Java语言所使用的字符集是什么
发布时间:2025-05-22 01:13:47 发布人:远客网络
一、Java语言所使用的字符集是什么
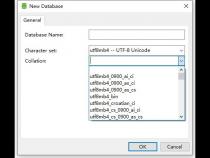
Java语言所使用的字符集是16位Unicode编码。另外再介绍一些常见的字符集:
1、最早在dos下写pascal的时候,就遇到ASCII字符集,后来还是dos下写c,也是ascii字符集
特点:目前最通用的单字节编码字符集
最早ascii用7bit表示,总共能表示2^7=128个字符,后来扩展到8bit,就表示2^8=256个字符
2、GB2312又称为GB2312-80字符集,全称为《信息交换用汉字编码字符集·基本集》,由原中国国家标准总局发布,1981年5月1日实施。
特点:当然是能表示99%的中国汉字,还包括拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母等
3、GBK是汉字编码标准之一,全称《汉字内码扩展规范》,GBK向下与GB2312编码兼容,向上支持ISO10646.1国际标准。可以认为GBK是在GB2313基础上通过内码扩展出来的一个标准。
特点:完全兼容GB2312标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字
5、GB 18030,全称是GB18030-2000《信息交换用汉字编码字符集基本集的扩充》,是我国政府于2000年3月17日发布的新的汉字编码国家标准,2001年8月31日后在中国市场上发布的软件必须符合本标准。
特点:就是强大。覆盖中文、日文、朝鲜语和中国少数民族文字。满足中国大陆、香港、台湾、日本和韩国等东亚地区信息交换多文种、大字量、多用途、统一编码格式的要求。并且与Unicode 3.0版本兼容,填补Unicode扩展字符字汇“统一汉字扩展A”的内容。并且与以前的国家字符编码标准(GB2312,GB13000.1)兼容。
表示:单字节、双字节、四字节三种方式
6、Unicode野心更大(当然有一个国际统一标准当然是好事)
特点:Unicode是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
这里可能有点不好理解,举个例子
首先,把unicode理解成对所有字符做了一个统一的编号,比如:“字”这个字符,编号是23383,这个是unicode定义的
但是,在计算机中,如何存储这个编号呢?方式就有很多,存储unicode的方式,就是utf-8,utf-16,utf-32
utf-8用3个字节来表示汉字,所以utf-8的表示为:0xE5AD97
utf-16用2个字节来表示汉字,所以utf-16的表示为:0x5b57刚好和数值是一样的
utf-32用4个字节来表示汉字,所以utf-32的表示为:0x00005b57和数值是一样的,不过浪费空间
7、再来讲讲utf-8,它是一种变长的字符集
表示:单字节来表示字母,双字节来表示一些希腊字母,三字节来表示汉字,当然也有四字节的
这么做当然会增加表示和识别的难度,不过,可以节省空间。这也是为什么utf-8在网络编码中流行的原因。
二、Java中如何查看字符串是什么字符集
判断java字符串的字符集有多种方法,我们一一讨论如下:
1、通过把未知编码字符串,用猜想的编码再解码,观察字符串是不是正确还原了。
原理:假如目标编码没有数组中的字符,那么编码会破坏,无法还原。
缺点:假如字符少,而正巧错误的猜想编码中有这种字节,就会出错。
如:new String("tested str".getBytes("enc"),"enc")
2、大多数时候,我们只要判断本地平台编码和utf8,utf8编码相当有规律,所以可以分析是否是utf8,否则使用本地编码。
缺点:有时,个别本地编码字节在utf8中也会出现,导致出错,需要分析。
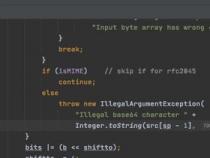
public static boolean isValidUtf8(byte[] b,int aMaxCount){
int lLen=b.length,lCharCount=0;
byte lByte=b[i++];//to fast operation,++ now, ready for the following for(;;)
if(lByte>=0) continue;//>=0 is normal ascii
if(lByte<(byte)0xc0|| lByte>(byte)0xfd) return false;
int lCount=lByte>(byte)0xfc?5:lByte>(byte)0xf8?4
:lByte>(byte)0xf0?3:lByte>(byte)0xe0?2:1;
if(i+lCount>lLen) return false;
for(int j=0;j=(byte)0xc0) return false;
三、请问java默认的字符集是utf8是吗,那么下面这个
1、java是定义了char为两个字节,同时String的实现也是用char数组的,这应该就是说String是两个字节字符构成的了。可是UTF8规定是英文字符一个字节,中文字符三个字节。这样貌似说java的字符村在内部是用UTF8编码的就貌似矛盾了。
2、在维基百科上有这么一段话:在通常用法下,Java程序语言在通过InputStreamReader和OutputStreamWriter读取和写入串的时候支持标准UTF-8。而没有说到java字符串到底是不是UTF8构成的。
3、同时我们知道java字面转义是\uxxxx的,也就是两个字节的,也就是两个字节确实可以编码所有字符才对。
4、好吧,差了资料,在类 Character的文档里面看到了这么些东西。
5、“char数据类型(和 Character对象封装的值)基于原始的 Unicode规范,将字符定义为固定宽度的 16位实体。Unicode标准曾做过修改,以允许那些其表示形式需要超过 16位的字符。合法代码点的范围现在是从 U+0000到 U+10FFFF,即通常所说的 Unicode标量值。”
6、嗯,也就是说Unicode原先是定义为2个字节的,但是后来改动了,进行了扩展。而java语言在定义的时候已经定义了char为2个字节,所以Unicode改了java却不能跟着把语言的基础也改了,所以又有——“从 U+0000到 U+FFFF的字符集有时也称为 Basic Multilingual Plane(BMP)。代码点大于 U+FFFF的字符称为增补字符。Java 2平台在 char数组以及 String和 StringBuffer类中使用 UTF-16表示形式。在这种表现形式中,增补字符表示为一对 char值,第一个值取自高代理项范围,即(\uD800-\uDBFF),第二个值取自低代理项范围,即(\uDC00-\uDFFF)。”也就是用两个char字符来表示一个Unicode值。
7、总的来说就是char还是两个字节的,但是在表示一些特殊字符的时候需要用到两个连续的char来表示,同时String通过保存了一个char序列来表示字符串。而String的getBytes("utf-8")获得的则是现在标准的UTF8编码字节序列,所以得到的是一个字母是一个字节,一个汉字是三个字节的结果。
8、哎~~也是乱七八糟的描述,鬼知道Unicode要变动呢这是。。