Python 为什么要继承 object 类
发布时间:2025-05-14 02:40:07 发布人:远客网络
一、Python 为什么要继承 object 类
1.使用 Python时,遇到 class A和 class A(object)的写法,在 Py2中是有概念上和功能上的区别的,分别称为经典类(旧式类)old-style(classic-style)与新式类的区别new-style。
2.历史原因:.2.2以前的时候type和object还不统一.在2.2统一到3之间,要用class Foo(object)来申明新式类,因为它的type是< type‘type’>.不然的话,生成的类的type就是< type‘classobj’>
3.为什么要继承object类?主要目的是便于统一操作。在python 3.X中已经默认继承object类
二、Python C语言API教程(二、PyObject是什么)
PyObject是Python C语言API中的一个核心对象。以下是关于PyObject的详细解释:
1. PyObject概览在Python中,一切皆对象,这一点在C语言API中尤为明显。 PyObject不仅指语法层面的事物,还包括解释器内部结构。所有这些都可以视为PyObject对象,其基础类在C层面即为PyObject。
2. PyObject结构 PyObject是一个C结构体,主要包含两个成员:ob_refcnt和ob_type。 ob_refcnt:记录对象的引用次数。 ob_type:指向对象描述,即对象的类型信息。
3. PyTypeObject与插槽 PyTypeObject是对象描述,也是一个对象。在Python的C编程中,每个对象都有对应的PyTypeObject。 PyTypeObject包含多个属性,这些属性可以按需初始化。通过宏Py_READY进行默认值初始化,这些属性被称为“插槽”。
4.引用计数 Python采用引用计数作为内存管理机制。当创建对象实例并分配内存时,引用计数为1。其他对象需要持有该对象时,引用计数加1;释放对象时,引用计数减1。当引用计数减至0时,对象内存立即释放。用户无需直接操作引用计数,而是通过API宏Py_INCREF和Py_DECREF进行引用加减。
5.引用所有权与偷引用 CPython引入引用所有权概念,规定负责管理引用计数的对象。存在两种所有权类型,并引入偷引用行为,即将API管理的对象转由用户管理。
6.常用方法 Python C语言API提供了一系列与PyObject相关的常用方法,用于创建、操作和管理PyObject对象。
通过上述内容,我们可以对PyObject有一个全面而深入的了解,这对于使用Python C语言API进行开发至关重要。
三、Python 的 type 和 object 之间是怎么一种关系
1、节选自Python Documentation 3.5.2的部分解释
Objects are Python’s abstraction for data. All data in a Python program is represented by objects or by relations between objects.(In a sense, and in conformance to Von Neumann’s model of a“stored program computer,” code is also represented by objects.)
对象是Python对数据的抽象。 Python程序中的所有数据都由对象或对象之间的关系表示。(在某种意义上,并且符合冯·诺依曼的“存储程序计算机”的模型,代码也由对象表示的)。
Every object has an identity, a type and a value. An object’s identity never changes once it has been created; you may think of it as the object’s address in memory. The‘is‘ operator compares the identity of two objects; the id() function returns an integer representing its identity.
每个对象都有一个标识,一个类型和一个值。对象的身份一旦创建就不会改变;你可以把它看作内存中的对象地址。'is'运算符比较两个对象的标识; id()函数返回一个表示其身份的整数。
An object’s type determines the operations that the object supports(e.g.,“does it have a length?”) and also defines the possible values for objects of that type. The type() function returns an object’s type(which is an object itself). Like its identity, an object’s type is also unchangeable.
对象的类型决定对象支持的操作(例如,“它有长度吗?”),并且还定义该类型对象的可能值。type()函数返回一个对象的类型(它是一个对象本身)。与它的身份一样,对象的类型也是不可改变的。
type(object_or_name, bases, dict)
type(object)-> the object's type
type(name, bases, dict)-> a new type
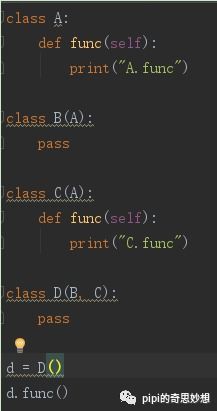
从上面三个图可以看出,对象obeject是最基本的类型type,它是一个整体性的对数据的抽象概念。相对于对象object而言,类型type是一个稍微具体的抽象概念,说它具体,是因为它已经有从对象object细化出更具体抽象概念的因子,这就是为什么type(int)、type(float)、type(str)、type(list)、type(tuple)、type(set)等等的类型都是type,这也是为什么instance(type, object)和instance(object, type)都为True的原因,即类型type是作为int、float等类型的整体概念而言的。那么,为什么issubclass(type, object)为True,而issubclass(object, type)为Flase呢?从第二张图,即从继承关系可以看到,type是object的子类,因此前者为True,后者为False。若从Python语言的整体设计来看,是先有对象,后有相对具体的类型,即整体优先于部分的设计思想。
如果从更加本质的视角去看待这些问题的话,就要从Python Documentation-->3. Data Model-->3.1 Objects,values and types找原因了[请参考Python官方标准库],从标准库里可以看到:
object是Python对数据的抽象,它是Python程序对数据的集中体现。
每个对象都有一个标识,一个类型和一个值。
对象的类型决定对象支持的操作。
某些对象的值可以更改。其值可以改变的对象称为可变对象;对象的值在创建后不可更改的对象称为不可变对象。
因此,从Python整体设计体系来看的话,就是先有对象,再有标识、类型和值,接着是对对象的操作等等,这也就解释了图3的结果形成的原因了。