Java中的actionlistener是什么意思,有什么作用,详细点为好!
发布时间:2025-05-22 17:02:29 发布人:远客网络
一、Java中的actionlistener是什么意思,有什么作用,详细点为好!
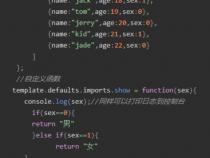
actionlistener字面上理解就是动作监听器。
它是一个接口,在实现此接口的类中,你可以给需要关注其动作的组件(如Button)添加监听器(addActionListener(this);),之后在事件处理方法(public void actionPerformed(ActionEvent event){})中,对每个事件进行不同处理。
给你个例子吧,是我自己写的一个记事本:
public class MainClass extends JFrame implements ActionListener{
JMenu fileMenu,editMenu,helpMenu;
JMenuItem打开O,新建N,保存S,另存A,剪切T,复制C,粘贴P,关于A;
public MainClass(){//构造方法
panel=(JPanel)getContentPane();
fileMenu= new JMenu("文件F");
fileMenu.setMnemonic('F');
editMenu= new JMenu("编辑E");
editMenu.setMnemonic('E');
helpMenu= new JMenu("帮助H");
helpMenu.setMnemonic('H');
打开O= new JMenuItem("打开O");
打开O.setMnemonic('O');
新建N= new JMenuItem("新建N");
新建N.setMnemonic('N');
保存S= new JMenuItem("保存S");
保存S.setMnemonic('S');
另存A= new JMenuItem("另存A");
另存A.setMnemonic('A');
剪切T= new JMenuItem("剪切C");
剪切T.setMnemonic('t');
复制C= new JMenuItem("复制C");
复制C.setMnemonic('C');
粘贴P= new JMenuItem("粘贴P");
粘贴P.setMnemonic('P');
关于A= new JMenuItem("关于A");
关于A.setMnemonic('A');
panel.add("Center", textArea);
打开O.addActionListener(this);
新建N.addActionListener(this);
保存S.addActionListener(this);
另存A.addActionListener(this);
剪切T.addActionListener(this);
复制C.addActionListener(this);
粘贴P.addActionListener(this);
关于A.addActionListener(this);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
public void actionPerformed(ActionEvent event){//处理事件
if(event.getSource()==打开O){//处理打开
JFileChooser jfc= new JFileChooser();
tempFile= jfc.getSelectedFile();
fis= new FileReader(tempFile);
}catch(Exception ex){ex.printStackTrace();}
if(event.getSource()==新建N){//处理新建
if(event.getSource()==保存S){//处理保存
JFileChooser jfc= new JFileChooser();
tempFile= jfc.getSelectedFile();
FileWriter fos= new FileWriter(tempFile);
}catch(Exception ex){ex.printStackTrace();}
FileWriter fos= new FileWriter(tempFile);
}catch(Exception ex){ex.printStackTrace();}
if(event.getSource()==另存A){//处理另存
JFileChooser jfc= new JFileChooser();
tempFile= jfc.getSelectedFile();
FileWriter fos= new FileWriter(tempFile);
}catch(Exception ex){ex.printStackTrace();}
if(event.getSource()==剪切T){//处理剪切
if(event.getSource()==复制C){//处理复制
if(event.getSource()==粘贴P){//处理粘贴
if(event.getSource()==关于A){//处理关于
textArea.setText("Manifest-Version: 1.0\n"+
public static void main(String []args){//主函数
二、java的getSource()方法
在我这里没有出现任何错误,点击"退出"就可以退出.
因为你使用的事件触发方式是实现ActionListener接口,然后在事件触发方法中,判断事件源来进行功能分类的, getSource是判断这个事件是由哪个组件发出的,如果是btn这个按钮发出的,就退出系统,如果不是btn发出的,就不执行操作,这里之后一个按钮注册了ActionListener,所以效果不明显,如果你再为另外一个按钮注册ActionListener的话(比如加一个最大化的功能按钮),就要用getSource来区分产生事件的按钮,然后来区分执行的功能了.
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
public class frame extends Frame implements ActionListener{
Button btn= new Button("退出"), btn1= new Button("最大化");
btn.setBackground(Color.orange);
btn.setForeground(Color.RED);
add(btn, BorderLayout.CENTER);
add(btn1, BorderLayout.SOUTH);
btn1.addActionListener(this);
public void actionPerformed(ActionEvent e){
} else if(e.getSource()== btn1){
this.setExtendedState(Frame.MAXIMIZED_BOTH);
public static void main(String args[]){
三、规则引擎 java 怎么执行动作
Java规则引擎是一种嵌入在 Java程序中的组件,它的任务是把当前提交给引擎的 Java数据对象(原料)与加载在引擎中的业务规则( app)进行测试和比对,激活那些符合当前数据状态下的业务规则,根据业务规则中声明的执行逻辑,触发应用程序中对应的操作。
目前, Java社区推动并发展了一种引人注目的新技术——Java规则引擎( Rule Engine)。利用它就可以在应用系统中分离商业决策者的商业决策逻辑和应用开发者的技术决策,并把这些商业决策放在中心数据库或其他统一的地方,让它们能在运行时可以动态地管理和修改,从而为企业保持灵活性和竞争力提供有效的技术支持。
1、基于规则的专家系统( RBES)简介
Java规则引擎起源于基于规则的专家系统,而基于规则的专家系统又是专家系统的其中一个分支。专家系统属于人工智能的范畴,它模仿人类的推理方式,使用试探性的方法进行推理,并使用人类能理解的术语解释和证明它的推理结论。为了更深入地了解 Java规则引擎,下面简要地介绍基于规则的专家系统。 RBES包括三部分:Rule Base( knowledge base)、 Working Memory( fact base)和 Inference Engine。它们的结构如下系统所示:
如图 1所示,推理引擎包括三部分:模式匹配器( Pattern Matcher)、议程( Agenda)和执行引擎(Execution Engine)。推理引擎通过决定哪些规则满足事实或目标,并授予规则优先级,满足事实或目标的规则被加入议程。模式匹配器决定选择执行哪个规则,何时执行规则;议程管理模式匹配器挑选出来的规则的执行次序;执行引擎负责执行规则和其他动作。
和人类的思维相对应,推理引擎存在两者推理方式:演绎法( Forward-Chaining)和归纳法( Backward-Chaining)。演绎法从一个初始的事实出发,不断地应用规则得出结论(或执行指定的动作)。而归纳法则是根据假设,不断地寻找符合假设的事实。 Rete算法是目前效率最高的一个 Forward-Chaining推理算法,许多 Java规则引擎都是基于 Rete算法来进行推理计算的。
(1)将初始数据( fact)输入 Working Memory。
(2)使用 PatternMatcher比较规则库( rule base)中的规则( rule)和数据( fact)。
(3)如果执行规则存在冲突( conflict),即同时激活了多个规则,将冲突的规则放入冲突集合。
(4)解决冲突,将激活的规则按顺序放入 Agenda。
(5)使用执行引擎执行 Agenda中的规则。重复步骤 2至 5,直到执行完毕所有 Agenda中的规则。
上述即是规则引擎的原始架构, Java规则引擎就是从这一原始架构演变而来的。
规则引擎是一种根据规则中包含的指定过滤条件,判断其能否匹配运行时刻的实时条件来执行规则中所规定的动作的引擎。与规则引擎相关的有四个基本概念,为更好地理解规则引擎的工作原理,下面将对这些概念进行逐一介绍。
信息元是规则引擎的基本建筑块,它是一个包含了特定事件的所有信息的对象。这些信息包括:消息、产生事件的应用程序标识、事件产生事件、信息元类型、相关规则集、通用方法、通用属性以及一些系统相关信息等等。
2)信息服务( InformationServices)
信息服务产生信息元对象。每个信息服务产生它自己类型相对应的信息元对象。即特定信息服务根据信息元所产生每个信息元对象有相同的格式,但可以有不同的属性和规则集。需要注意的是,在一台机器上可以运行许多不同的信息服务,还可以运行同一信息服务的不同实例。但无论如何,每个信息服务只产生它自己类型相对应的信息元。
顾名思义,规则集就是许多规则的集合。每条规则包含一个条件过滤器和多个动作。一个条件过滤器可以包含多个过滤条件。条件过滤器是多个布尔表达式的组合,其组合结果仍然是一个布尔类型的。在程序运行时,动作将会在条件过滤器值为 true的情况下执行。除了一般的执行动作,还有三类比较特别的动作,它们分别是:放弃动作( Discard Action)、包含动作( Include Action)和使信息元对象内容持久化的动作。前两种动作类型的区别将在 2.3规则引擎工作机制小节介绍。
队列管理器用来管理来自不同信息服务的信息元对象的队列。
下面将研究规则引擎的这些相关构件是如何协同工作的。
如图 2所示,处理过程分为四个阶段进行:信息服务接受事件并将其转化为信息元,然后这些信息元被传给队列管理器,最后规则引擎接收这些信息元并应用它们自身携带的规则加以执行,直到队列管理器中不再有信息元。
下面专门研究规则引擎的内部处理过程。如图 3所示,规则引擎从队列管理器中依次接收信息元,然后依规则的定义顺序检查信息元所带规则集中的规则(规则已经排队就绪等待信息元的到来)。如图所示,规则引擎检查第一个规则并对其条件过滤器求值,如果值为假,所有与此规则相关的动作皆被忽略并继续执行下一条规则。如果第二条规则的过滤器值为真,所有与此规则相关的动作皆依定义顺序执行,执行完毕继续下一条规则。该信息元中的所有规则执行完毕后,信息元将被销毁,然后从队列管理器接收下一个信息元。在这个过程中并未考虑两个特殊动作:放弃动作( Discard Action)和包含动作( Include Action)。放弃动作如果被执行,将会跳过其所在信息元中接下来的所有规则,并销毁所在信息元,规则引擎继续接收队列管理器中的下一个信息元(就是短路了)。包含动作其实就是动作中包含其它现存规则集的动作。包含动作如果被执行,规则引擎将暂停并进入被包含的规则集,执行完毕后,规则引擎还会返回原来暂停的地方继续执行。这一过程将递归进行。
Java规则引擎的工作机制与上述规则引擎机制十分类似,只不过对上述概念进行了重新包装组合。 Java规则引擎对提交给引擎的 Java数据对象进行检索,根据这些对象的当前属性值和它们之间的关系,从加载到引擎的规则集中发现符合条件的规则,创建这些规则的执行实例。这些实例将在引擎接到执行指令时、依照某种优先序依次执行。一般来讲, Java规则引擎内部由下面几个部分构成:
工作内存( Working Memory)即工作区,用于存放被引擎引用的数据对象集合;
规则执行队列,用于存放被激活的规则执行实例;
静态规则区,用于存放所有被加载的业务规则,这些规则将按照某种数据结构组织,
当工作区中的数据发生改变后,引擎需要迅速根据工作区中的对象现状,调整规则执行队列中的规则执行实例。Java规则引擎的结构示意图如图 4所示。
当引擎执行时,会根据规则执行队列中的优先顺序逐条执行规则执行实例,由于规则的执行部分可能会改变工作区的数据对象,从而会使队列中的某些规则执行实例因为条件改变而失效,必须从队列中撤销,也可能会激活原来不满足条件的规则,生成新的规则执行实例进入队列。于是就产生了一种“动态”的规则执行链,形成规则的推理机制。这种规则的“链式”反应完全是由工作区中的数据驱动的。
任何一个规则引擎都需要很好地解决规则的推理机制和规则条件匹配的效率问题。规则条件匹配的效率决定了引擎的性能,引擎需要迅速测试工作区中的数据对象,从加载的规则集中发现符合条件的规则,生成规则执行实例。1982年美国卡耐基•梅隆大学的 Charles L. Forgy发明了一种叫 Rete算法,很好地解决了这方面的问题。目前世界顶尖的商用业务规则引擎产品基本上都使用 Rete算法。