mysql分布式数据库适合做数据仓库么
发布时间:2025-05-14 20:30:32 发布人:远客网络
一、mysql分布式数据库适合做数据仓库么
数据仓库就是数据库,只不过是按照业界不同的提法说法不同而已;一般的数据仓库的说法是要建立一个高性能的可查询数据库,一般说来是提供高效的查询而不是交互。
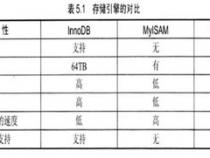
MySQL现有的几种数据库从5.5后缺省的数据引擎是Innodb,性能在查询上和MyISAM差不多,不过对事物的支持更加好。如果需要建立一个有规模的数据仓库首先必须考虑查询和聚合运算的效率问题,从MySQL内部的函数的使用效率出发选用innodb可以支持复杂的存储过程让运算集中在服务器上运行,可以高效的发挥服务器的运算性能和SQL集合运算的效率。
数据仓库的数据源可能来自不同的操作系统和数据库,怎么把数据同步到本地可以参考通用的方法,作为数据仓库需要考虑的是数据的一致性,比如一个流程的不同环节的数据来自不同的数据库,这时就需要考虑怎么来定制来保证数据的时效和一致,比如不允许第一步的数据还未进行同步,第二步的数据就已经同步到本地,这样的话后台的应用在读取数据的时候就会非常的混乱
数据仓库一般是从业务数据库导出到另外一个独立数据库作为计算分析,这样的好处在于把计算分开,避免非业务的大规模运算对正常业务的影响。即使软硬件崩溃也不会对正常业务造成影响,而数据重建只需要按照原来的方法恢复即可。在往数据仓库上同步数据的过程要灵活考虑数据同步的方法,缺省可直接使用Mysql的主从备份。如果不想对业务服务器造成太多影响,也可以采用自己定制的方法来进行增量备份和差异备份。
能够交由SQL完成的工作最好全部使用SQL来完成聚合,表和表进行联合的时候先进行添加约束,和外部的程序,比如统计分析的计算,尽量让SQL输出一个计算后的数据集给后台应用。
二、MySQL分表实现的方法及步骤简介mysql下如何分表
随着数据量越来越大,MySQL的单表存储数据容易遇到瓶颈,表性能下降,查询效率变慢。为了解决这个问题,MySQL提供了分表功能,即将一个大表拆分成多个小表存储,可以有效提高查询效率。下面介绍MySQL分表的实现方法及步骤。
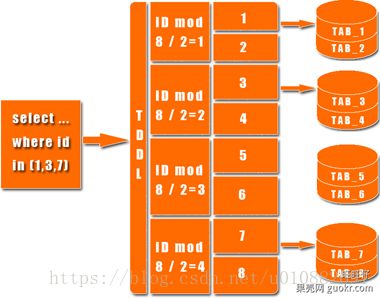
分表的实现原理是通过将一个大表拆分成若干个小表存储,通过增加一个分表字段对数据进行分配,将数据按照分表字段的值进行分布式存储,例如同一天的数据存储到同一张表中。这样可以避免单表数据过多导致效率下降的问题。
MySQL分表主要有两种方式,一种是垂直分表,即按照列进行拆分,将不同的列存储到不同的表中;另一种是水平分表,即按照行进行拆分,将不同行存储到不同的表中。
MySQL分表虽然提高了查询效率,但是也存在一些问题。如何保证数据的一致性,如何进行跨分表的查询等,这些都是需要考虑的问题。
在原表结构中增加一个字段用来标注该数据属于哪个分表。
例如:CREATE TABLE `order_info`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`order_time` DATETIME NOT NULL,
`total_price` DECIMAL(10,2) NOT NULL,
在此基础上增加一个分表字段:CREATE TABLE `order_info`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`order_time` DATETIME NOT NULL,
`total_price` DECIMAL(10,2) NOT NULL,
根据分表字段的不同值创建不同的分表。例如,根据日期进行分表:
CREATE TABLE `order_info_20190101`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`order_time` DATETIME NOT NULL,
`total_price` DECIMAL(10,2) NOT NULL,
CREATE TABLE `order_info_20190102`(
`id` INT(11) NOT NULL AUTO_INCREMENT,
`order_time` DATETIME NOT NULL,
`total_price` DECIMAL(10,2) NOT NULL,
原表中的数据需要迁移到相应的分表中,可以通过INSERT INTO SELECT来实现数据的快速迁移。
例如:INSERT INTO `order_info_20190101` SELECT* FROM `order_info` WHERE `order_time` BETWEEN‘2019-01-01 00:00:00’ AND‘2019-01-01 23:59:59’;
对于需要跨分表查询的语句,需要使用UNION ALL来合并查询结果。
例如:SELECT `id`,`user_id`,`order_time`,`total_price`,`table_num`,`table_id` FROM `order_info_20190101` WHERE `id`= 123 UNION ALL SELECT `id`,`user_id`,`order_time`,`total_price`,`table_num`,`table_id` FROM `order_info_20190102` WHERE `id`= 456;
MySQL分表是一种有效提高数据查询效率的方法,但是也存在一系列问题需要注意。在实现过程中需要考虑数据一致性、跨表查询的问题,还需要注意查询条件中分表字段的使用。分表可以避免数据量过大的单表查询效率下降的问题,可以提高系统的整体性能。
三、基于mogileFS搭建分布式文件系统--海量小文件的存储利器
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。分布式文件系统的设计基于客户机/服务器模式。一个典型的网络可能包括多个供多用户访问的服务器。另外,对等特性允许一些系统扮演客户机和服务器的双重角色。例如,用户可以“发表”一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样。
当下我们处在一个互联网飞速发展的信息社会,在海量并发连接的驱动下每天所产生的数据量必然以几何方式增长,随着信息连接方式日益多样化,数据存储的结构也随着发生了变化。在这样的压力下使得人们不得不重新审视大量数据的存储所带来的挑战,例如:数据采集、数据存储、数据搜索、数据共享、数据传输、数据分析、数据可视化等一系列问题。
传统存储在面对海量数据存储表现出的力不从心已经是不争的事实,例如:纵向扩展受阵列空间限制、横向扩展受交换设备限制、节点受文件系统限制。
然而分布式存储的出现在一定程度上有效的缓解了这一问题,之所以称之为缓解是因为分布式存储在面对海量数据存储时也并非十全十美毫无压力,依然存在的难点与挑战例如:节点间通信、数据存储、数据空间平衡、容错、文件系统支持等一系列问题仍处在不断摸索和完善中。
2.分布式文件系统的一些解决方案
Google Filesystem适合存储海量大个文件,元数据存储与内存中
HDFS(Hadoop Filesystem)GFS的山寨版,适合存储大量大个文件
TFS(Taobao Filesystem)淘宝的文件系统,在名称节点上将元数据存储与关系数据库中,文件数量不在受限于名称节点的内容空间,可以存储海量小文件LustreOracle开发的企业级分布式系统,较重量级MooseFS基于FUSE的格式,可以进行挂载使用MogileFS
擅长存储海量的小数据,元数据存储与关系型数据库中
MogileFS是一个开源的分布式文件系统,用于组建分布式文件集群,由LiveJournal旗下DangaInteractive公司开发,Danga团队开发了包括 Memcached、MogileFS、Perlbal等不错的开源项目:(注:Perlbal是一个强大的Perl写的反向代理服务器)。MogileFS是一个开源的分布式文件系统。
目前使用 MogileFS的公司非常多,比如国外的一些公司,日本前几名的公司基本都在使用这个.
国内所知道的使用 MogileFS的公司有图片托管网站 yupoo又拍,digg,土豆,豆瓣,1号店,大众点评,搜狗,安居客等等网站.基本很多网站容量,图片都超过 30T以上。
1)应用层提供服务,不需要使用核心组件
2)无单点失败,主要有三个组件组成,分为tracker(跟踪节点)、mogstore(存储节点)、database(数据库节点)
3)自动复制文件,复制文件的最小单位不是文件,而是class
4)传输中立,无特殊协议,可以通过NFS或HTTP实现通信
5)简单的命名空间:没有目录,直接存在与存储空间上,通过域来实现
MogileFS的核心,是一个调度器,mogilefsd进程就是trackers进程程序,trackers的主要职责有:删除数据、复制数据、监控、查询等等.这个是基于事件的( event-based)父进程/消息总线来管理所有来之于客户端应用的交互(requesting operations to be performed),包括将请求负载平衡到多个"query workers"中,然后让 mogilefs的子进程去处理.
mogadm,mogtool的所有操作都要跟trackers打交道,Client的一些操作也需要定义好trackers,因此最好同时运行多个trackers来做负载均衡.trackers也可以只运行在一台机器上,使用负载均衡时可以使用搞一些简单的负载均衡解决方案,如haproxy,lvs,nginx等,
tarcker的配置文件为/etc/mogilefs/mogilefsd.conf,监听在TCP的7001端口
主要用来存储mogilefs的元数据,所有的元数据都存储在数据库中,因此,这个数据相当重要,如果数据库挂掉,所有的数据都不能用于访问,因此,建议应该对数据库做高可用
数据存储的位置,通常是一个HTTP(webDAV)服务器,用来做数据的创建、删除、获取,任何 WebDAV服务器都可以,不过推荐使用 mogstored. mogilefsd可以配置到两个机器上使用不同端口… mogstored来进行所有的 DAV操作和流量,IO监测,并且你自己选择的HTTP服务器(默认为 perlbal)用来做 GET操作给客户端提供文件.
典型的应用是一个挂载点有一个大容量的SATA磁盘.只要配置完配置文件后mogstored程序的启动将会使本机成为一个存储节点.当然还需要mogadm这个工具增加这台机器到Cluster中.
配置文件为/etc/mogilefs/mogstored.conf,监听在TCP的7500端口
应用程序请求打开一个文件(通过RPC通知到 tracker,找到一个可用的机器).做一个“create_open”请求.
tracker做一些负载均衡(load balancing)处理,决定应该去哪儿,然后给应用程序一些可能用的位置。
应用程序写到其中的一个位置去(如果写失败,他会重新尝试并写到另外一个位置去).
应用程序(client)通过”create_close”告诉tracker文件写到哪里去了.
tracker将该名称和域命的名空间关联(通过数据库来做的)
tracker,在后台,开始复制文件,知道他满足该文件类别设定的复制规则
然后,应用程序通过“get_paths”请求 domain+key(key==“filename”)文件, tracker基于每一位置的I/O繁忙情况回复(在内部经过 database/memcache/etc等的一些抉择处理),该文件可用的完整 URLs地址列表.
应用程序然后按顺序尝试这些URL地址.(tracker’持续监测主机和设备的状态,因此不会返回死连接,默认情况下他对返回列表中的第一个元素做双重检查,除非你不要他这么做..)
说明:1.用户通过URL访问前端的nginx
2.nginx根据特定的挑选算法,挑选出后端一台tracker来响应nginx请求
3.tracker通过查找database数据库,获取到要访问的URL的值,并返回给nginx
4.nginx通过返回的值及某种挑选算法挑选一台mogstored发起请求
6.nginx构建响应报文返回给客户端
角色运行软件ip地址反向代理nginx192.168.1.201存储节点与调度节点1
mogilefs192.168.1.202存储节点与调度节点2
mogilefs192.168.1.203数据库节点
关于数据库的编译安装,请参照本人相关博文,本处将不再累赘,本处使用的为yum源的安装方式安装mysql
4.安装mogilefs.安装mogilefs,可以使用yum安装,也可以使用编译安装,本处通过yum安装
可以看到在数据库中创建了一些表
8.配置192.168.1.203的mogilefs。切记不要初始化数据库,配置应该与192.168.1.202一样
9.尝试上传数据,获取数据,客户端读取数据
上传数据,在任何一个节点上传都可以
我们可以通过任何一个节点查看到数据
要想nginx能够实现对后端trucker的反向代理,必须结合第三方模块来实现
大功告成了,后续思路,前段的nginx和数据库都存在单点故障,可以实现高可用集群