为什么Pandas中用【object】类型代表字符串列
发布时间:2025-05-13 18:11:58 发布人:远客网络
一、为什么Pandas中用【object】类型代表字符串列
1、在数据处理领域,尤其针对视频数据,使用Pandas库进行操作时,你可能会发现Pandas将字符串表示为object类型。这个现象背后的原因,与Pandas的数据结构和底层存储机制紧密相关。
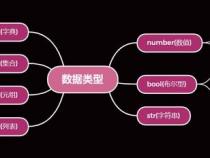
2、让我们深入探讨。在Pandas中,每一列数据被定义为Series对象,这个对象底层依赖于Numpy库进行数据存储和操作。Numpy和Pandas都包含object数据类型,其独特之处在于可以容纳任何Python对象,包括字符串、列表以及其他Python对象,仅除去数值对象。
3、选择object数据类型来表示字符串列,是基于其灵活性。它能够容纳可变长度的字符串和其他Python对象,这一特性与Numpy数据类型(如int64或float64)有显著区别。Numpy的数据类型大小固定,仅用于数值表示,而object类型则更为宽松,可以适应不同大小和类型的值。
4、因此,无论在视频数据处理或其他数据集分析中,Pandas将字符串列表示为object类型,体现出其对数据多样性的包容性。这种灵活性意味着任何非数字数据列都会以object类型在Pandas中进行表示,从而确保了数据处理过程的高效性和准确性。
二、5个例子学会Pandas中的字符串过滤
1、文本数据处理在数据分析领域至关重要,尤其在处理文本数据时,需要更多清理步骤以提取有用信息。Pandas库提供了丰富的工具帮助我们实现这一目标,本文将通过实例展示如何使用Pandas进行字符串过滤。
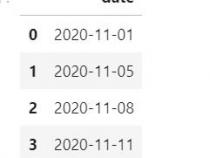
2、在开始之前,我们首先导入Pandas库和数据集。假设我们有一个包含6行4列的DataFrame,接下来我们学习5种用于过滤文本数据的不同方法。
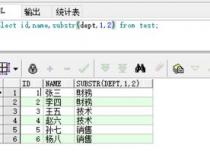
3、第一个方法是检查字符串是否包含特定单词或字符序列,使用Pandas的contains方法查找描述字段包含"used car"的行。为了在DataFrame中找到所有包含"used"和"car"的行,我们需分别查找这两个词,因为它们可能不连接在一起。
4、接下来,我们探讨根据字符串长度进行过滤,假设我们对长度超过15个字符的描述感兴趣。可以使用内置的len函数实现这一目的,或者通过str访问器进行更简便的操作。
5、使用Python的内置函数,如startswith和endswith,可以根据字符串的第一个或最后一个字母进行过滤。此外,我们还能够检查前n个字符,例如,选择以"A-0"开头的行。
6、文本数据处理中,Python内置的字符串函数可以被应用到PandasDataFrames中。例如,过滤价格列中非数字字符,如$和k,可以使用isnumeric函数。同样,保留字母数字字符可以使用isalphanum函数。
7、Pandas的count方法用于计算单个字符或字符序列的出现次数。例如,查找描述栏中"used"出现的次数。
8、通过将count方法与比较操作结合,我们可以进行条件过滤。例如,统计描述栏中"used"的出现次数并进行比较。
9、本文介绍了PandasDataFrames中基于字符串值的5种过滤方法。虽然数值类型的数据分析更常见,但文本数据同样重要且包含有价值信息。文本数据的清理与预处理对于数据分析和建模至关重要。
三、Pandas 数据类型怎么转换为字符串或者数值类型
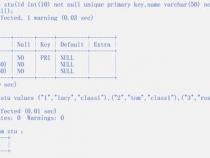
1、Pandas数据类型转换至字符串或数值类型是数据分析中常见的步骤。首先,对于非数值变量如category类型,如tips数据中的sex、smoker、day和time,为了便于后续处理,通常需要将其转换为字符串。这通过astype方法实现,Python的str、float、int等内置类型,以及Numpy库支持的其他dtype,都可用于数据类型转换。
2、在处理id列时,虽然数值型,但在计算中可能无实际意义,转换为字符串类型更为合适。同样,使用astype方法时,需要注意处理缺失值,如total_bill列,Pandas在尝试转换'missing'值为float时会报错。此时,可以借助pandas的to_numeric函数进行转换,它允许定义错误处理策略,如忽略或替换缺失值。
3、to_numeric函数的另一个特性是向下转型,即当无法直接转换为更高级别的数据类型时,会自动降级。例如,将total_bill转换为float类型时,实际得到的是float32,这意味着在内存占用上有所节省。因此,在处理Pandas数据类型转换时,需要灵活运用astype和to_numeric,以满足数据处理的需求并优化内存使用。