Linux丨丨正则表达式及grep命令
发布时间:2025-05-22 10:32:14 发布人:远客网络
一、Linux||正则表达式及grep命令
1、以下内容首发自公众号“小汪Waud”。
2、本期介绍在Linux环境下的正则表达式及grep命令。
3、正则表达式(Regular Expression)是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些字符的特定组合,组成一个“规则字符串”,这个字符串用来表达对字符串的一种过滤逻辑。
4、正则表达式基本上是一种表示法,只要程序支持这种表示法,该程序就可以用来作为正则表达式的字符串处理之用。如vi、grep、awk、sed等程序支持正则表达式,所以可以使用正则表达式的特殊字符来进行字符串的处理。但例如cp、ls等命令并不支持正则表达式,所以只能用自己的通配符。
5、正则表达式依照不同的严谨度分为:基础正则表达式和扩展正则表达式。
6、 grep是一种强大的文本搜索工具,可以使用正则表达式匹配模式查找文件里符合条件的字符串,并打印出来。
7、 grep支持三种正则表达式语法:Basic、Extended和perl兼容。如果没有提供正则表达式类型,grep将搜索模式解释为基本的正则表达式。要将模式解释为扩展正则表达式,请使用-E。
8、 grep [OPTION]... PATTERN [FILE]...
9、 grep [-A] [-B] [--color=auto]"查找字符" [模式] [文件]
10、首先通过cat命令查看samples.txt的内容,如下图
11、如果想检索以K为行首的行,通过以下命令即可得到
12、如果想检索以Z为行尾的行,通过以下命令即可得到
13、如果想检索三个字符其中前面为K,后面为D中间字符,为任意字符,通过以下命令即可得到
14、
15、
二、Linux正则表达式教程:Grep Regex示例
1、正则表达式是特殊字符,可帮助搜索数据,匹配复杂模式。正则表达式缩写为“regexp”或“regex”。
2、为了便于理解,让我们逐一学习不同类型的正则表达式。
3、一些常用的正则表达式命令是tr,sed,vi和grep。下面列出了一些基本的正则表达式。
4、执行cat示例以查看现有文件的内容
5、' ^'匹配字符串的开头。让我们搜索一下STARTS的内容
6、仅过滤以字符开头的行。将忽略开头不包含字符“a”的行。
7、这些表达式告诉我们字符串中字符的出现次数。他们是
8、我们想要检查字符'p'是否在字符串中依次出现2次。为此,语法将是:
9、注意:您需要使用这些正则表达式添加-E。
10、这些正则表达式包含多个表达式的组合。他们之中有一些是:
11、假设我们要过滤字符'a'在字符't'之前的行
12、大括号扩展的语法是花括号“{}”内的序列或逗号分隔的项目列表。序列中的起始和结束项由两个句点“..”分隔。
13、在上面的示例中,echo命令使用大括号扩展创建字符串。
三、Linux里面grep -v命令作用是什么
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-s:不显示不存在或无匹配文本的错误信息。
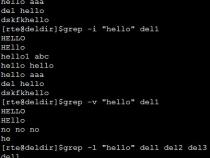
-v:显示不包含匹配文本的所有行。
--color=auto:可以将找到的关键词部分加上颜色的显示。
\:忽略正则表达式中特殊字符的原有含义。
\<:从匹配正则表达式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求。
[- ]:范围,如[A-Z],即A、B、C一直到Z都符合要求。
显示所有以d开头的文件中包含 test的行
itcast$ grep‘test’ aa bb cc
显示在aa,bb,cc文件中匹配test的行。
itcast$ grep‘[a-z]\{5\}’ aa
显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
itcast$ grep‘wesest.*\1′ aa
如果west被匹配,则es就被存储到内存中,并标记为1,然后搜索任意个字符(.*),这些字符后面紧跟着另外一个es(\1),找到就显示该行。如果用egrep或grep-E,就不用”\”号进行转义,直接写成’w(es)t.*\1′就可以了。
如果有很多输出时,您可以通过管道将其转到’less’上阅读:
itcast$ grep magic/usr/src/Linux/Documentation/*| less
有一点要注意,您必需提供一个文件过滤方式(搜索全部文件的话用*)。如果您忘了,’grep’会一直等着,直到该程序被中断。如果您遇到了这样的情况,按,然后再试。
下面还有一些有意思的命令行参数:
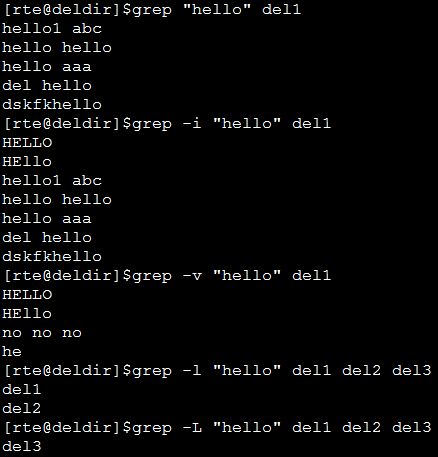
grep-i pattern files:不区分大小写地搜索。默认情况区分大小写,
grep-l pattern files:只列出匹配的文件名,
grep-L pattern files:列出不匹配的文件名,
grep-w pattern files:只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
grep-C number pattern files:匹配的上下文分别显示[number]行,
grep pattern1| pattern2 files:显示匹配 pattern1或 pattern2的行,
例如:grep"abc\|xyz" testfile表示过滤包含abc或xyz的行
grep pattern1 files| grep pattern2:显示既匹配 pattern1又匹配 pattern2的行。
grep-n pattern files即可显示行号信息
grep-c pattern files即可查找总行数
还有些用于搜索的特殊符号:\<和\>分别标注单词的开始与结尾。
grep man*会匹配‘Batman’、’manic’、’man’等,
grep‘\<man’*匹配’manic’和’man’,但不是’Batman’,
grep‘\<man\>’只匹配’man’,而不是’Batman’或’manic’等其他的字符串。