为什么我的Python中没有requests模块
发布时间:2025-05-14 13:29:51 发布人:远客网络
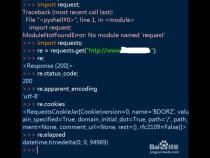
一、为什么我的Python中没有requests模块
1、可能有几种情况导致您无法在Python中找到requests模块:
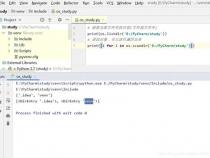
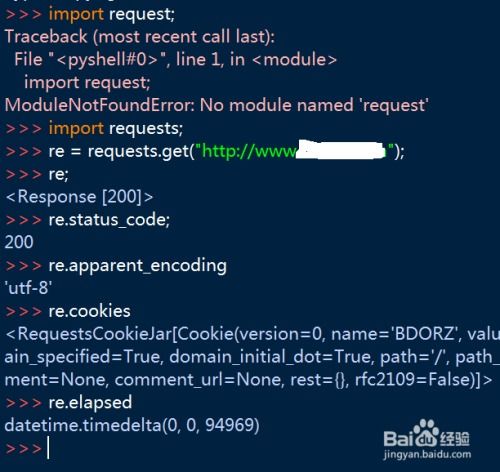
2、requests模块没有安装成功,可以使用以下命令重新安装:pip install requests
3、安装了多个版本的Python,而您使用的是没有安装requests模块的版本。可以在命令行中使用以下命令查看当前Python版本和模块安装路径:
4、如果您发现安装路径不在您当前Python版本的路径中,可以尝试使用以下命令安装模块:python-m pip install requests
5、可能是因为Python解释器与requests模块的路径不匹配导致的问题。可以尝试在Python脚本的开头添加以下代码,显式地告诉Python解释器查找requests模块的路径:
6、import os#添加 requests模块的安装路径
7、sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
8、希望这些解决方法能够帮助您找到并使用requests模块。
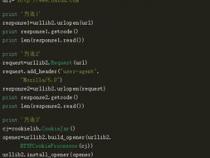
二、python 爬虫里面什么叫request
1、在Python爬虫中,request对象扮演着至关重要的角色。它本质上是从客户端向服务器发出请求的工具,包含用户提交的信息以及客户端的其他相关信息。客户端可以通过HTML表单或在网页地址后面提供参数的方式来提交数据。通过request对象的各种方法,可以方便地获取这些数据。
2、request的各种方法主要用于处理客户端浏览器提交请求中的各项参数和选项。在Python爬虫的具体应用中,request其实就是一个通过Python代码向服务器发送请求并获取相应返回信息的工具。它能够帮助我们模拟用户行为,实现数据抓取。
3、请求过程大致可以分为以下几个步骤:首先,我们使用Python中的requests库发送一个HTTP请求到目标服务器;然后,服务器响应请求并返回一些信息;接着,我们可以利用request对象的方法来解析和处理这些返回的信息。通过这种方式,我们可以轻松地从网页中提取所需的数据,进行进一步的处理和分析。
4、在实际应用中,request对象能够帮助我们实现各种功能,比如抓取网页内容、发送表单数据、获取API接口数据等。它不仅简化了数据抓取的过程,还极大地提高了工作效率。因此,熟悉和掌握request对象的使用方法,对于进行Python爬虫开发来说至关重要。
5、此外,request对象还可以帮助我们设置请求头、超时时间等参数,以适应不同的网络环境和需求。同时,通过request对象,我们还可以处理响应状态码,判断请求是否成功。这些功能使得request对象成为Python爬虫开发中不可或缺的一部分。
6、总之,request对象是Python爬虫中不可或缺的重要组成部分。它不仅能够帮助我们高效地获取网页数据,还能够灵活地应对各种网络环境和需求,是实现数据抓取的强大工具。
三、python爬虫错误显示“httperror400:badrequest”,应该
1、遇到“httperror400:badrequest”错误,通常意味着服务器端遇到了问题,可能是因为请求不被允许或者请求参数错误。这可能是由于服务器对爬虫的访问进行了限制,比如设置了访问频率阈值,导致了频繁请求被拦截。为了绕过这种限制,首先需要调整请求头headers,增强请求的伪装性。
2、具体步骤如下:在每次请求之后加入time.sleep(500),延时500毫秒,这可以减少服务器端对频繁请求的感知,降低被ban的风险。另外,可以考虑使用IP代理,代理可以隐藏真实IP地址,降低被识别为爬虫的可能性。免费的代理服务可以在一些网站如西祠网获取,使用前务必验证代理的连通性和有效性。在代理可用时,再进行图片下载操作,可以有效降低被ban的几率。
3、此外,频繁更换代理IP也是提高访问成功率的一种方式。下载几张图片后,更换代理IP地址,继续执行爬取任务。这样的操作能够有效降低对特定IP地址的依赖,同时增加了访问的随机性,从而更不容易被服务器识别为爬虫。
4、通过以上方法,可以有效解决“httperror400:badrequest”错误,提高爬虫程序的稳定性和成功率。关键在于合理调整请求策略,包括请求频率、使用代理以及适时更换IP地址,以适应服务器的反爬机制。