在Python中使用pandas进行文件读取和写入方法详解
发布时间:2025-05-22 07:37:17 发布人:远客网络
一、在Python中使用pandas进行文件读取和写入方法详解
Pandas是 Python中强大的数据处理库,可轻松操作标记和时间序列数据,并提供统计和绘图功能。其关键功能之一是读写多种文件格式,如 Excel、CSV等,使数据处理更高效。
首先,确保安装了 Pandas。若使用 Anaconda,此步骤可省略。
数据准备阶段,使用 20个国家/地区相关数据,为分析打下基础。观察数据中缺失值,利用嵌套字典记录,便于后续处理。
利用 pandas DataFrame加载数据,简化数据结构与操作。
对于 CSV文件,使用 Pandas的 to_csv()方法将数据写入文件,灵活控制索引是否保留。读取 CSV文件时,利用 read_csv()方法加载数据,可通过 index_col参数指定索引列。
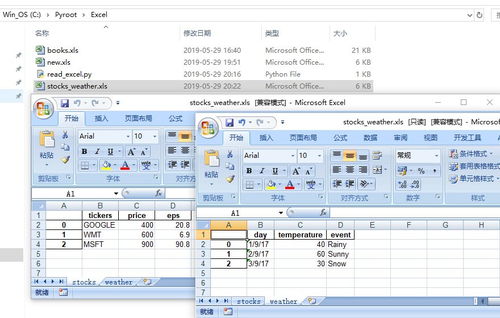
Excel文件操作类似,通过 to_excel()和 read_excel()方法,实现读写。在进行 Excel操作前,可能需要安装额外的三方库。
Pandas IO API提供了一整套文件操作接口,支持多种文件格式。使用 to_()方法将数据写入不同格式文件,如 JSON、HTML等。读取文件时,相应方法如 read_json()、read_html()等。
CSV文件写入与读取中,.to_csv()方法需要指定文件路径,并确保后缀为.csv。处理缺失值时,使用 pandas自带的 nan表示,可利用 na_rep参数自定义缺失值标记,保持数据完整性。
读取文件时,Pandas默认将空字符串和特殊缺失值视作缺失,可通过 keep_default_na和 na_values参数自定义行为。读取 JSON文件时,注意 JSON文件顺序可能与 CSV不同。
HTML文件通过 to_html()方法生成,提供可视化体验。保存 HTML时,可调整参数以优化输出。
Excel文件操作中,to_excel()方法可指定工作表名称和起始单元格位置,灵活控制数据布局。
SQL数据库交互,使用 Pandas与 SQLAlchemy库结合,实现数据读写,支持 SQLite等数据库。
Pickle文件用于保存 Python对象,.to_pickle()和 read_pickle()方法实现序列化与反序列化。
处理大文件时,Pandas提供多种策略减少磁盘使用,如压缩文件、选择特定列和行、使用更精简数据类型和分块处理数据。
压缩文件如.gz、.bz2、.zip和.xz,Pandas可自动识别。使用 read_csv()读取压缩文件时,可指定压缩类型。
数据列选取灵活,可以使用 usecols参数选择所需列,或通过列索引读取。在机器学习与深度学习场景下,仅加载必要数据以优化计算性能,通过选择行数据实现。
强制使用较低精度数据类型,如从 64位浮点数转换为 32位浮点数,可以显著减少内存消耗,提升处理效率。
数据块遍历通过 chunksize参数实现,将大文件拆分小块处理,结合 for循环汇总数据,优化内存使用。
二、#python#pandas# 读取很大的xlsx效率速度太慢
好消息传来,自pandas 2.2版本以后,calamine引擎的出现为处理大型xlsx文件的效率问题带来了希望。升级到2.2.1版本后,我发现了一个新的引擎选项,特别适用于xlsx文件读取。尽管数据规模大约在200万至800万行,10几列左右,之前使用openpyxl的load_workbook进行只读操作并转存为csv,过程较为繁琐,耗时几十秒尚可接受。
然而,xlsx_csv虽然读取速度较快,但不支持自定义分隔符为\t,这在文本字段包含逗号的情况下会带来困扰。我仍在寻找解决方案,特别是面对大量文本数据和批量处理的需求。
回溯到2022年3月,我曾遇到读取大文件(每份约130Mb)的问题,尤其是处理一个典型文件,584k行,15列,127Mb大小的xlsx,数据集中在Sheet1,14列为文本格式,1列为uint32。由于数据来源复杂,从合作伙伴的数据库导出后,xlsx格式并非标准,且无法直接要求他们转为csv。
在测试中,我记录了不同方法的执行时间:使用xlrd 1.2.0需8分钟10秒,xlrd3稍有改善,3分钟17秒。openpyxl的load_workbook在只读和data_only=True的情况下,虽然初始读取速度很快,但后续转换为dataframe会明显变慢。pandas 1.4.1的read_xlsx engine=openpyxl耗时4分钟33秒。modin[ray]的读取速度理论上更快,但由于bug,只读部分数据,且输出格式为modin格式,需要额外转换。xlsx到csv的工具xlsx_csv和xlsx2csv中,xlsx2csv的转换时间更短,分别为11.6秒和2.5秒。
尽管有一些工具可供选择,但寻找最佳解决方案的过程仍在继续,尤其是对于modin DataFrame的转换,如果能将其转换为标准的pd.DataFrame,将大大提高处理效率。
三、pandas是什么意思中文翻译
1、pandas是什么意思中文翻译是“熊猫”,但在计算机科学领域,指的是一种基于Python语言的数据处理和分析库。它能够对数据进行读取、清洗、转换和聚合等操作,并提供了数据可视化的功能。pandas最早由Wes McKinney开发,现在已经成为Python数据分析中最流行的库之一。
2、Pandas的主要数据结构是Series和DataFrame,分别对应于一维的序列和二维的表格。它们可以支持许多操作,如索引、切片、过滤等,还能进行数据合并、重塑、聚合等高级操作。除了数据处理,Pandas还提供了绘图工具,可以生成各种统计图表,如条形图、散点图、折线图等。
3、在数据科学和机器学习领域,Pandas的应用十分广泛。通过Pandas能够加载和处理不同来源的数据,如CSV、Excel、数据库等,并进行预处理以进行后续的机器学习任务。Pandas的高效性、灵活性和易用性使其成为Python数据科学中不可或缺的一部分。