java 怎么判断文本内容的编码
发布时间:2025-05-21 14:22:37 发布人:远客网络
一、java 怎么判断文本内容的编码
:简单判断是UTF-8或不是UTF-8,因为一般除了UTF-8之外就是GBK,所以就设置默认为GBK。
按照给定的字符集存储文件时,在文件的最开头的三个字节中就有可能存储着编码信息,所以,基本的原理就是只要读出文件前三个字节,判定这些字节的值,就可以得知其编码的格式。其实,如果项目运行的平台就是中文操作系统,如果这些文本文件在项目内产生,即开发人员可以控制文本的编码格式,只要判定两种常见的编码就可以了:GBK和UTF-8。由于中文Windows默认的编码是GBK,所以一般只要判定UTF-8编码格式。
对于UTF-8编码格式的文本文件,其前3个字节的值就是-17、-69、-65,所以,判定是否是UTF-8编码格式的代码片段如下:
InputStream in= new java.io.FileInputStream(file);
if(b[0]==-17&& b[1]==-69&& b[2]==-65)
System.out.println(file.getName()+":编码为UTF-8");
System.out.println(file.getName()+":可能是GBK,也可能是其他编码");
2:若想实现更复杂的文件编码检测,可以使用一个开源项目cpdetector,它所在的网址是:。它的类库很小,只有500K左右,cpDetector是基于统计学原理的,不保证完全正确,利用该类库判定文本文件的代码如下:
读外部文件(先利用cpdetector检测文件的编码格式,然后用检测到的编码方式去读文件):
*利用第三方开源包cpdetector获取文件编码格式
*要判断文件编码格式的源文件的路径
public static String getFileEncode(String path){
* detector是探测器,它把探测任务交给具体的探测实现类的实例完成。
* cpDetector内置了一些常用的探测实现类,这些探测实现类的实例可以通过add方法加进来,如ParsingDetector、
* JChardetFacade、ASCIIDetector、UnicodeDetector。
* detector按照“谁最先返回非空的探测结果,就以该结果为准”的原则返回探测到的
*字符集编码。使用需要用到三个第三方JAR包:antlr.jar、chardet.jar和cpdetector.jar
* cpDetector是基于统计学原理的,不保证完全正确。
CodepageDetectorProxy detector= CodepageDetectorProxy.getInstance();
* ParsingDetector可用于检查HTML、XML等文件或字符流的编码,构造方法中的参数用于
*指示是否显示探测过程的详细信息,为false不显示。
detector.add(new ParsingDetector(false));
* JChardetFacade封装了由Mozilla组织提供的JChardet,它可以完成大多数文件的编码
*测定。所以,一般有了这个探测器就可满足大多数项目的要求,如果你还不放心,可以
*再多加几个探测器,比如下面的ASCIIDetector、UnicodeDetector等。
detector.add(JChardetFacade.getInstance());//用到antlr.jar、chardet.jar
// ASCIIDetector用于ASCII编码测定
detector.add(ASCIIDetector.getInstance());
// UnicodeDetector用于Unicode家族编码的测定
detector.add(UnicodeDetector.getInstance());
java.nio.charset.Charset charset= null;
charset= detector.detectCodepage(f.toURI().toURL());
String charsetName= getFileEncode(configFilePath);
System.out.println(charsetName);
inputStream= new FileInputStream(configFile);
BufferedReader in= new BufferedReader(new InputStreamReader(inputStream, charsetName));
读jar包内部资源文件(先利用cpdetector检测jar内部的资源文件的编码格式,然后以检测到的编码方式去读文件):
*利用第三方开源包cpdetector获取URL对应的文件编码
*要判断文件编码格式的源文件的URL
public static String getFileEncode(URL url){
* detector是探测器,它把探测任务交给具体的探测实现类的实例完成。
* cpDetector内置了一些常用的探测实现类,这些探测实现类的实例可以通过add方法加进来,如ParsingDetector、
* JChardetFacade、ASCIIDetector、UnicodeDetector。
* detector按照“谁最先返回非空的探测结果,就以该结果为准”的原则返回探测到的
*字符集编码。使用需要用到三个第三方JAR包:antlr.jar、chardet.jar和cpdetector.jar
* cpDetector是基于统计学原理的,不保证完全正确。
CodepageDetectorProxy detector= CodepageDetectorProxy.getInstance();
* ParsingDetector可用于检查HTML、XML等文件或字符流的编码,构造方法中的参数用于
*指示是否显示探测过程的详细信息,为false不显示。
detector.add(new ParsingDetector(false));
* JChardetFacade封装了由Mozilla组织提供的JChardet,它可以完成大多数文件的编码
*测定。所以,一般有了这个探测器就可满足大多数项目的要求,如果你还不放心,可以
*再多加几个探测器,比如下面的ASCIIDetector、UnicodeDetector等。
detector.add(JChardetFacade.getInstance());//用到antlr.jar、chardet.jar
// ASCIIDetector用于ASCII编码测定
detector.add(ASCIIDetector.getInstance());
// UnicodeDetector用于Unicode家族编码的测定
detector.add(UnicodeDetector.getInstance());
java.nio.charset.Charset charset= null;
charset= detector.detectCodepage(url);
URL url= CreateStationTreeModel.class.getResource("/resource/"+"配置文件");
URLConnection urlConnection= url.openConnection();
inputStream=urlConnection.getInputStream();
String charsetName= getFileEncode(url);
System.out.println(charsetName);
BufferedReader in= new BufferedReader(new InputStreamReader(inputStream, charsetName));
3:探测任意输入的文本流的编码,方法是调用其重载形式:
charset=detector.detectCodepage(待测的文本输入流,测量该流所需的读入字节数);
上面的字节数由程序员指定,字节数越多,判定越准确,当然时间也花得越长。要注意,字节数的指定不能超过文本流的最大长度。
4:判定文件编码的具体应用举例:
属性文件(.properties)是Java程序中的常用文本存储方式,象STRUTS框架就是利用属性文件存储程序中的字符串资源。它的内容如下所示:
FileInputStream ios=new FileInputStream(“属性文件名”);
Properties prop=new Properties();
String value=prop.getProperty(“属性名”);
利用java.io.Properties的load方法读入属性文件虽然方便,但如果属性文件中有中文,在读入之后就会发现出现乱码现象。发生这个原因是load方法使用字节流读入文本,在读入后需要将字节流编码成为字符串,而它使用的编码是“iso-8859-1”,这个字符集是ASCII码字符集,不支持中文编码,
String value=prop.getProperty(“属性名”);
String encValue=new String(value.getBytes(“iso-8859-1″),”属性文件的实际编码”);
方法二:象这种属性文件是项目内部的,我们可以控制属性文件的编码格式,比如约定采用Windows内定的GBK,就直接利用”gbk”来转码,如果约定采用UTF-8,就使用”UTF-8″直接转码。
方法三:如果想灵活一些,做到自动探测编码,就可利用上面介绍的方法测定属性文件的编码,从而方便开发人员的工作
补充:可以用下面代码获得Java支持编码集合:
Charset.availableCharsets().keySet();
可以用下面的代码获得系统默认编码:
二、java的十种设计模式
在java培训的过程中,我们需要了解到关于java的设计模式,下面是昌平java培训介绍的关于java设计模式的相关介绍。
1、桥梁模式(Bridge):将抽象部分与它的实现部分分离,使它们都可以独立地变化。
2、合成模式(Composite):将对象组合成树形结构以表示"部分-整体"的层次结构。它使得客户对单个对象和复合对象的使用具有一致性。
3、抽象工厂模式(AbstractFactory):提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
4、装饰模式(Decorator):动态地给一个对象添加一些额外的职责。就扩展功能而言,它能生成子类的方式更为灵活。
5、适配器模式(Adapter):将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口或类不兼容而不能一起工作的类可以一起工作。
6、责任链模式(ChainofResponsibility):为解除请求的发送者和接收者之间耦合,而使多个对象都有机会处理这个请求。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它。
7、工厂方法(FactoryMethod):定义一个用于创建对象的接口,让子类决定将哪一个类实例化。FactoryMethod使一个类的实例化延迟到其子类。
8、建造模式(Builder):将一个复杂对象的构建与它的表示分离,使同样的构建过程可以创建不同的表示。
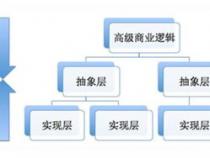
9、门面模式(Facade):为子系统中的一组接口提供一个一致的界面,门面模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
10、命令模式(Command):将一个请求封装为一个对象,从而可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可取消的操作。
三、java 表结构不合理满足不了新需求怎么处理
1、软件架构作为一个概念,体现在技术和业务两个方面。
2、从技术角度来说:软件架构随着技术的革新不断地更新其内容,软件架构建立于当前技术和一些基本原则的基础之上。
3、分层原则:分层是为了降低软件深度复杂性而使用的关键思想,就像社会有了阶级一样,软件有了层次结构。
4、模块化原则:模块化是化解软件广度复杂的必然手段,模块化的目的就是让软件分工。
5、接口实现分离原则随着软件模块化的不断深入改进,面向接口编程而不是面向实现编程可以让复杂度日趋增高的软件降低模块之间的耦合度,从而让各模块更轻松改进。从这个原则出发,软件也从微观进行了细致的规范化。
6、还有两个比较小但很重要的原则:
7、细节隐藏原则很显然把复杂问题简化,把难看的细节隐去,能让软件结构更清晰。其实这个原则使用很普遍,java/c++语言中的封装原则以及设计模式中的Facade(外观)模式就很能体现这个原则的精神。
8、依赖倒置原则随着软件结构的进一步发展,层与层之间、模块与模块之间的依赖逐渐加深,而层、模块的动态可插拔要求不端增大。依赖倒置原则可看视为接口实现分离原则的深化,根据此原则的精神,软件进入了工具时代。这个原则有点类似于知名的好莱坞法则:Don't call us, we'll call you。
9、以上这些原则奠定了我们的软件架构的价值指标。但软件架构毕竟是建立在当前技术之上的。而每一代技术都有架构模式。过去的不再说了,让我们现在就来看一下当前流行的技术,以及当前我们能采用的架构。
10、因为面向对象是当前最流行开发技术,且设计模式的大量使用使面向对象的走向成熟,而数据库是当前最有效的存储结构、web界面是当前最流行的用户接口,所以当前最典型的三层次架构就架构在以上几项技术的基础之上,用数据库作存储层、用面向对象来实现业务层、用web来作为用户接口层。我们从三层次架构谈起:
11、因为面向对象技术和数据库技术不适配,所以在标准三层次架构的基础上,我们增加了数据持久层,来管理O-R双向映射,但目前一直没有最理想的实现技术。cmp和entity bean技术因为其实现复杂,功能前景有限,已接近被淘汰的边缘。JDO及hibernate作为o-r映射的后期之秀,尤其是hibernate,功能相当完备。推荐作为持久层的首选
12、在业务层,因为当前业务日趋负载,且变动频繁,所以我们必须有足够敏捷的技术来保证我们的适应变化的能力,在标准j2ee系统中session bean负责业务处理,且有不错的性能表现,但采用ejb系统对业务架构模式改变太大,且其复杂而昂贵,业务代码移植性差。而spring作为一个bean配置的轻量级架构,漂亮的IOC模式实现,对业务架构影响小,所以推荐作为中间层业务框架。
13、在用户结构层,虽然servlet/jsp/jstl/javaBean能够实现MVC架构,但终究过于粗糙。struts对MVC架构的实现就比较完美,Taperstry也极好地实现MVC架构,且采用基于事件的方式,非常诱人,惜其不够成熟,我们仍旧推荐struts作为用户接口层基础架构。
14、因为业务层是三层次架构中最有决定意义的,所以让我们回到业务层细致地分析一下,在复杂的业务我们常常需要以下基础服务的一种或几种:事务一致性服务acid(tool:jta/jts)、并发加锁服务concurrent&&lock、池化管理服务cache、访问控制服务(tool:jaas)、流程控制服务workflow、动态实现服务IOC,串行化消息服务(tool:jms)、负载平衡服务blance等。如果我们不采用重量级应用服务器(如weblogic,websphere,jboss等)及重量级组件(EJB),我们必须自己实现其中一些服务。虽然我们大多情况下,不需要所有这些服务,但实现起来却非易事。幸运的是我们有大量的开源实现代码,但采用开源代码却常常是件不轻松的事。
15、随着xml作为结构化信息传输和存储地位日渐重要,一些xml文档操作工具(DOM,Digester,SAX等)的使用愈发重要,而随着xml schema的java binding工具(jaxb,xmlbean等)工具的成熟,采用xml schema来设计xml文档格式,然后采用java binding来生成java bean会成为主要编程模式,而这又进一步使数据中心向xml转移,使在中小数据量上,愈发倾向于以xquery为查询语言的xml数据库。最近还有一个趋势,microsoft,ibm等纷纷大量开发中间软件如(microsoft office之infopath),可以直接从xml schema生成录入页面等非常实用的功能。还有web service的广泛应用,都将对软件的架构有非常重大的影响。至于面向服务架构(SOA)前景如何,三层次架构什么时候走入历史,现在还很难定论。
16、aop的发展也会对软件架构有很深的影响,但在面向对象架构里,无论aspectJ还是jboss-aop抑是aspectWerks、nanning都有其自身的严重问题:维护性很差,所以说它将很难走远。也许作为一个很好的思想,它将在web service里大展身手。
17、rdf,owl作为w3c语义模型的标志性的语言,也很难想象能在当前业务架构发挥太大影响。但如果真如它所声称那样,广泛地改变着信息的结构。那么对软件架构也会有深远影响。
18、尽量建立完整的持久对象层.可获得高回报
19、尽量将各功能分层,分块,每一模块均依赖假定的其它模块的外观
20、不能依赖静态数据来实现IOC模式,应该依赖数据特征接口,静态数据仅是数据特征接口实现方式之一
21、架构设计时xml是支持而不是依赖.但可以提供单一的xml版本的实现
22、从业务角度说:软件架构应是深刻体现业务内部规则的业务架构,但因为业务变化频纴,所以软件架构很难保持恒定不变,但业务的频繁变化不应是软件架构大规模频繁变化的原因,软件架构应是基于变化的架构。
23、一种业务有其在一段时间内稳定存在的理由(暂且不谈),业务内部有许多用例,每一种用例都有固定的规则,每一规则都有一些可供判定的项,每一项从某一维度来观察都是可测量的,我们的架构首先必须保证完美适应每一项每一种测量方式,很多失败的架构都是因为很多项的测量方式都发生变更这种微观变化中。
24、每个用例都有规则,我们在作业务用例分析,常常假定一些规则是先验的,持久稳定的,然而后来的业务改变常常又证明这种看法是错误的,然而常常我们的架构已经为之付出了不可挽回的代价。大量事实证明:规则的变化常常用例变化的根本原因。所以我们的架构要尽可能适应规则的变化,尽可能建立规则模版。
25、每个用例都关系着不同的角色。每一个用例的产生都必然是因为角色的变更(注意:不是替换,而是增强或减弱),所以注意角色的各种可能情况,对架构的设计有举足轻重的意义。在我们当前的三层架构里,角色完美地对应接口概念。
26、在一个系统里很多用例都相互关联,考虑到每个用例均有可能有不同的特例,所以在架构设计中,尽量采用依赖倒置原则。如架构许可可采用消息通信模式(JMS)。这样可降低耦合度。
27、现在我们谈一下业务稳定存在理由对业务的影响。存在即是合理,在这里当然是正确的。业务因人而存在,所以问业务存在的理由即是问不同角色的需要这项业务的理由以及喜欢不喜欢当前业务用例的理由,所有这样的角色都应该在系统里预留。《待续》
28、在架构设计中有几个原则可以考虑:
29、这里未提供相关的例子,例子会在以后的更新时提供。
30、业务中的一些用例之间的关系常常和一些常规的模式很相似。但随着时间的演化,慢慢地和先前的模式有了分歧。这是个正常的现象。但这对系统架构却要求非常高,要求系统架构能适应一些模式的更替。在这里我们尽可能早地注意到用例之间的相互角色变化,为架构更新做好准备.