Flink状态容错savepoint与checkpoint
发布时间:2025-05-21 09:39:44 发布人:远客网络
一、Flink状态容错savepoint与checkpoint
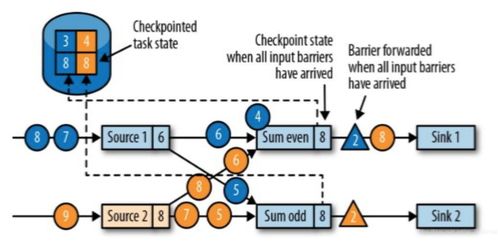
1、Flink是用于处理大规模数据流的高性能、容错、流批一体的计算框架。Flink的容错机制主要依赖于两种核心概念:检查点(Checkpoints)和保存点(Savepoints)。
2、检查点是Flink用来确保程序正确执行和在失败时进行恢复的关键机制。通过定期执行检查点,Flink可以记录作业状态和执行位置。这使得Flink能够在程序意外停止时,从最近的检查点恢复状态,从而保持与正常执行相同的语义。要启用检查点,开发者需要调用StreamExecutionEnvironment的`enableCheckpointing`方法,并设置检查点的时间间隔。检查点的设置和其他属性可通过`getCheckpointConfig()`方法获取和修改。
3、在检查点机制中,Flink会与持久化存储进行交互,用于读写流数据和状态。为了确保检查点的有效性,开发者通常需要指定检查点的保留策略。默认情况下,检查点仅用于故障恢复,当程序被取消时,检查点将被清除。为了在失败或取消作业时保留检查点,开发者需要配置相应的`ExternalizedCheckpointCleanup`参数。保留检查点有助于在升级程序或处理历史数据时提供恢复能力。
4、状态后端负责存储和管理Flink作业中的状态。Flink提供了几种开箱即用的状态后端,如HashMapStateBackend和EmbeddedRocksDBStateBackend。HashMapStateBackend以Java对象形式存储状态在堆中,适用于对性能要求较高且状态大小有限的场景。而EmbeddedRocksDBStateBackend将状态持久化到RocksDB数据库,提供更高的可扩展性和更大的状态容量。选择合适的状态后端取决于性能需求和可扩展性考虑。
5、保存点是Flink作业执行状态的一致镜像,允许用户在停止、重新启动、分叉或更新作业时进行操作。保存点由两部分组成:稳定存储上的二进制文件和元数据文件。稳定存储上的文件用于存储作业状态的数据映像,而元数据文件包含了指向这些文件的指针。创建保存点时,Flink会生成一个新的目录,包含数据和元数据文件。保存点的创建和恢复过程允许用户在不同环境间迁移作业,如升级Flink版本或迁移集群。
6、为了确保保存点的有效性,建议为作业中的所有算子分配ID。分配ID有助于Flink在恢复时正确映射状态,即使部分算子被删除或添加。在恢复过程中,Flink将尝试将所有状态映射回新的程序,但可以通过`--allowNonRestoredState`选项跳过无法映射到新程序的状态。此外,保存点文件可以在任何地方移动,而检查点文件则无法移动,因为检查点可能包含依赖于特定文件路径的文件。
7、检查点主要针对故障恢复,提供轻量级的检查点创建和快速恢复机制,确保程序在失败时能够从最近的状态恢复。而保存点则更加关注可移植性和操作灵活性,用于作业的计划更新、版本升级和集群迁移等场景。保存点的创建和恢复过程提供更高级的控制和管理能力,允许用户在不同环境间安全地迁移和操作Flink作业。
二、数据库(mysql)关键知识
Mysql是目前互联网使用最广的关系数据库,关系数据库的本质是将问题分解为多个分类然后通过关系来查询。一个经典的问题是用户借书,三张表,一个用户,一个书,一个借书的关系表。当需要查询某个用户借书情况或者是书被那些人借了,就用关系查询来实现。
来自英文Normal form,简称NF。要想设计—个好的关系,必须使关系满足一定的约束条件,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。总共有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
1NF是指数据库表的每一列都是不可分割的原子数据项。2NF必须满足1NF,要求数据库表中的每行记录必须可以被唯一地区分。3NF在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)。BCNF是在3NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖),满足BCNF不再会有任何由于函数依赖导致的异常,但是我们还可能会遇到由于多值依赖导致的异常。4NF的定义很简单:已经是BC范式,并且不包含多值依赖关系。5NF处理的是无损连接问题,这个范式基本没有实际意义,因为无损连接很少出现,而且难以察觉。而域键范式试图定义一个终极范式,该范式考虑所有的依赖和约束类型,但是实用价值也是最小的,只存在理论研究中。
是数据库对象命名空间中的层次,主要用来解决命名冲突的问题。从概念上说,一个数据库系统包含多个Catalog,每个Catalog又包含多个Schema,而每个Schema又包含多个数据库对象(表、视图、字段等)。但是Mysql的数据库名就是Schema,不支持Catalog。
Mysql的数据库引擎主要有两种MyISAM和InnoDB,MyISAM支持全文检索,InnoDB支持事务。
SQL中的通配符‘%’代表任意字符出现任意次数。‘_’代表任意字符出现一次。SQL与正则表达式结合查询一般用在WHERE table_name REGEXP'^12.34'。子查询是从里到外执行。
数据库联结(join)涉及到外键,外键是指一个表的列是另一个表的主键,那么它就是外键。笛卡尔积联结(不指定联结条件时)生成的记录条目是单纯的第一个表的行乘以第二个表的列数。用得最多的是等值联结也叫内部联结。
高级联结还有自连接,是指查询中的两张表是同一张表,它通常作为外部语句用来代替从相同表中检索数据时使用的子查询。自然联结使每个列只返回一次。外部联结是指联结包含了那些在相关表中没有关联行的行。例如列出所有产品及其订购数量,包括没有人订购的产品。LEFT OUTER JOIN指选择左边表的所有行。
组合查询是指采用UNION等将两个查询结果取并集。
视图是查看存储在别处的数据的一种工具,它本身并不包含数据,因此表的数据修改了,视图返回的数据也将随之修改,因此如果使用了复杂或嵌套视图会对性能有较大的影响。视图的作用之一是隐藏复杂的SQL通常会涉及到联结查询。
存储过程类似于批处理,包含了一条或多条SQL语句。语法:
CALL name()//来调用存储过程
游标有DECLARE定义,游标与存储过程是绑定的,存储过程处理完成,游标就会消失。游标被打开后可以使用FETCH语句访问每一行。
触发器是在某个时间发生时自动执行某条SQL语句。语法:
CREATE TRIGGER name AFTER INSERT ON talbe_name FOR EACH ROW
事务处理可以维护数据库的完整性,保证批量的操作要么完全执行,要么完全不执行。包括事务、回退、提交、保留点几个关键术语。ROLLBACK只能在一个事务处理内使用。他不能回退CREATE和DROP操作。使用COMMIT保证事务提交。复杂的事务处理需要部分提交或回退,因此我们需要使用保留点SAVEPOINT。可以使用ROLLBACK TO savepoint_name。保留点越多越好。保留点在事务执行完成后自动释放。
三、Oracle数据库中有关触发器问题
1、触发器是一种特殊类型的存储过程它不同于存储过程触发器主要是通过事件进行触发而被执行的触发器的触发事件分可为类分别是DML事件 DDL事件和数据库事件而存储过程可以通过存储过程名字而被直接调用当对某一表进行诸如UPDATE INSERT DELETE这些操作时 SQL Server就会自动执行触发器所定义的SQL语句从而确保对数据的处理必须符合由这些SQL语句所定义的规则
2、触发器是特定事件出现的时候自动执行的代码块类似于存储过程但是用户不能直接调用他们
3、触发器的种类可划分为种数据操纵语言(DML)触发器替代(INSTEAD OF)触发器数据定义语言(DDL)触发器数据库事件触发器
4、数据操纵语言(DML)触发器简称DML触发器是定义在表上的触发器创建在表上由DML事件引发的触发器编写DML触发器时的两点要素是确定触发的表即在其上定义触发器的表确定触发的事件 DML触发器的触发事件有INSERT UPDATE和DELETE三种;替代触发器简称INSTEADOF触发器创建在视图上用来替换对视图进行的删除插入和修改操作;数据定义语言(DDL)触发器简称DDL触发器定义在模式上触发事件是数据对象的创建和修改;数据库事件触发器定义在整个数据库或模式上触发事件是数据库事件
5、 ORACLE产生数据库触发器的语法为
6、 CREATE [OR REPLACE] TRIGGER触发器名
7、{BEFORE|AFTER|INSTEAD OF}触发事件 [OR触发事件 ]
8、触发器名触发器对象的名称由于触发器是数据库自动执行的因此该名称只是一个名称没有实质的用途一个触发器可由多个不同的数据操纵语言操作触发在触发器中可用INSERTING DELETING UPDATING谓词来区别不同的数据操纵语言操作这些谓词可以在IF分支条件语句中作为判断条件来使用
9、触发时间指明触发器何时执行该值可取触发的时间有BEFORE和AFTER两种分别表示触发动作发生在DML语句执行之前和语句执行之后确定触发级别有语句级触发器和行级触发器两种语句级触发器表示SQL语句只触发一次触发器行级触发器表示SQL语句影响的每一行都要触发一次
10、 Before表示在数据库动作之前触发器执行;在SQL语句的执行过程中如果存在行级BEFORE触发器则SQL语句在对每一行操作之前都要先执行一次行级BEFORE触发器然后才对行进行操作如果存在行级AFTER触发器则SQL语句在对每一行操作之后都要再执行一次行级AFTER触发器
11、 after表示在数据库动作之后出发器执行如果存在语句级AFTER触发器则在SQL语句执行完毕后要最后执行一次语句级AFTER触发器
12、触发事件指明哪些数据库动作会触发此触发器指INSERT DELETE或UPDATE事件事件可以并行出现中间用OR连接;
13、 insert数据库插入会触发此触发器;
14、 update数据库修改会触发此触发器;
15、 delete数据库删除会触发此触发器
16、 for each row表示触发器为行级触发器省略则为语句级触发器对表的每一行触发器执行一次
17、触发器的创建者或具有DROP ANY TIRGGER系统权限的人才能删除触发器删除触发器的语法如下
18、可以通过命令设置触发器的可用状态使其暂时关闭或重新打开即当触发器暂时不用时可以将其置成无效状态在使用时重新打开该命令语法如下
19、 ALTER TRIGGER触发器名{DISABLE|ENABLE}
20、其中 DISABLE表示使触发器失效 ENABLE表示使触发器生效
21、同存储过程类似触发器可以用SHOW ERRORS检查编译错误
22、如果有多个触发器被定义成为相同时间相同事件触发且最后定义的触发器是有效的则最后定义的触发器被触发其他触发器不执行触发器体内禁止使用MIT ROLLBACK SAVEPOINT语句也禁止直接或间接地调用含有上述语句的存储过程定义一个触发器时要考虑上述多种情况并根据具体的需要来决定触发器的种类
23、触发器的主要作用就是其能够实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性除此之外触发器还有其它许多不同的功能
24、()强化约束(Enforce restriction)
25、触发器能够实现比CHECK语句更为复杂的约束
26、触发器可以侦测数据库内的操作从而不允许数据库中未经许可的指定更新和变化
27、()级联运行(Cascaded operation)
28、触发器可以侦测数据库内的操作并自动地级联影响整个数据库的各项内容例如某个表上的触发器中包含有对另外一个表的数据操作(如删除更新插入)而该操作又导致该表上触发器被触发
29、()存储过程的调用(Stored procedure invocation)
30、为了响应数据库更新触发器可以调用一个或多个存储过程甚至可以通过外部过程的调用而在DBMS(数据库管理系统)本身之外进行操作
31、由此可见触发器可以解决高级形式的业务规则或复杂行为限制以及实现定制记录等一些方面的问题例如触发器能够找出某一表在数据修改前后状态发生的差异并根据这种差异执行一定的处理此外一个表的同一类型(INSERT UPDATE DELETE)的多个触发器能够对同一种数据操作采取多种不同的处理