ElasticSearch 分词器,了解一下
发布时间:2025-05-21 19:33:12 发布人:远客网络
一、ElasticSearch 分词器,了解一下
1、这篇文章主要来介绍下什么是 Analysis,什么是分词器,以及 ElasticSearch自带的分词器是怎么工作的,最后会介绍下中文分词是怎么做的。
2、顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES中,Analysis是通过分词器(Analyzer)来实现的,可使用 ES内置的分析器或者按需定制化分析器。
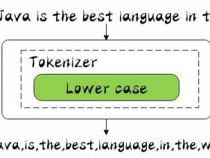
3、举一个分词简单的例子:比如你输入 Mastering Elasticsearch,会自动帮你分成两个单词,一个是 mastering,另一个是 elasticsearch,可以看出单词也被转化成了小写的。
4、再简单了解了 Analysis与 Analyzer之后,让我们来看下分词器的组成:
5、分词器是专门处理分词的组件,分词器由以下三部分组成:
6、同时 Analyzer三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters, Tokenizer以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
7、接下来会对以上分词器进行讲解,在讲解之前先来看下很有用的 API: _analyzer API:
8、它可以通过以下三种方式来查看分词器是怎么样工作的:
9、再了解了 Analyzer API后,让我们一起看下 ES内置的分词器:
10、首先来介绍下 Stamdard Analyzer分词器:
11、它是 ES默认的分词器,它会对输入的文本按词的方式进行切分,切分好以后会进行转小写处理,默认的 stopwords是关闭的。
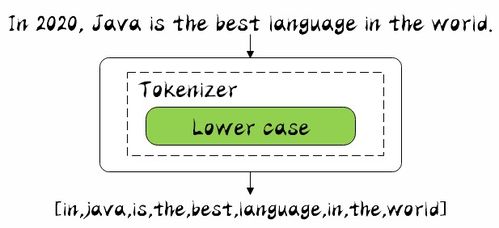
12、下面使用 Kibana看一下它是怎么样进行工作的,在 Kibana的开发工具(Dev Tools)中指定 Analyzer为 standard,并输入文本 In 2020, Java is the best language in the world.,然后我们运行一下:
13、可以看出是按照空格、非字母的方式对输入的文本进行了转换,比如对 Java做了转小写,对一些停用词也没有去掉,比如 in。
14、其中 token为分词结果; start_offset为起始偏移; end_offset为结束偏移; position为分词位置。
15、下面来看下 Simple Analyzer分词器:
16、它只包括了 Lower Case的 Tokenizer,它会按照非字母切分,非字母的会被去除,最后对切分好的做转小写处理,然后接着用刚才的输入文本,分词器换成 simple来进行分词,运行结果如下:
17、从结果中可以看出,数字 2020被去除掉了,说明非字母的的确会被去除,所有的词也都做了小写转换。
18、现在,我们来看下 Whitespace Analyzer分词器:
19、它非常简单,根据名称也可以看出是按照空格进行切分的,下面我们来看下它是怎么样工作的:
20、可以看出,只是按照空格进行切分, 2020数字还是在的, Java的首字母还是大写的,,还是保留的。
21、接下来看 Stop Analyzer分词器:
22、它由 Lowe Case的 Tokenizer和 Stop的 Token Filters组成的,相较于刚才提到的 Simple Analyzer,多了 stop过滤,stop就是会把 the, a, is等修饰词去除,同样让我们看下运行结果:
23、可以看到 in is the等词都被 stop filter过滤掉了。
24、它其实不做分词处理,只是将输入作为 Term输出,我们来看下运行结果:
25、我们可以看到,没有对输入文本进行分词,而是直接作为 Term输出了。
26、它可以通过正则表达式的方式进行分词,默认是用 \W+进行分割的,也就是非字母的符合进行切分的,由于运行结果和 Stamdard Analyzer一样,就不展示了。
27、 ES为不同国家语言的输入提供了 Language Analyzer分词器,在里面可以指定不同的语言,我们用 english进行分词看下:
28、可以看出 language被改成了 languag,同时它也是有 stop过滤器的,比如 in, is等词也被去除了。
29、中文分词有特定的难点,不像英文,单词有自然的空格作为分隔,在中文句子中,不能简单地切分成一个个的字,而是需要分成有含义的词,但是在不同的上下文,是有不同的理解的。
30、那么,让我们来看下 ICU Analyzer分词器,它提供了 Unicode的支持,更好的支持亚洲语言!
31、我们先用 standard来分词,以便于和 ICU进行对比。
32、运行结果就不展示了,分词是一个字一个字切分的,明显效果不是很好,接下来用 ICU进行分词,分词结果如下:
33、可以看到分成了各国,有,企业,相继,倒闭,显然比刚才的效果好了很多。
34、还有许多中文分词器,在这里列举几个:
35、大家可以自己安装下,看下它中文分词效果。
36、本文主要介绍了 ElasticSearch自带的分词器,学习了使用 _analyzer API去查看它的分词情况,最后还介绍下中文分词是怎么做的。
二、java中关于io流的问题
1、1用一个程序监听该目录,一旦目录中被加入了txt后缀的文件,则在一个索引文件中加入该文件名称,随后启动一线程,使用缓冲读取该文件(注意解密),直到找到"tarena"所在行,并记录该文件的大小到在索引文件中。
2、2应用程序读取索引文件,就可快速得到在某个目录下有哪些文件有tarena,并累计文件大小,
3、这种策略是牺牲在写文件的时间,完成索引的创建,读程序性能会提高
4、1遍历目录树,找到每一个.txt文件,每当找到一个txt时,启动一个新线程,解密,找出tarena所在行,并保存相关数据在内存如hashmap中,
5、2应用程序从hashmap中直接获取所有的内容
6、这种策略牺牲的是读的时间其他差不多
7、第三种策略使用lucene框架,主要是针对每个文件建立分词索引,这里意义不大,所以建议使用上面两种策略。
三、你常用的Java工具库都有哪些
JavaSDK肯定是使用最广的库,所以本文的名单焦点是流行的第三方库。该列表可能并不完善,所以如果你觉得有什么应该出现在列表中的,请留下您的评论。非常感谢!
Apache Commons Lang:来自Apache的核心库,为java.lang API补充了许多常用的工具类,如字符串操作、对象的创建等。
Google Guava:来自谷歌的核心库,包括集合(Collection)、缓存(Caching)、支持原语(Primitives)等。(示例)
Jsoup:一个简化了的 HTML操作的库。(示例)
STaX:一组可以高效处理XML的API。(示例)
Spring:Java平台上众所周知的开源框架和依赖注入容器。(示例)
Struts2:来自Apache的流行Web框架。(示例)
GoogleWebToolkit:Google提供的开发工具库,主要用于构建和优化复杂的Web程序用。(示例)
Strips:使用最新Java技术构建的Web程序框架,推荐使用。
Tapestry:面向组件的框架,用于使用Java创建动态、健壮、扩展性高的Web应用程序。
请猛击这里查看以上面框架之间的比较。
JFreeChart:用于创建如条形图、折线图、饼图等图表。
JFreeReport:创建于输出PDF格式的报表。
JGraphT:创建图像,其中只包含由线段连接的点集。
Swing:SDK提供的GUI库。(示例)
OpenNLP:来自Apache的自然语言处理库。(示例)
StanfordParser:斯坦福大学提供的自然语言处理库。(示例)
如果你是一名NLP专家,请猛击这里查看更多工具库介绍。
EclipseJDT:由IBM提供的静态分析库,可以操作Java源代码。(示例)
WALA:可以处理jar包文件(即字节码)的工具库。(示例)
Jackson:用于处理JSON数据格式的多用途的Java库。Jackson旨在快速、准确、轻量、对开人员友好之间找到最好的平衡点。
XStream:一个简单用于对象和XML互相转换的库。
GoogleGson:一个专门用于Java对象和Json对象相互转换的工具库。(示例)
JSON-lib:用于beans、maps、collections、javaarrays、XML和JSON之间相互转换操作的工具库。
ApacheCommonsMath:提供数学计算和数值统计需函数的工具库。
ApacheLog4j:风行一时的日志记录操作库。(示例)
Logback:当前流行的log4j项目的继任者。
SLF4J(TheSimpleLoggingFacadeforJava):各种日志框架的一个简单的外观或抽象(如java.util.logging、logback、log4j等),允许用户在部署时加入需要的日志框架。
ApachePOI:利用其提供的APIs,可以使用纯Java代码操作各种基于微软OLE2合成文档格式的文档。
Docx4j:一个用于创建、操作微软公开的XML文件的库(支持Worddocx、 Powerpointpptx和Excelxlsx)。
Joda-Time:如有质量问题包退包换的Java日期和时间类。
Lambok:旨在减少代码编写的Java开发库。