中括号([])在正则表达式中是一个特殊字符,它通常用于字符集,表示匹配括号内的任何一个字符。但在这一模式中,我们需要匹配的是"[2014]"这个精确的字符串,所以需要使用反斜杠(\)进行转义,以避免它被解释为字符集。".*"则代表任何字符(包括换行符)可以出现任意次,星号(*)表示前面的元素可以出现0次或多次。
3、因此,总结起来,这个正则表达式的匹配规则非常直接:只要字符串中存在"[2014]",无论其前后有多少其他字符,该表达式都会匹配成功。这使得它在需要检查某个特定年份标志的场景下非常实用,比如在数据验证或文本处理中筛选2014年相关的信息。
三、python正则表达式如何截取字符串中间的内容
Python正则表达式截取字符串中间内容的方法
在Python中,我们可以使用正则表达式来截取字符串中间的内容。具体步骤如下:
1.导入re模块:Python的标准库re提供了正则表达式的功能。
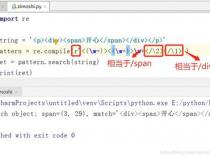
2.使用正则表达式:构建一个匹配目标字符串模式的正则表达式。例如,如果要匹配字符串中的特定部分,可以使用``来定义这部分的模式。比如使用模式 `"`"这个正则表达式用于匹配包含在双引号中的任意字符序列,`.`代表任意字符,`.`后面的问号表示非贪婪匹配。其中括号内的部分就是我们要截取的内容。
3.使用re模块的search或findall函数:通过调用这些函数来执行正则表达式的匹配操作。search函数会返回第一个匹配的字符串,而findall函数会返回所有匹配的字符串列表。根据实际需求选择使用哪个函数。然后使用返回的匹配对象的group方法获取中间的内容。例如,使用`group`或`group`来获取整个匹配或部分匹配的字符串。例如`match.group`用于获取整个匹配的字符串,而`match.group`用于获取第一个括号内的内容。若要使用正则表达式的所有结果,可以通过循环处理返回的匹配对象列表来实现。
#定义待匹配的字符串和正则表达式模式
text='这是一个包含中间内容的字符串示例:"中间内容"。'
pattern= r'""'#使用括号捕获中间内容部分
match= re.search#使用search方法找到第一个匹配项
if match:#如果找到匹配项则执行后续操作
#使用group方法获取中间内容部分
middle_content= match.group#获取第一个括号内的内容,即中间内容部分
在这个例子中,正则表达式`""`匹配的是包含在双引号中的内容,并使用非贪婪模式尝试匹配最少的内容。通过这种方式,我们可以方便地截取字符串中的特定部分。在实际应用中,可以根据需要调整正则表达式以适应不同的匹配需求。

![正则表达式对手机号的验证^[1][3-8]+d{9}](/d/file/2025-05-25/small7df853e5fee6078da1bac6c39a91e9e8.jpg)