正则表达式的零宽断言
发布时间:2025-05-24 18:18:19 发布人:远客网络

一、正则表达式的零宽断言
1、用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧:
2、(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
3、(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
4、假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\D)\D{3})+\b,用它对xxxxxxxxxx进行查找时结果是xxxxxxxxx
5、下面这个例子同时使用了这两种断言:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)
6、断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
二、正则表达式:零宽断言使用
首先介绍一下什么是正则表达式里的“零宽断言”。
零宽断言,是指这段正则匹配的不是某个字符串,而是字符串中的某个位置。
(?!....)匹配不含有该表达式的内容位置
(?=...)匹配的是表达式开始的位置
(?<=...)匹配的是表达式结束的位置
^((?!abc)(?!123).)+$
第一种写法:(?=.*abc.*)(?=.*123.*)(?=.*xyz.*)
第二种写法:^(?=.*abc)(?=.*123)(?=.*xyz).*$
3、有至少2对abc,和至少4对123,和至少3对xyz
第一种写法:(?=(.*abc.*){2})(?=(.*123.*){4})(?=(.*xyz.*){3})
第二种写法:^(?=(.*abc){2})(?=(.*123){4})(?=(.*xyz){3}).*$
三、JavaScript正则之零宽断言详解
1、定义1.1什么是断言?
断言用于查找某些内容或内容所在的位置,该内容或内容所在位置应满足一定的条件。
断言用于查找某些内容或内容所在的位置,该内容或内容所在位置应满足一定的条件。
那么什么叫零宽断言呢?零宽又是什么意思?
通俗的讲,零宽断言的字面意思是匹配宽度为零的断言。
所谓匹配的宽度为零,就是说这种断言在工作时:
这三个点,既展示了零宽断言的定义,也说明了零宽断言的两个特性:非捕获性和不吃字符
这两个特性我放在下个章节来讲。
因为后面有一些案例代码,为了能让大家更清楚的理解代码,所以这个章节先讲一下零宽断言表达式
相信你看这个表格就能理解十之八九了,我这里举个小例子
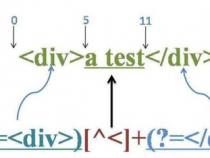
在字符串'北京市(朝阳区)(西城区)(海淀区)'中,取出没有被()包裹的字符北京市
要求是取出没有被()包裹的字段,那这个字段的后面紧跟着的一定是(,就是这么简单。
那我可以写一个零宽断言表达式varreg=/.*?(?=\()/来看看能不能满足需求:
简单做个解释,这个reg可以看作两部分,分别是.*?和(?=\()
假设你已经知道了在正则表达式当中:
.代表匹配除了换行和行结束符的任意字符
*代表匹配任意次数,保证我们得到的是北京市而不是市这个单字
?代表对多个连续的值,要么匹配0次,要么匹配1次,最多匹配一次
那么前一部分就可以匹配给定字符中包含的所有字符,而后一部分零宽断言则给匹配添加了条件,要求匹配的内容后面跟着(,于是我们就能得到想要的结果
你可能有疑问,如果我正则写成这个样子/.*(?=\()/,为什么结果就不对?
我首先说明,这所以在这里加入贪婪模式与非贪婪模式,是因为上面的案例是正向(正预测)先行断言的案例而网上有些人说正向零宽断言是从右向左执行的,我就不批判了,只希望大家能够擦亮眼睛。
那么为什么少了一个问号,得出了全然不同的结果呢?
上面说了,?在这个表达式里,表示要么不匹配,要么最多匹配一次,这就是非贪婪模式
而不添加?,表达式以贪婪模式运行。什么是贪婪模式?就是尽可能多的去匹配,匹配到了还去匹配,贪得无厌,一直匹配到字符串的末尾
因为字符串中有三个(,贪婪模式下会一直匹配到字符串结尾,就会得到北京市(朝阳区)(西城区)这个结果
第一章已经说了零宽断言定义和它的特性,这里来详细讲讲它的这两个特性:非捕获特性和不吃字符特性
这是零宽断言的一个基本特性,非捕获特性
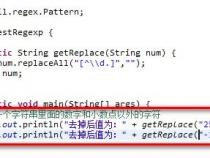
我假设你知道在正则表达式中可以使用()来进行分组取值,一个()就是一个分组。所以我这里举一个使用分组取值替换字符的例子:
上面的代码,我使用分组来获取W并将它成功替换成正确的字符Hello,world!现在改一下代码,看看会怎样:
很显然,虽然str.match方法返回了正确的结果,但是替换并没有实现想要的效果并且这个结果和使用非捕获性分组是一致的:
虽然第二个代码片段也使用了()进行分组,但因为这个分组使用的是零宽断言的表达式,正则并没有返回针对$1的引用,所以替换是不能成功的。
由此,这个例子很好的证明了零宽断言具有非捕获的特性。
零宽断言的另一个特性,是不吃字符。
这里的不吃字符不是寻常意义上的吃,而是说零宽断言本身不占据查找位置,它不算是要被查找的内容,因此,正则表达式并不匹配零宽断言本身。
这个概念,是正则对象的一个属性,叫做lastIndex。它规定了正则表达式下一次匹配的起始位置。
如果我们使用正则的方法如test,exec等方法,就能清楚的看到lastIndex的影响:
这段代码的返回结果,相信很多人都会判断错误,我直接把结果放在下面
["a","a",index:0,input:"a",groups:undefined]
null["c","c",index:0,input:"c",groups:undefined]null["e","e",index:0,input:"e",groups:undefined]
这就是lastIndex在搞怪,简单的说,当正则全局匹配成功时,lastIndex就指向了匹配成功的字符索引,再次匹配时,则从lastIndex位置继续向后匹配
注意数组中每一项的长度都是1,如果lastIndex的值大于等于1,自然匹配的结果就是null;没有匹配到结果,lastIndex的值就成了默认值0,下一次的匹配就是非null的结果了。
所以我们得出结论,lastIndex随着匹配结果的变化而变化
下面我们使用零宽断言的方式来试试。
["",index:0,input:"a",groups:undefined]
["",index:0,input:"b",groups:undefined]["",index:0,input:"c",groups:undefined]["",index:0,input:"d",groups:undefined]["",index:0,input:"e",groups:undefined]
而因为正则表达式不匹配零宽断言本身,因此零宽断言不会改变lastIndex的值,所以它返回了空值“”,却没有完全返回空(null)。
如果你依然不能理解,尝试看看下面这段代码:
这段代码十分简单,结果只会匹配一项
["he",index:0,input:"hello,thisishierry,andthatishi,thereishandsome",groups:undefined]
很明显,reg匹配的时候越过了表达式中间的i,只匹配了h和e,这能更明显的体现不吃字符的特性。
通常,零宽断言依据断言的方式被分为四类,分别是:
零宽度正向先行断言(也叫正预测先行断言)
零宽度负向先行断言(也叫负预测先行断言)
零宽度正向后发断言(也叫正回顾后发断言)
零宽度负向后发断言(也叫负回顾后发断言)
在javascript这门语言中,只支持先行断言,不支持后发断言
正向断言是当某个位置前面或者后面的内容要匹配表达式exp,才会返回非空的结果
负向断言是当某个位置前面或者后面的内容不匹配表达式exp,才会返回非空的结果
先行断言是用某个位置后面的内容与表达式exp进行匹配
后发断言是用某个位置前面的内容与表达式exp进行匹配
衣服38元、鞋子62元、剪发15元、吃饭45元、打车30元、冰激凌10元,对花费的金钱求和?
'ilikeeating、sleeping、seemoviesand'中拿到以ing结尾的动作单词
这两个例子比较简单,就不坐过多解释了。
举个例子,也是我在面试题中找到的
测试一个文件是否是.css后缀,但又不能是.min.css,如:
test('a.min.css');//falsetest('b.css');//truetest('c.mining.css');//true
答案:/^(?!.*\.min\.css$).+\.css$
这里先对以任意字符开头结尾为.min.css的文件名做了排除,在剩余的文件名中查找以.css为结尾的文件名
创作不易,如果这篇文章帮助到了你,请动动手指点个赞再走吧~