正则表达式匹配中文姓名
发布时间:2025-05-22 10:58:55 发布人:远客网络
一、正则表达式匹配中文姓名
1、验证中文姓名的正则表达式:[\u4e00-\u9fa5],这个表达式是专门用来匹配中文姓名的。【正则表达式】正则表达式,又称规则表达式,是计算机科学的一个概念,这个概念最初是由Unix中的工具软件普及开的。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。正则引擎主要分为DFA、NFA两大类。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。【起源】在1951年,一位名叫Stephen Kleene的数学科学家,他在Warren McCulloch和Walter Pitts早期工作的基础之上,发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。
2、正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语。
二、ORACLE中怎样用正则表达式过滤中文字符
从表里提取汉字,需要考虑字符集,不同的字符集汉字的编码有所不同
这里以GB2312为例,写一函数准确地从表里提取简体汉字.
假设数据库字符集编码是GB2312,环境变量(注册表或其它)的字符集也是GB2312编码
并且保存到表里的汉字也都是GB2312编码的
那么也就是汉字是双字节的,且简体汉字的编码范围是
我们先看一下asciistr函数的定义
Non-ASCII characters are converted to the form\xxxx, where xxxx represents a UTF-16 code unit.
但是这并不表示以"\"开始的字符就是汉字了
这里第5条记录有一个实心的五角星
然后用asciistr函数转换一下试试
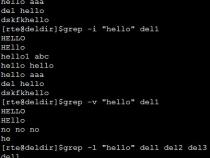
SQL> select name,asciistr(name) from test;
------------------------------------------
,啊OO10哈,\554AOO10\54C8
大家好aa/\5927\5BB6\597Daa/
☆大海123\2606\5927\6D77123
我们看到最后一条记录的实心五角星也是"\"开头的
此时我们就不能用asciistr(字段)是否存在"\"来判断是否含有汉字了.
我的函数如下,基本思路是判断字符的编码是否在GB2312规定的汉字编码范围之内
create or replace function get_chinese(p_name in varchar2) return varchar2
v_code varchar2(30000):='';
v_chinese varchar2(4000):='';
select replace(substrb(dump(p_name,1010),instrb(dump(p_name,1010),'ZHS16GBK:')),'ZHS16GBK:','') into v_code from dual where rownum=1;
for i in 1..length(p_name) loop
if lengthb(substr(p_name,i,1))=2 then
v_comma:= instrb(v_code,',');
v_code_q:= to_number(substrb(v_code,1,v_comma-1));
v_code_w:= to_number(substrb(v_code,v_comma+1,abs(instrb(v_code,',',1,2)-v_comma-1)));
if v_code_q>=176 and v_code_q<=247 and v_code_w>=161 and v_code_w<=254 then
v_chinese:= v_chinese||substr(p_name,i,1);
v_code:= ltrim(v_code,'1234567890');
v_code:= ltrim(v_code,',');
v_code:= ltrim(v_code,'1234567890');
v_code:= ltrim(v_code,',');
SQL> select name from test where length(get_chinese(name))>0;
2.列出有汉字的记录,并且只列出汉字
SQL> select get_chinese(name) from test where length(get_chinese(name))>0;
---------------------------------------------------------------------------
需要说明的是GB2312共有6763个汉字,即72*94-5=6763
我这里是计算72*94,没有减去那5个,那五个是空的。等查到了再减去
改写这个函数,可以提取非汉字或者汉字
该函数有两个参数,第一个表示要提取的字符串,第二个是1,表示提取汉字,是非1,表示提取非汉字
create or replace function get_chinese
v_code varchar2(30000):='';
v_chinese varchar2(4000):='';
v_non_chinese varchar2(4000):='';
select replace(substrb(dump(p_name,1010),instrb(dump(p_name,1010),'ZHS16GBK:')),'ZHS16GBK:','') into v_code from dual where rownum=1;
for i in 1..length(p_name) loop
if lengthb(substr(p_name,i,1))=2 then
v_comma:= instrb(v_code,',');
v_code_q:= to_number(substrb(v_code,1,v_comma-1));
v_code_w:= to_number(substrb(v_code,v_comma+1,abs(instrb(v_code,',',1,2)-v_comma-1)));
if v_code_q>=176 and v_code_q<=247 and v_code_w>=161 and v_code_w<=254 then
v_chinese:= v_chinese||substr(p_name,i,1);
v_non_chinese:= v_non_chinese||substr(p_name,i,1);
v_code:= ltrim(v_code,'1234567890');
v_code:= ltrim(v_code,',');
v_non_chinese:= v_non_chinese||substr(p_name,i,1);
v_code:= ltrim(v_code,'1234567890');
v_code:= ltrim(v_code,',');
if p_chinese='1' then
SQL> select get_chinese(name,1) from a;
-----------------------------------------
SQL> select get_chinese(name,0) from a;
-----------------------------------------
三、正则表达式只能输入中文和字母
1、编码的字符串后面一定要加模式修饰符U。
2、正则表达式:[\\u4e00-\\u9fa5]*|\\w*|\\d*|_*
3、@Testpublicvoidtest1(){//匹配正则表达式Stringstr="[\\u4e00-\\u9fa5]*|\\||\\d*w*_*";Patternpattern=Pattern.comfromrunning(STR);//
4、字符串StringmStr="howfar_344fjdk";system.out。println("stringtesting:"+mStr);Matcherm=模式。匹配器(mStr);//
5、如果(m。ind())是匹配的,{system.out。println("matchcontent:"+m.group());}}
6、匹配包含下划线的任何单词字符。相似但不公平”(咱——z0-9_)”,“这个词”字符的Unicode字符集,充分利用中国的是:
7、\u4e00——\\u9fa5],说英文字母\w,代表数字\d说_,_*是零个或多个,|或表达,所以每个匹配|拼接可以说与正则表达式相匹配。