如何使用adb命令查看android中的数据库
发布时间:2025-05-23 18:40:27 发布人:远客网络
一、如何使用adb命令查看android中的数据库
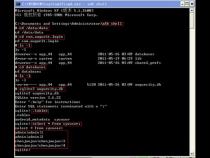
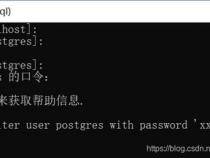
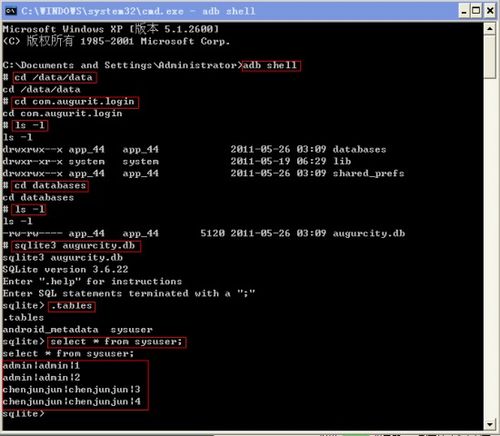
1、1,进入到控制台中,输入adb shell,进入到命令模式的环境中
2、3,选择你所在的数据库文件,比如我的com.android.homework,输入命令:cd com.android.homework
3、4,可以使用ls-l命令查看当前目录中的文件
4、5,输入: cd databases进入到数据库文件中
5、6, ls-l显示你数据库中你建立的数据库
6、7, sqlite3 info.db进入到你选择的数据库中
7、9, select* from table_name;s可以查看整个表的信息
8、10,使用其他的SQL语句可以进一步对表进行操作,注意SQL语句必须用分号(;)结尾
二、如何使用adb命令查看和更新数据库
1、要在Android设备上使用ADB命令查看数据库,首先需要打开控制台并输入“adb shell”进入命令模式。接着,通过“cd/data/data/”切换到应用的私有目录。例如,要查看“com.android.homework”应用的数据库,需要输入“cd com.android.homework”。使用“ls-l”可以列出当前目录下的文件。进一步进入“databases”目录,使用“ls-l”命令查看数据库文件。若需进入特定数据库,可以使用“sqlite3 info.db”命令,其中“info.db”为数据库文件名。通过“.tables”命令可查看表名,使用“select* from table_name;”可以查看表中的所有数据。若操作更复杂的SQL查询,记得在语句结尾加上分号。
2、如果只是简单查看数据库,可能确实不需要如此繁琐的步骤。不过,了解这些命令能帮助你更深入地管理与调试应用中的数据库。例如,可以通过SQL命令修改数据或检查表结构。这些基础命令对于开发人员来说非常有用,能够快速定位和解决问题。
3、值得注意的是,直接在命令行操作数据库时需谨慎,因为错误的命令可能会导致数据丢失或损坏。在执行任何操作之前,确保已经备份了重要数据。此外,对于不熟悉SQL语句的用户,建议先学习一些基本的SQL命令,以便能够有效地使用这些工具。
4、通过这些步骤,你可以直接在设备上查看和操作数据库,而无需通过应用界面。这对于开发调试或紧急修复问题尤其有用。不过,如果只是偶尔查看数据,可能更简单的方式是通过开发工具或第三方应用程序访问数据库。
5、总之,掌握ADB命令对于Android开发者来说是一项重要的技能。通过这些命令,你可以直接在设备上进行数据库操作,从而提高开发效率和灵活性。
三、adbmrio数据库怎么计
目标:主要用于数据分析,后端支持BI报表和数据大屏。mysql协议,学习成本低。
维度表组(系统自带):自带维度概念的表(例如省份表等),可以放到维度表组下
普通表组:一般会把需要关联的普通表放在相同普通表组中,建议这个表组中的所有普通表的一级分区数一致,join性能会有很大提升。
普通表:分区表。默认一级分区,可创建二级分区。
分区:普通表才有,一级分区采用hash算法,单表数据量在60亿以内,推荐。
主键:表必须包含主键。由业务id、一级分区键组成,有些情况业务id与一级分区相同。对于记录量特别大的表,从存储空间和insert性能考虑,一定要减少主键的字段数。
数据库创建完毕后,系统会默认创建一个维度表组,所有维度相关的表,可以放到维度表组下。
特殊字段:timestamp timestamp AnalyticDB精确到秒,MySQL支持自定义精度
navicat连接后,无法显示建表语句。
输入导入方式:1、DTS;2、数据集成。
insert插入显示延迟5-10S,可单独提工单修改。
更新数据:AnalyticDB不支持update操作,可以通过主键覆盖的方式进行insert操作来实现和update同等的功能。
数据导出功能较弱,dump方式到OSS/MaxCompute
推荐权限定义方式:
AnalyticDB内部采用列存方式,通过单列高效过滤后,可直接通过内部记录指针扫描其他列值,减少其他列的索引查询开销。
普通表join普通表,尽量包含分区列join条件,如果不包含则,尽量通过where条件过滤掉多余的数据。
默认是全索引,建表成功后,某列删除索引操作,需提工单解决。
二级分区用于删除数据,对于“回溯表”类场景,避免手动删除。
1、分布均匀,避免数据倾斜。park_record_id?
2、建议选择一级分区列的数据类型为tinyint、smallint、int、bigint或者varchar。
3、如果是多个普通表(不包括维度表)JOIN,则选择参与JOIN的列作为分区列。park_record_id?park_id?
4、选择GROUP BY或DISTINCT包含的列作为分区列
5、如果常用的SQL包含某列的等值或IN查询条件,则选择该列作为分区列。以下列子则选择id作为分区列。
select* from table where id=123 and…;
select* from table where user in(1, 2,3);
使用场景以管理员使用为主,范围扫描较多,park_id分区优势更大。
历史单条数据,管理员查询较少,可忽略。
多参考设计样例:
为满足高QPS,从设计上采用大宽表、冗余字段,并且避免表关联。
场景描述:全量sql,查询频率低,以区域统计查询为主。
最佳实践:区域查询、车场查询读扩大,数据分布均匀+聚集列效果。缺点:
PRIMARY KEY(park_record_id,TS)
PARTITION BY HASH KEY(park_record_id) PARTITION NUM 128
SUBPARTITION OPTIONS(available_partition_num= 300)
CLUSTERED BY(area_id,park_id)
是否支持修改表的一级分区数:当前不支持动态修改,只能删表重建。