爬虫python能做什么
发布时间:2025-05-14 09:59:08 发布人:远客网络
一、爬虫python能做什么
能用来做:1、收集数据;由于爬虫程序是一个程序,程序运行得非常快,因此使用爬虫程序获取大量数据变得非常简单和快速。2、刷流量和秒杀;当爬虫访问一个网站时,如果网站无法识别访问来自爬虫,那么它可能将被视为正常访问,进而刷了网站的流量。
python爬虫程序可用于收集数据。这也是最直接和最常用的方法。由于爬虫程序是一个程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用爬虫程序获取大量数据变得非常简单和快速。
由于99%以上的网站是基于模板开发的,使用模板可以快速生成大量布局相同、内容不同的页面。因此,只要为一个页面开发了爬虫程序,爬虫程序也可以对基于同一模板生成的不同页面进行爬取内容。
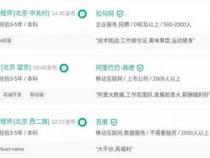
比如要调研一家电商公司,想知道他们的商品销售情况。这家公司声称每月销售额达数亿元。如果你使用爬虫来抓取公司网站上所有产品的销售情况,那么你就可以计算出公司的实际总销售额。此外,如果你抓取所有的评论并对其进行分析,你还可以发现网站是否出现了刷单的情况。数据是不会说谎的,特别是海量的数据,人工造假总是会与自然产生的不同。过去,用大量的数据来收集数据是非常困难的,但是现在在爬虫的帮助下,许多欺骗行为会赤裸裸地暴露在阳光下。
刷流量是python爬虫的自带的功能。当一个爬虫访问一个网站时,如果爬虫隐藏得很好,网站无法识别访问来自爬虫,那么它将被视为正常访问。结果,爬虫“不小心”刷了网站的流量。
除了刷流量外,还可以参与各种秒杀活动,包括但不限于在各种电商网站上抢商品,优惠券,抢机票和火车票。目前,网络上很多人专门使用爬虫来参与各种活动并从中赚钱。这种行为一般称为“薅羊毛”,这种人被称为“羊毛党”。不过使用爬虫来“薅羊毛”进行盈利的行为实际上游走在法律的灰色地带,希望大家不要尝试。
更多编程相关知识,请访问:编程教学!!以上就是小编分享的关于爬虫python能做什么?的详细内容希望对大家有所帮助,更多有关python教程请关注环球青藤其它相关文章!
二、python爬虫能做什么
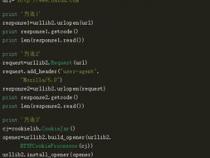
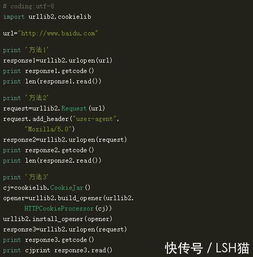
Python是一门非常适合开发网络爬虫的编程语言,相比于其他静态编程语言,Python抓取网页文档的接口更简洁;相比于其他动态脚本语言,Python的urllib2包提供了较为完整的访问网页文档的API。此外,python中有优秀的第三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。
1. URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2.网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3.网页解析器:解析出有价值的数据,存储下来,同时补充url到URL管理器。
Python爬虫通过URL管理器,判断是否有待爬URL,如果有待爬URL,通过调度器进行传递给下载器,下载URL内容,并通过调度器传送给解析器,解析URL内容,并将价值数据和新URL列表通过调度器传递给应用程序,并输出价值信息的过程。
你可以用爬虫爬图片,爬取视频等等你想要爬取的数据,只要你能通过浏览器访问的数据都可以通过爬虫获取。
scrapy:网络爬虫框架,不支持Python3;
portia:基于Scrapy的可视化爬虫;
restkit:Python的HTTP资源工具包。它可以让你轻松地访问HTTP资源,并围绕它建立的对象。
demiurge:基于PyQuery的爬虫微框架。
三、学习python爬虫可以练习爬哪些网站
学习Python爬虫可以练习爬取的网站多种多样,以下列举几类常见且具有挑战性的网站:
1.视频网站如B站(Bilibili):这类网站数据结构复杂,不仅包括视频内容,还有弹幕、评论等多种互动元素。通过爬虫获取弹幕、评论等信息,不仅需要理解网页结构,还要应对网站的反爬机制,如本例所示。
2.社交媒体平台如微博、知乎:这类网站上的信息丰富多样,包括用户动态、文章、问答等,需要熟练掌握解析复杂HTML结构、处理JavaScript动态加载内容等技巧。
3.电商网站如淘宝、京东:这类网站上的商品信息丰富且更新频繁,通过爬虫可以获取商品详情、价格、评价等数据,对数据抓取和处理能力要求较高。
4.新闻网站如CNN、BBC:这类网站提供实时新闻和深度报道,通过爬虫获取新闻标题、摘要、发布时间等信息,有助于快速掌握信息。
5.音乐网站如网易云音乐、QQ音乐:这类网站提供音乐资源,通过爬虫可以获取歌曲信息、评论、用户评分等,需要掌握HTML解析和API调用等技术。
6.学术资源网站如Google Scholar、PubMed:这类网站提供学术论文资源,通过爬虫可以获取论文标题、作者、摘要、引用次数等信息,对网页解析和数据提取能力要求较高。
通过练习爬取这些网站的数据,可以提升Python编程、网络爬虫技术、数据解析和处理能力,同时深入了解各网站的结构和数据特点。