正则表达式高级用法
发布时间:2025-05-19 20:07:17 发布人:远客网络

一、正则表达式高级用法
1、上一章分享了正式表达式的入门知识,以及单字符、多字符常用的匹配方法,对于工作维护过程中已经够用,但是有时候只使用基础知识来实现就会比较麻烦,如果使用高级用法就会比较方便很多。
2、例如:匹配一个HTML文件中两个<B>标签中的文件。
3、从上一章内容的知识可以想到的表达式可能如下:
4、但是这个表达式配置的结果是 AK</B> and<B>HI,而不是我们想要的 AK和 HI。
5、实现很简单,就是在原有“贪婪型”元字符后面加上一个?号,如下表格
6、前面的元字符都是对紧挨着前面的一个字符有效,例如表达式 the{3}匹配 theee字符串,假如我们想匹配连续三个 the字符串怎么办呢,这就涉及到子表达式的概念。
7、把一个表达式匹配的内容做为一个单独的元素嵌入到另外一个表达式中,那这个做为独立元素的表达式就是子表达式,需要使用()括起来。这个跟数学的表达式概念很类似。
8、并且子表达与数学表达式还有一个类似的地方就是,正则表达式的子表达式也可以嵌套使用
9、假如我们再加个条件:我们想匹配连续三个 the或者连续三个 you,怎么实现?这就是正则表达式的选择操作符,也叫或操作符了
10、上面的问题就可以使用正则表达式(the|you){3}来表示
11、当一个模式的全部或者部分内容由一对括号括起来时,就对表达式进行了分组(其实就是放在()中的子表达式),并且把分组匹配到内容捕获并且临时存放在内存中。这就是捕获分组,可以在后面表达式中使用就叫后向引用,或者叫回溯引用。
12、默认情况下,分组是从左到右依次排序从1编号,第一个分组就是1,第二个分组就是2等等。
13、后向引用很简单就是一个 \或者$后面跟相应编号即可。例如 \1或者$1就表示引用第一个捕获分组。
14、前面讲捕获分组都是通过位置编号来访问,在perl和python、.NET等语言中还支持对捕获分组命名。这样就比较容易理解
15、顾名思义,与捕获分组相反,就是不会将分组匹配的内容放在内存中。主要是为了提高性能。
16、使用方法:在分组的开头加上?:,例如(?:the)
17、环视是一种非捕获分组,它根据某个模式之前或者之后的内容要求匹配其他模式。环视也称为零宽度断言。
18、(?(id/name)yes-pattern|no-pattern)
19、如果给定的 id或 name存在,将会尝试匹配 yes-pattern;否则就尝试匹配 no-pattern, no-pattern可选;
20、例如:email样式匹配(<)?(\w+@\w+(?:\.\w+)+)(?(1)>|$),当<存在时,则最后要匹配>;否则匹配结束符$
二、正则表达式里边<.+>什么意思
正则表达式里边<.+?>表示匹配:“<”开始,其后至少含有1个除了“>”的任意字符,且再遇到“>”,就结束匹配。
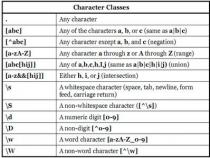
+表示:匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
*表示:匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。
?表示:匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。
例如:对“<><b>”的字符串进行正则模式<.+?>匹配,输入为:<><b>。
1、只能输入m~n位的数字:"^\d{m,n}$"。
2、只能输入零和非零开头的数字:"^(0|[1-9][0-9]*)$"。
3、只能输入有两位小数的正实数:"^[0-9]+(\.[0-9]{2})?$"。
4、只能输入有1~3位小数的正实数:"^[0-9]+(\.[0-9]{1,3})?$"。
5、只能输入非零的正整数:"^\+?[1-9][0-9]*$"。
6、只能输入非零的负整数:"^\-[1-9][0-9]*$"。
7、只能输入长度为3的字符:"^.{3}$"。
8、只能输入由26个英文字母组成的字符串:"^[A-Za-z]+$"。
9、只能输入由26个大写英文字母组成的字符串:"^[A-Z]+$"。
10、只能输入由26个小写英文字母组成的字符串:"^[a-z]+$"。
参考资料来源:百度百科-正则表达式
三、正则表达式()是什么意思
想匹配一个“人”字,但是只想匹配中国人的人字,不想匹配法国人的人,就可以用一下表达式
所以,楼主的表达式与其他通配符连用才能起到效果。
这个就表示匹配以“任意字符连着一个小写字母”开头的数字,只匹配数字。
正则表达式的其他模式修饰符的用法
console.log("我是中国人".replace(/我是(?=中国)/,"rr"))
打印出:rr中国人(匹配的是中国前面的'我是')
console.log("我是中国人".replace(/(?!中国)/,"rr"))
console.log("我是中国人".replace(/(?:中国)/,"rr"))
console.log("我是中国人".replace(/(?<=中国)人/,"rr"))
console.log("我是中国人".replace(/(?<!中国)/,"rr"))