MySQL checkpoint机制详解
发布时间:2025-05-24 11:21:34 发布人:远客网络
一、MySQL checkpoint机制详解
1、MySQL为了确保数据安全,采取了多种checkpoint机制。InnoDB引擎通过Log Sequence Number(LSN)来标记数据版本,监控数据库变更。LSN用于跟踪日志和页面的版本状态,每项操作或页面更新都附有LSN,以便在系统恢复时追踪数据变更。
2、MySQL通过两种主要的checkpoint方法来管理数据和日志:flush_lru_list和Dirty Page。flush_lru_list操作在特定条件下触发,如当Buffer Pool的LRU空闲列表资源不足时,会清除列表中的页面,以确保有足够的空间处理新请求。而Dirty Page则在页面脏数据累积过多时触发,通过调整多个参数(如innodb_max_dirty_pages_pct_lwm、innodb_flush_neighbors、innodb_lru_scan_depth)来控制页面刷新频率,以平衡内存和磁盘之间的数据同步。
3、Adaptive Flushing机制在高写入负载下自动调整刷新策略,通过监控日志使用情况,以优化数据刷新效率。innodb_idle_flush_pct参数可以限制空闲时段的刷新速率,以延长SSD等固态存储设备的寿命。此外,Redo日志管理也至关重要,它负责记录数据库的事务变更,并在系统恢复时应用这些变更,确保数据一致性。
4、在面对高负载或复杂应用时,合理调整checkpoint相关参数是优化MySQL性能的关键。通过监控和调优这些机制,可以实现数据高效同步,同时避免性能瓶颈。对于数据库管理员而言,了解并应用这些机制不仅能提升系统稳定性,还能显著提高数据处理效率。
二、造成数据库checkpoint时间较长的可能原因有哪些
1、系统补丁没打完全,导致关于系统数据库在执行io操作时,写数据的时间较长,且占用率较高,导致数据库checkpoint时间较长。
2、informix的onconfig中的某些参数(如:buffer)配置不规范或者不符合现网需求,导致系统性能下降,不能发挥数据库的性能。
3、数据库系统未对某些大数据量表进行优化,导致执行checkpoint的时间较长。
三、谈谈MySQL的WAL、LSN、checkpoint
1、MySQL中的WAL(Write-Ahead Logging,预写式日志)技术是一种关键的数据持久化策略,它确保修改的数据在正式写入磁盘前先写入缓存。这种技术需要两次磁盘写操作:首先,数据从内存写入磁盘的文件系统缓存,执行顺序IO;然后,从缓存中持久化到磁盘,进行随机IO。WAL的优势在于通过顺序写入,减少了随机写磁盘的IO消耗。
2、LSN(Log Sequence Number,日志序列号)则用于标识Redo Log(重做日志)的顺序,每个LSN占用8字节,随着日志写入而递增。LSN的使用非常广泛,如用于计算写入的日志量,判断数据页是否需要恢复,以及记录最近一次刷盘(checkpoint)的页。数据库通过比较数据页和redo log的LSN,确保数据完整性和一致性。
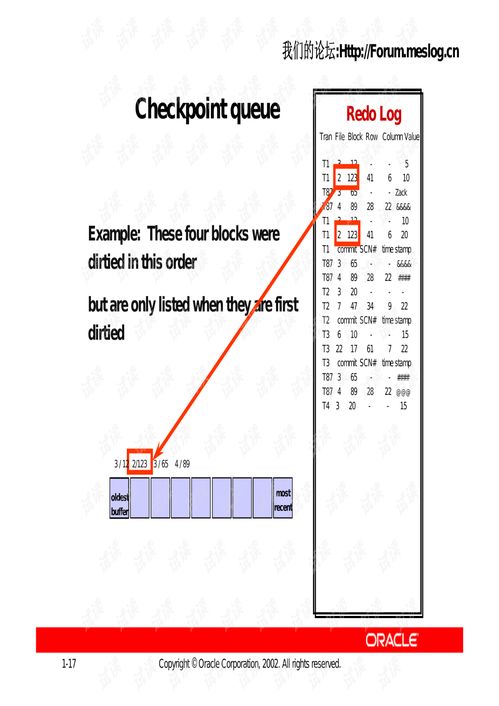
3、Checkpoint技术是为了解决缓冲池和redo log容量有限的问题。它在特定时刻将脏页(未写回磁盘的更改)刷新回磁盘,由LSN值标识这个时间点。Checkpoint分为两种类型,数据库关闭时使用Sharp Checkpoint,运行时使用Fuzzy Checkpoint,以确保数据的完整性。检查点触发时机取决于脏页数量、LRU列表和redo log空间,以保持缓冲区的空闲页数量。
4、LSN与checkpoint紧密相连,它们共同确定事务的开始和恢复路径。在重启时,数据库根据redo log的完整性和data disk lsn(数据磁盘LSN)与checkpoint lsn(检查点LSN)的比较,决定从何处恢复。如果checkpoint lsn小于data disk lsn,说明部分数据未完成刷盘,恢复将从checkpoint lsn之后的LSN开始。
5、总的来说,WAL、LSN和checkpoint共同确保了MySQL数据库在高并发和故障恢复时的数据一致性,通过细致的逻辑和协调,实现了数据的可靠存储和高效管理。