python入门问题,关于正则表达式。求高手通俗解答。
发布时间:2025-05-24 16:10:25 发布人:远客网络
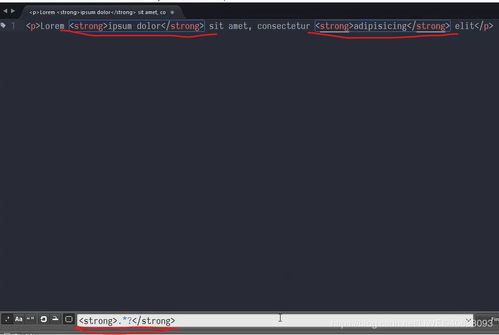
一、python入门问题,关于正则表达式。求高手通俗解答。
pattern=r'([1-9]{1,3}(\.[0-9]{1,3}){3})'
[1-9]{1,3}表示匹配由1-9之间任意数组成的1位、2位或3位数,如1,12,123
\.[0-9]{1,3}表示匹配1个点接由0-9之间任意数组成的1位、2位或3位数,如.1,.12,.123
(\.[0-9]{1,3}){3}表示\.[0-9]{1,3}的匹配条件重复3次,如.1.2.3,.1.12.123,168.1.1
([1-9]{1,3}(\.[0-9]{1,3}){3})表示匹配1-9之间任意数组成的1位、2位或3位数+1个点接由0-9之间任意数组成的1位、2位或3位数* 3次,所以可以匹配127.0.0.1,192.168.1.66
()仅仅表示括号内的匹配项作为一组匹配,不会影响匹配的条件,
二、python3 正则表达式如何实现中文模糊匹配替换并输出
1、要使用正则表达式实现中文模糊匹配替换并输出,你可以使用 Python的 re模块。以下是一个示例代码,读取一个名为 input.txt的文件,将其中的"竹某婵"或"竹婵某"替换为"竹婵婵",然后将结果保存到一个名为 output.txt的新文件中:
2、def replace_pattern(match_obj):
3、with open("input.txt","r", encoding="utf-8") as file:
4、#使用正则表达式进行模糊匹配替换
5、pattern= r"竹(?:某|婵)(?:婵|某)"
6、replaced_content= re.sub(pattern, replace_pattern, content)
7、with open("output.txt","w", encoding="utf-8") as file:
8、在这个例子中,正则表达式 r"竹(?:某|婵)(?:婵|某)"用于匹配"竹某婵"或"竹婵某"。(?:...)是一个非捕获组,它表示匹配其中的任意一个字符,但不会捕获该组。这里的组分别包含"某"和"婵",因此可以匹配"竹某婵"或"竹婵某"。接下来,re.sub函数用于替换匹配到的字符串。这里我们提供了一个替换函数 replace_pattern,它直接返回"竹婵婵"。最后,将替换后的内容写入一个名为 output.txt的新文件。
9、如果要实现匹配任意特定中文字符,可以使用 Unicode的中文字符范围。以下是修改后的示例代码,可以将"竹某婵"或"竹婵某"替换为"竹婵婵",其中"某"为任意中文字符:
10、def replace_pattern(match_obj):
11、with open("input.txt","r", encoding="utf-8") as file:
12、#使用正则表达式进行模糊匹配替换
13、pattern= r"竹[\u4e00-\u9fa5]婵|竹婵[\u4e00-\u9fa5]"
14、replaced_content= re.sub(pattern, replace_pattern, content)
15、with open("output.txt","w", encoding="utf-8") as file:
16、在这个例子中,正则表达式 r"竹[\u4e00-\u9fa5]婵|竹婵[\u4e00-\u9fa5]"用于匹配"竹某婵"或"竹婵某",其中"某"为任意中文字符。[\u4e00-\u9fa5]用于匹配任意一个中文字符。接下来,re.sub函数用于替换匹配到的字符串。这里我们提供了一个替换函数 replace_pattern,它直接返回"竹婵婵"。最后,将替换后的内容写入一个名为 output.txt的新文件。
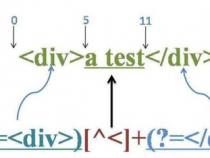
三、Python正则表达式的几种匹配用法
下面列出: 1.测试正则表达式是否匹配字符串的全部或部分regex=ur""#正则表达式
if re.search(regex, subject): do_something()else: do_anotherthing() 2.测试正则表达式是否匹配整个字符串 regex=ur"/Z"#正则表达式末尾以/Z结束
if re.match(regex, subject): do_something()else: do_anotherthing() 3.创建一个匹配对象,然后通过该对象获得匹配细节(Create an object with details about how the regex matches(part of) a string) regex=ur""#正则表达式
match= re.search(regex, subject)if match:# match start: match.start()# match end(exclusive): atch.end()# matched text: match.group() do_something()else: do_anotherthing() 4.获取正则表达式所匹配的子串(Get the part of a string matched by the regex) regex=ur""#正则表达式
match= re.search(regex, subject)if match: result= match.group()else: result="" 5.获取捕获组所匹配的子串(Get the part of a string matched by a capturing group) regex=ur""#正则表达式
match= re.search(regex, subject)if match: result= match.group(1)else: result="" 6.获取有名组所匹配的子串(Get the part of a string matched by a named group) regex=ur""#正则表达式
match= re.search(regex, subject)if match:result= match.group"groupname")else:result="" 7.将字符串中所有匹配的子串放入数组中(Get an array of all regex matches in a string) result= re.findall(regex, subject) 8.遍历所有匹配的子串(Iterate over all matches in a string) for match in re.finditer(r"<(.*?)/s*.*?//1>", subject)# match start: match.start()# match end(exclusive): atch.end()# matched text: match.group() 9.通过正则表达式字符串创建一个正则表达式对象(Create an object to use the same regex for many operations) reobj= re.compile(regex) 10.用法1的正则表达式对象版本(use regex object for if/else branch whether(part of) a string can be matched) reobj= re.compile(regex)if reobj.search(subject): do_something()else: do_anotherthing() 11.用法2的正则表达式对象版本(use regex object for if/else branch whether a string can be matched entirely) reobj= re.compile(r"/Z")#正则表达式末尾以/Z结束
if reobj.match(subject): do_something()else: do_anotherthing() 12.创建一个正则表达式对象,然后通过该对象获得匹配细节(Create an object with details about how the regex object matches(part of) a string) reobj= re.compile(regex) match= reobj.search(subject)if match:# match start: match.start()# match end(exclusive): atch.end()# matched text: match.group() do_something()else: do_anotherthing() 13.用正则表达式对象获取匹配子串(Use regex object to get the part of a string matched by the regex) reobj= re.compile(regex) match= reobj.search(subject)if match: result= match.group()else: result="" 14.用正则表达式对象获取捕获组所匹配的子串(Use regex object to get the part of a string matched by a capturing group) reobj= re.compile(regex) match= reobj.search(subject)if match: result= match.group(1)else: result="" 15.用正则表达式对象获取有名组所匹配的子串(Use regex object to get the part of a string matched by a named group) reobj= re.compile(regex) match= reobj.search(subject)if match: result= match.group("groupname")else: result="" 16.用正则表达式对象获取所有匹配子串并放入数组(Use regex object to get an array of all regex matches in a string) reobj= re.compile(regex) result= reobj.findall(subject) 17.通过正则表达式对象遍历所有匹配子串(Use regex object to iterate over all matches in a string) reobj= re.compile(regex)for match in reobj.finditer(subject):# match start: match.start()# match end(exclusive): match.end()# matched text: match.group()字符串替换 1.替换所有匹配的子串#用newstring替换subject中所有与正则表达式regex匹配的子串
result= re.sub(regex, newstring, subject) 2.替换所有匹配的子串(使用正则表达式对象) reobj= re.compile(regex) result= reobj.sub(newstring, subject)字符串拆分 1.字符串拆分 result= re.split(regex, subject) 2.字符串拆分(使用正则表示式对象) reobj= re.compile(regex) result= reobj.split(subject)


![正则表达式中 '-' 和 [-],有什么区别](/d/file/2025-05-24/small9714651ec386342f0b7f798b24b42bed.jpg)
