正则表达式位置匹配攻略【转】
发布时间:2025-05-19 16:18:03 发布人:远客网络

一、正则表达式位置匹配攻略【转】
正则表达式是匹配模式,要么匹配字符,要么匹配位置。请记住这句话。
然而大部分人学习正则时,对于匹配位置的重视程度没有那么高。
位置是相邻字符之间的位置。比如,下图中箭头所指的地方:
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
比如我们把字符串的开头和结尾用"#"替换(位置可以替换成字符的!):
多行匹配模式时,二者是行的概念,这个需要我们的注意:
\b是单词边界,具体就是\w和\W之间的位置,也包括\w和^之间的位置,也包括\w和$之间的位置。
比如一个文件名是"[JS] Lesson_01.mp4"中的\b,如下:
为什么是这样呢?这需要仔细看看。
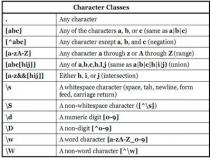
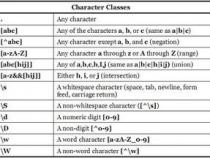
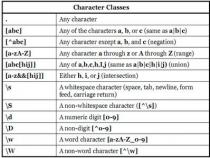
首先,我们知道,\w是字符组[0-9a-zA-Z_]的简写形式,即\w是字母数字或者下划线的中任何一个字符。而\W是排除字符组[^0-9a-zA-Z_]的简写形式,即\W是\w以外的任何一个字符。
此时我们可以看看"[#JS#]#Lesson_01#.#mp4#"中的每一个"#",是怎么来的。
第一个"#",两边是"["与"J",是\W和\w之间的位置。
第二个"#",两边是"S"与"]",也就是\w和\W之间的位置。
第三个"#",两边是空格与"L",也就是\W和\w之间的位置。
第四个"#",两边是"1"与".",也就是\w和\W之间的位置。
第五个"#",两边是"."与"m",也就是\W和\w之间的位置。
第六个"#",其对应的位置是结尾,但其前面的字符"4"是\w,即\w和$之间的位置。
知道了\b的概念后,那么\B也就相对好理解了。
\B就是\b的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉\b,剩下的都是\B的。
具体说来就是\w与\w、\W与\W、^与\W,\W与$之间的位置。
比如上面的例子,把所有\B替换成"#":
(?=p),其中p是一个子模式,即p前面的位置。
比如(?=l),表示'l'字符前面的位置,例如:
而(?!p)就是(?=p)的反面意思,比如:
二者的学名分别是positive lookahead和negative lookahead。
中文翻译分别是正向先行断言和负向先行断言。
ES6中,还支持positive lookbehind和negative lookbehind。
也有书上把这四个东西,翻译成环视,即看看左边或看看右边。
但一般书上,没有很好强调这四者是个位置。
比如(?=p),一般都理解成:要求接下来的字符与p匹配,但不能包括p的那些字符。
而在本人看来(?=p)就与^一样好理解,就是p前面的那个位置。
对于位置的理解,我们可以理解成空字符""。
比如"hello"字符串等价于如下的形式:
因此,把/ hello$/写成/ ^hello$$$/,是没有任何问题的:
也就是说字符之间的位置,可以写成多个。
把位置理解空字符,是对位置非常有效的理解方式。
因为此正则要求只有一个字符,但该字符后面是开头。
比如把"12345678",变成"12,345,678"。
可见是需要把相应的位置替换成","。
因为逗号出现的位置,要求后面3个数字一组,也就是\d{3}至少出现一次。
写完正则后,要多验证几个案例,此时我们会发现问题:
因为上面的正则,仅仅表示把从结尾向前数,一但是3的倍数,就把其前面的位置替换成逗号。因此才会出现这个问题。
怎么解决呢?我们要求匹配的到这个位置不能是开头。
我们知道匹配开头可以使用^,但要求这个位置不是开头怎么办?
easy,(?!^),你想到了吗?测试如下:
如果要把"12345678 123456789"替换成"12,345,678 123,456,789"。
此时我们需要修改正则,把里面的开头^和结尾$,替换成\b:
要求当前是一个位置,但不是\b前面的位置,其实(?!\b)说的就是\B。
因此最终正则变成了:/\B(?=(\d{3})+\b)/g
密码长度6-12位,由数字、小写字符和大写字母组成,但必须至少包括2种字符。
此题,如果写成多个正则来判断,比较容易。但要写成一个正则就比较困难。
那么,我们就来挑战一下。看看我们对位置的理解是否深刻。
不考虑“但必须至少包括2种字符”这一条件。我们可以容易写出:
4.3.2判断是否包含有某一种字符
假设,要求的必须包含数字,怎么办?此时我们可以使用(?=.*[0-9])来做。
比如同时包含数字和小写字母,可以用(?=. [0-9])(?=. [a-z])来做。
我们可以把原题变成下列几种情况之一:
4.同时包含数字、小写字母和大写字母
以上的4种情况是或的关系(实际上,可以不用第4条)。
上面的正则看起来比较复杂,只要理解了第二步,其余就全部理解了。
/(?=.*[0-9])^[0-9A-Za-z]{6,12}$/
对于这个正则,我们只需要弄明白(?=.*[0-9])^即可。
表示开头前面还有个位置(当然也是开头,即同一个位置,想想之前的空字符类比)。
(?=. [0-9])表示该位置后面的字符匹配. [0-9],即,有任何多个任意字符,后面再跟个数字。
翻译成大白话,就是接下来的字符,必须包含个数字。
“至少包含两种字符”的意思就是说,不能全部都是数字,也不能全部都是小写字母,也不能全部都是大写字母。
那么要求“不能全部都是数字”,怎么做呢?(?!p)出马!
位置匹配相关的案例,挺多的,不一而足。
感谢你看到这里,本文也要结束了。
如果有更好的例子,也可以帮我补充补充。
最后,我们该想到,陆游诗人对前端做的最大贡献是:
纸上得来终觉浅,绝知此事要躬行。
二、notepad++正则表达式 字符串详解
正则表达式是一个查询的字符串,它包含一般的字符和一些特殊的字符,特殊字符可以扩展查找字符串的能力,正则表达式在查找和替换字符串的作用不可忽视,它能很好提高工作效率。
文本编辑器 Notepad++ v6.3.3绿色多国语言版 点击下载
|匹配表达式左边和右边的字符.例如,“ab|bc”匹配“ab”或者“bc”.
[]匹配列表之中的任何单个字符.例如,“[ab]”匹配“a”或者“b”.“[0-9]”匹配任意数字.
[^]匹配列表之外的任何单个字符.例如,“[^ab]”匹配“a”和“b”以外的字符.“[^0-9]”匹配任意非数字字符.
*其左边的字符被匹配任意次(0次,或者多次).例如“be*”匹配“b”,“be”或者“bee”.
+其左边的字符被匹配至少一次(1次,或者多次).例如“be+”匹配“be”或者“bee”但是不匹配“b”.
?其左边的字符被匹配0次或者1次.例如“be?”匹配“b”或者“be”但是不匹配“bee”.
^其右边的表达式被匹配在一行的开始.例如“^A”仅仅匹配以“A”开头的行.
()影响表达式匹配的顺序,并且用作表达式的分组标记.
/转义字符.如果你要使用“/”本身,则应该使用“//”.
【1】正则表达式应用——替换指定内容到行尾
希望每次遇到“abc”,则替换“abc”以及其后到行尾的内容为“abc efg”
①在替换对话框,查找内容里输入“abc.*”
②同时勾选“正则表达式”复选框,然后点击“全部替换”按钮
注意:其实就是正则表达式替换,这里只是把一些曾经提出的问题加以整理,单纯从正则表达式本身来说,就可以引申出成千上万种特例。
【2】正则表达式应用——数字替换
asdadas123asdasdas456asdasdasd789asdasd
asdadas[123]asdasdas[456]asdasdasd[789]asdasd
在替换对话框里面,勾选“正则表达式”复选框;
在查找内容里面输入“[0-9][0-9][0-9]”,不含引号
“替换为:”里面输入“[/0/1/2]”,不含引号
范围为你所操作的范围,然后选择替换即可。
实际上这也是正则表达式的使用特例,“[0-9]”表示匹配0~9之间的任何特例,同样“[a-z]”就表示匹配a~z之间的任何特例
上面重复使用了“[0-9]”,表示连续出现的三个数字
“/0”代表第一个“[0-9]”对应的原型,“/1”代表第二个“[0-9]”对应的原型,依此类推
“[”、“]”为单纯的字符,表示添加“[”或“]”,如果输入“其它/0/1/2其它”,则替换结果为:
asdadas其它123其它asdasdas其它456其它asdasdasd其它789其它asdasd
如果将查找内容“[0-9][0-9][0-9]”改为“[0-9]*[0-9]”,对应1或 123或 12345或…
相关内容还有很多,可以自己参考正则表达式的语法仔细研究一下
【3】正则表达式应用——删除每一行行尾的指定字符
因为这几个字符在行中也是出现的,所以肯定不能用简单的替换实现
这个也算正则表达式的用法,其实仔细看正则表达式应该比较简单,不过既然有这个问题提出,说明对正则表达式还得有个认识过程,解决方法如下
在替换对话框中,启用“正则表达式”复选框
在查找内容里面输入“345”表示从行尾匹配
如果从行首匹配,可以用“^”来实现,不过 EditPlus有另一个功能可以很简单的删除行首的字符串
c.在弹出对话框里面输入要清除的行首字符,确定
【4】正则表达式应用——替换带有半角括号的多行
几百个网页中都有下面一段代码:
在替换对话框启用“正则表达式”选项,这时就可以完成替换了
【5】正则表达式应用——删除空行
启动EditPlus,打开待处理的文本类型文件。
①、选择“查找”菜单的“替换”命令,弹出文本替换对话框。选中“正则表达式”复选框,表明我们要在查找、替换中使用正则表达式。然后,选中“替换范围”中的“当前文件”,表明对当前文件操作。
②、单击“查找内容”组合框右侧的按钮,出现下拉菜单。
③、下面的操作添加正则表达式,该表达式代表待查找的空行。(技巧提示:空行仅包括空格符、制表符、回车符,且必须以这三个符号之一作为一行的开头,并且以回车符结尾,查找空行的关键是构造代表空行的正则表达式)。
直接在”查找”中输入正则表达式“^[/t]*/n”,注意/t前有空格符。
(1)选择“从行首开始匹配”,“查找内容”组合框中出现字符“^”,表示待查找字符串必须出现在文本中一行的行首。
(2)选择“字符在范围中”,那么在“^”后会增加一对括号“[]”,当前插入点在括号中。括号在正则表达式中表示,文本中的字符匹配括号中任意一个字符即符合查找条件。
(3)按一下空格键,添加空格符。空格符是空行的一个组成成分。
(4)选择“制表符”,添加代表制表符的“/t”。
(5)移动光标,将当前插入点移到“]”之后,然后选择“匹配 0次或更多”,该操作会添加星号字符“*”。星号表示,其前面的括号“[]”内的空格符或制表符,在一行中出现0个或多个。
(6)选择“换行符”,插入“/n”,表示回车符。
④、“替换为”组合框保持空,表示删除查找到的内容。单击“替换”按钮逐个行删除空行,或单击“全部替换”按钮删除全部空行(注意:EditPlus有时存在“全部替换”不能一次性完全删除空行的问题,可能是程序BUG,需要多按几次按钮)。
1.在汉化的时候,是否经常碰到这样的语句需要翻译:
“Error adding the comment!”;
如果有很多类似的文件一个一个翻译显然很累而且感觉很无聊。
其实可以这样处理,在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
这样替换之后发生了什么?结果是:
“在增加the post时发生错误!”;
“在增加the comment时发生错误!”;
“在增加the user时发生错误!”;
ok,接下来你会怎么做?当然再替换一次把the post、the comment、the user替换成你要翻译的词。得到最后的结果:
在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
这样替换之后发生了什么?结果是:
在汉化量很大而且句式比较单调的情况下对效率的提高很明显!
解释一下:([^!|"|;]*)的意思是不等于!和”和;中的任何一个,意思就是这3个字符之外的所有字符将被选中(替换区域);
/1即被选中的替换区域所在的新位置(复制到这个新位置)。
3.经常手工清理一行一行地删除文本文件里面的空白行,其实可以交给Editplus更好的完成,在Editplus里面用替换功能,在替换对话框选中“正则表达式”复选框:
替换部分为空就可以删除空白行了,执行一下看看:)
abandon[2''b9nd2n]v.抛弃,放弃
abandonment[2''b9nd2nm2nt]n.放弃
abbreviation[2bri:vi''ei62n]n.缩写
abeyance[2''bei2ns]n.缓办,中止
ability[2''biliti]n.能力
able[''eibl]adj.有能力的,能干的
abnormal[9b''n0:m2l]adj.反常的,变态的
aboard[2''b0:d]adv.船(车)上
替换:@@@@@”/1″,”/2″,”/3″,
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
@@@@@”abide”,”[2''baid]“,”v.遵守”,
@@@@@”ability”,”[2''biliti]“,”n.能力”,
@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,
@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,
@@@@@”abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,@@@@@”abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,@@@@@”abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,@@@@@”abeyance”,”[2''bei2ns]“,”n.缓办,中止”,@@@@@”abide”,”[2''baid]“,”v.遵守”,@@@@@”ability”,”[2''biliti]“,”n.能力”,@@@@@”able”,”[''eibl]“,”adj.有能力的,能干的”,@@@@@”abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,@@@@@”aboard”,”[2''b0:d]“,”adv.船(车)上”,@@@@@”abolish”,”[2''b0li6]“,”v.废除,取消”,@@@@@”abolition”,”[9b2''li62n]“,”n.废除,取消”
“abandon”,”[2''b9nd2n]“,”v.抛弃,放弃”,
“abandonment”,”[2''b9nd2nm2nt]“,”n.放弃”,
“abbreviation”,”[2bri:vi''ei62n]“,”n.缩写”,
“abeyance”,”[2''bei2ns]“,”n.缓办,中止”,
“abide”,”[2''baid]“,”v.遵守”,
“ability”,”[2''biliti]“,”n.能力”,
“able”,”[''eibl]“,”adj.有能力的,能干的”,
“abnormal”,”[9b''n0:m2l]“,”adj.反常的,变态的”,
“aboard”,”[2''b0:d]“,”adv.船(车)上”,
“abolish”,”[2''b0li6]“,”v.废除,取消”,
三、正则表达式{0,6}作用是什么
一、正则表达式的概念1、简介全称:regular express简称:regex或RE作用:是用来简洁表达一组字符串的表达式或者说是一种通用的字符表达框架.2、举...
2018年11月21日-操作字符串是正则表达式唯一的作用验证用户名长度是否合法验证密码是否符...{0,1}*{0,}允许出现大小写字母最少 6位最多10字符串边界修饰符 ^表示以...什么是正则表达式 a)例子:'/<img\s+src=b)乱七八糟的一堆字符堆砌在一起,神秘...
2013年12月16日-'o{0,}'则等价于'o*'。{n,m} m和n均为非负整数,其中n<= m。最少匹配 n次.../jim{2,6}/上述正则表达式规定字符m可以在匹配对象中连续出现2-6次,因此,...
2015年10月16日-正则表达式是由英文词语regular expression翻译过来的,就是符合某种规则的...因此{0,}和*一样,{1,}和+的作用一样。你可以用<<\b[1-9][0-9]{3}\b>>匹配...下面来看吧! 1.什么是正则表达式基本说来,正则表达式是一种用来描述一定数量文本...
[图文 ] 2017年12月4日- 30分钟内让你明白正则表达式是什么,并对它有一些基本的了解,让你可以...然后是一个0,后面跟着2个数字({2}),然后是)或-或空格中的一个,它出...