Mysql分表和分区的区别,分库和分表区别
发布时间:2025-05-14 10:47:07 发布人:远客网络
一、Mysql分表和分区的区别,分库和分表区别
分表和分区的区别:
一、什么是mysql分表,分区
分表:从表面意思上看呢,就是把一张表分成N多个小表,具体请看:mysql分表的3种方法
分区:分区呢就是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上,具体请参考mysql分区功能详细介绍,以及实例
二、mysql分表和分区有什么区别呢
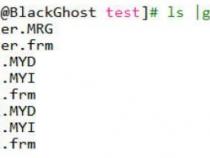
①mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完正的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构文件。
[root@BlackGhosttest]#ls|grepuser
user2.frm
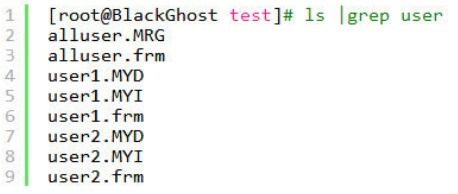
简单说明一下,上面的分表呢是利用了merge存储引擎(分表的一种),alluser是总表,下面有二个分表,user1,user2。他们二个都是独立的表,取数据的时候,我们可以通过总表来取。这里总表是没有.MYD,.MYI这二个文件的,也就是说,总表他不是一张表,没有数据,数据都放在分表里面。我们来看看.MRG到底是什么东西
简单说明一下,上面的分表呢是利用了merge存储引擎(分表的一种),alluser是总表,下面有二个分表,user1,user2。他们二个都是独立的表,取数据的时候,我们可以通过总表来取。这里总表是没有.MYD,.MYI这二个文件的,也就是说,总表他不是一张表,没有数据,数据都放在分表里面。我们来看看.MRG到底是什么东西
[root@BlackGhosttest]#catalluser.MRG|more
#INSERT_METHOD=LAST
从上面我们可以看出,alluser.MRG里面就存了一些分表的关系,以及插入数据的方式。可以把总表理解成一个外壳,或者是联接池。
从上面我们可以看出,alluser.MRG里面就存了一些分表的关系,以及插入数据的方式。可以把总表理解成一个外壳,或者是联接池。
②分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
[root@BlackGhosttest]#ls|grepaa
aa.par
从上面我们可以看出,aa这张表,分为二个区,p1和p3,本来是三个区,被我删了一个区。我们都知道一张表对应三个文件.MYD,.MYI,.frm。分区呢根据一定的规则把数据文件和索引文件进行了分割,还多出了一个.par文件,打开.par文件后你可以看出他记录了,这张表的分区信息,根分表中的.MRG有点像。分区后,还是一张,而不是多张表。
从上面我们可以看出,aa这张表,分为二个区,p1和p3,本来是三个区,被我删了一个区。我们都知道一张表对应三个文件.MYD,.MYI,.frm。分区呢根据一定的规则把数据文件和索引文件进行了分割,还多出了一个.par文件,打开.par文件后你可以看出他记录了,这张表的分区信息,根分表中的.MRG有点像。分区后,还是一张,而不是多张表。
如orderid,userid,ordertime,.....
按照时间分区。大部分只查询最近的订单数据,那么大部分只访问一个分区,比整个表小多了,数据库可以更加好的缓存,性能也提高了。这个是数据库分的,应用程序透明,无需修改。
①、分表后,数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。看下面的例子:
select* from alluser where id='12'表面上看,是对表alluser进行操作的,其实不是的。是对alluser里面的分表进行了操作。
②、分区呢,不存在分表的概念,分区只不过把存放数据的文件分成了许多小块,分区后的表呢,还是一张表。数据处理还是由自己来完成。
①、分表后,单表的并发能力提高了,磁盘I/O性能也提高了。并发能力为什么提高了呢,因为查寻一次所花的时间变短了,如果出现高并发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。磁盘I/O性能怎么搞高了呢,本来一个非常大的.MYD文件现在也分摊到各个小表的.MYD中去了。
②、mysql提出了分区的概念,我觉得就想突破磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
在这一点上,分区和分表的测重点不同,分表重点是存取数据时,如何提高mysql并发能力上;而分区呢,如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
①、分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式根分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。
②、分区实现是比较简单的,建立分区表,根建平常的表没什么区别,并且对开代码端来说是透明的。
三、mysql分表和分区有什么联系呢
1、都能提高mysql的性高,在高并发状态下都有一个良好的表面。
2、分表和分区不矛盾,可以相互配合的,对于那些大访问量,并且表数据比较多的表,我们可以采取分表和分区结合的方式(如果merge这种分表方式,不能和分区配合的话,可以用其他的分表试),访问量不大,但是表数据很多的表,我们可以采取分区的方式等。
从字面上简单理解,就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈,。
如果你的单机性能很低了,那可以尝试分库。分库,业务透明,在物理实现上分成多个服务器,不同的分库在不同服务器上。分区可以把表分到不同的硬盘上,但不能分配到不同服务器上。一台机器的性能是有限制的,用分库可以解决单台服务器性能不够,或者成本过高问题。
当分区之后,表还是很大,处理不过来,这时候可以用分库。
orderid,userid,ordertime,.....
上面这个就是一个简单的分库路由,根据userid选择分库,即不同的服务器
分库分表有垂直切分和水平切分两种。
3.1、何谓垂直切分,即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库workDB、商品数据库payDB、用户数据库userDB、日志数据库logDB等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
如userid,name,addr一个表,为了防止表过大,分成2个表。
3.2、何谓水平切分,当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如userID散列、按性别、按省,进行划分,然后存储到多个结构相同的表,和不同的库上。
例如,我们的userDB中的用户数据表中,每一个表的数据量都很大,就可以把userDB切分为结构相同的多个userDB:part0DB、part1DB等,再将userDB上的用户数据表userTable,切分为很多userTable:userTable0、userTable1等,然后将这些表按照一定的规则存储到多个userDB上。
3.3、应该使用哪一种方式来实施数据库分库分表,这要看数据库中数据量的瓶颈所在,并综合项目的业务类型进行考虑。
如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单明了、容易实施的垂直切分必是首选。
而如果数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑数据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负担。
在现实项目中,往往是这两种情况兼而有之,这就需要做出权衡,甚至既需要垂直切分,又需要水平切分。我们的游戏项目便综合使用了垂直与水平切分,我们首先对数据库进行垂直切分,然后,再针对一部分表,通常是用户数据表,进行水平切分。
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
4.3额外的数据管理负担和数据运算压力。
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
二、支持mysql分区表的版本有哪些
新一代MySQL产品---MySQL5.5已经面世,较之之前的5.1版本,将获得诸多特性方面的提升,简单总结如下:
InnoDB作为成熟、高效的事务引擎,目前已经广泛使用,但MySQL5.1之前的版本默认引擎均为MyISAM,此次MySQL5.5终于做到与时俱进,将默认数据库存储引擎改为InnoDB,并且引进了Innodb plugin 1.0.7。此次更新对数据库的好处是显而易见的:InnoDB的数据恢复时间从过去的一个甚至几个小时,缩短到几分钟(InnoDB plugin 1.0.7,InnoDB plugin 1.1,恢复时采用红-黑树)。InnoDB Plugin支持数据压缩存储,节约存储,提高内存命中率,并且支持adaptive flush checkpoint,可以在某些场合避免数据库出现突发性能瓶颈。
Multi Rollback Segments:原来InnoDB只有一个Segment,同时只支持1023的并发。现已扩充到128个Segments,从而解决了高并发的限制。
Metadata Locking(MDL) Framework替换LOCK_open mutex(lock),使得MySQL5.1及过去版本在多核心处理器上的性能瓶颈得到解决,官方表示将继续增强对MySQL多处理器支持,直至MySQL性能“不受处理器数量的限制”
MySQL复制特性是互联网公司应用非常广泛的特性,作为MySQL最实用最简单的扩展方式,过去的异步复制方式已经有些不上形势,对某些用户来说“异步复制”意味着极端情况下的数据风险,MySQL5.5将首次支持半同步(semi-sync replication)在MySQL的高可用方案中将产生更多更加可靠的方案。另外Slave fsync tunning;Relay log corruption recovery和Replication Heartbeat也将实现
MySQL 5.5的分区对用户绝对是个好消息,更易于使用的增强功能,以及TRUNCATE PARTITION命令都可以为DBA节省大量的时间,有时对最终用户亦如此:
1)非整数列分区:任何使用过MySQL分区的人应该都遇到过不少问题,特别是面对非整数列分区时,MySQL 5.1只能处理整数列分区,如果你想在日期或字符串列上进行分区,你不得不使用函数对其进行转换。很麻烦,而MySQL 5.5中新增了两类分区方法,RANG和LIST分区法,同时在新的函数中增加了一个COLUMNS关键词。在MySQL 5.1中使用分区另一个让人头痛的问题是date类型(即日期列),你不能直接使用它们,必须使用YEAR或TO_DAYS转换这些列,但在MySQL 5.5中情况发生了很大的变化,现在在日期列上可以直接分区,并且方法也很简单;
2)多列分区:COLUMNS关键字现在允许字符串和日期列作为分区定义列,同时还允许使用多个列定义一个分区;
3)可用性增强:truncate分区。分区最吸引人的一个功能是瞬间移除大量记录的能力,DBA都喜欢将历史记录存储到按日期分区的分区表中,这样可以定期删除过时的历史数据。但当你需要移除分区中的部分数据时,事情就不是那么简单了,删除分区没有问题,但如果是清空分区,就很头痛了,要移除分区中的所有数据,但需要保留分区本身,你可以:使用DELETE语句,但我们知道DELETE语句的性能都很差。使用DROP PARTITION语句,紧跟着一个EORGANIZE PARTITIONS语句重新创建分区,但这样做比前一个方法的成本要高出许多。MySQL 5.5引入了TRUNCATE PARTITION,它和DROP PARTITION语句有些类似,但它保留了分区本身,也就是说分区还可以重复利用。TRUNCATE PARTITION应该是DBA工具箱中的必备工具;
4)更多微调功能:TO_SECONDS:分区增强包有一个新的函数处理DATE和DATETIME列,使用TO_SECONDS函数,你可以将日期/时间列转换成自0年以来的秒数,如果你想使用小于1天的间隔进行分区,那么这个函数就可以帮到你。
5. Insert Buffering如果在buffer pool中没找到数据,那么直接buffer起来,避免额外的IO;Delete& Purge Buffering跟插入一样,如果buffer pool中没有命中,先buffer起来,避免额外的IO。
6. Support for Native AIO on Linux
以上的特性在MySQL 5.5的社区版当中都将包括,在MySQL企业版当中,除以上更新之外,Oracle还加强了更多实用的企业级功能,包括:
MySQL企业版将包含Innodb Hotbackup(这也许是MySQL和InnDB多年之后重新聚首的新亮点),从而一举解决过去MySQL无法进行可靠的在线实时物理备份的问题, InnoDB Hot Backup不需要你关闭你的服务器也不需要加任何锁或影响其它普通的数据操作,这对MySQL DBA来说应该是一个不错的消息。
2. MySQL Enterprise Monitor 2.2& Oracle Enterprise Monitor
是的,你没有看错,MySQL将可以被Oracle Enterprise Monitor监控,这是一个实现起来并不复杂,但在过去绝无可能的变化。并且MySQL企业版监控器(MySQL Enterprise Monitor)得到了更大的加强,版本更新至2.2,对MySQL服务器资源占用降低到可以忽略的地步,集成了监控,报警,SQL语句分析和给出优化建议,MySQL的一些开源监控方案相比之下显得过于简陋,对企业客户来说,MySQL变得更加可靠。
过去MySQL的图形界面工具做的实在是令人难以恭维,当然这也给众多MySQL管理工具提供了市场空间,现在Oracle打算将MySQL做得比SQL-Server更加简单易用,MySQL Workbench是一款专为MySQL设计的ER/数据库建模工具,可以用来设计和创建新的数据库图示,建立数据库文档,以及进行复杂的MySQL迁移等操作,因此内置workbench将使MySQL使用起来更简便高效。
4.关于未来的重要提醒:Oracle的管理工具,MySQL也将能够使用,当然MySQL 5.5我们还没看到这个变化,但变化已经在时间表上,MySQL社区版也能够被Oracle管理工具管理,前提你得是Oracle数据库的用户。
三、Mysql分表和分区的区别
什么是分表,从表面意思上看呢,就是把一张表分成N多个小表,具体请看mysql分表的3种方法
什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上,具体请参考mysql分区功能详细介绍,以及实例
二,mysql分表和分区有什么区别呢
a),mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完正的一张表,都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构文件。
[root@BlackGhost test]# ls|grep user
简单说明一下,上面的分表呢是利用了merge存储引擎(分表的一种),alluser是总表,下面有二个分表,user1,user2。他们二个都是独立的表,取数据的时候,我们可以通过总表来取。这里总表是没有.MYD,.MYI这二个文件的,也就是说,总表他不是一张表,没有数据,数据都放在分表里面。我们来看看.MRG到底是什么东西
[root@BlackGhost test]# cat alluser.MRG|more
从上面我们可以看出,alluser.MRG里面就存了一些分表的关系,以及插入数据的方式。可以把总表理解成一个外壳,或者是联接池。
b),分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
[root@BlackGhost test]# ls|grep aa
从上面我们可以看出,aa这张表,分为二个区,p1和p3,本来是三个区,被我删了一个区。我们都知道一张表对应三个文件.MYD,.MYI,.frm。分区呢根据一定的规则把数据文件和索引文件进行了分割,还多出了一个.par文件,打开.par文件后你可以看出他记录了,这张表的分区信息,根分表中的.MRG有点像。分区后,还是一张,而不是多张表。
a),分表后,数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。看下面的例子:
select* from alluser where id='12'表面上看,是对表alluser进行操作的,其实不是的。是对alluser里面的分表进行了操作。
b),分区呢,不存在分表的概念,分区只不过把存放数据的文件分成了许多小块,分区后的表呢,还是一张表。数据处理还是由自己来完成。
a),分表后,单表的并发能力提高了,磁盘I/O性能也提高了。并发能力为什么提高了呢,因为查寻一次所花的时间变短了,如果出现高并发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。磁盘I/O性能怎么搞高了呢,本来一个非常大的.MYD文件现在也分摊到各个小表的.MYD中去了。
b),mysql提出了分区的概念,我觉得就想突破磁盘I/O瓶颈,想提高磁盘的读写能力,来增加mysql性能。
在这一点上,分区和分表的测重点不同,分表重点是存取数据时,如何提高mysql并发能力上;而分区呢,如何突破磁盘的读写能力,从而达到提高mysql性能的目的。
a),分表的方法有很多,用merge来分表,是最简单的一种方式。这种方式根分区难易度差不多,并且对程序代码来说可以做到透明的。如果是用其他分表方式就比分区麻烦了。
b),分区实现是比较简单的,建立分区表,根建平常的表没什么区别,并且对开代码端来说是透明的。
三,mysql分表和分区有什么联系呢
1,都能提高mysql的性高,在高并发状态下都有一个良好的表面。
2,分表和分区不矛盾,可以相互配合的,对于那些大访问量,并且表数据比较多的表,我们可以采取分表和分区结合的方式(如果merge这种分表方式,不能和分区配合的话,可以用其他的分表试),访问量不大,但是表数据很多的表,我们可以采取分区的方式等。