将mysql数据库中的单个库的数据同步到redis数据库中
发布时间:2025-05-12 16:20:36 发布人:远客网络
一、将mysql数据库中的单个库的数据同步到redis数据库中
1、(self,key,where,refvalue,value):"""在key对应的列表的某一个值前或后插入一个新值 r.linsert("list2","before","11","00")#往列表中左边第一个出现的元素"11"前插入元素"00":param key::param where: before or after:param refvalue:标杆值,即:在它前后插入数据:param value:要插入的数据:return:""" try: if str(where).lower() not in [‘before‘,‘after‘]: raise ValueError(‘where值只能是 before或 after‘) return self.rd.linsert(key,where,refvalue,value) except Exception as e: return"Func linsertkeys Error:%d%s"%(e.args[0],e.args[1]) def lsetkeys(self,key,index,value):"""对key对应的list中的某一个索引位置重新赋值:param key::param index:索引值,从0开始:param value::return:""" try: if not isinstance(index,int): raise TypeError(‘index只能是整数‘) return self.rd.lset(key,index,value) except Exception as e: return"Func lsetkeys:%d%s"%(e.args[0],e.args[1]) def lremkeys(self,key,num,value):"""在key对应的list中删除指定的值:param key::param value::param num: num=0,删除列表中所有指定值,num=2,从前到后,删除2个,num=1,从前到后,删除左边第一个,num=-2,从后到前,删除两个:return:""" return self.rd.lrem(key,num,value) def lpopkeys(self,key):"""在key对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素:param key::return:""" return self.rd.lpop(key) def rpopkeys(self,key):"""在key对应的列表的右侧获取第一个元素并在列表中移除,返回值则是第一个元素:param key::return:""" return self.rd.rpop(key) def ltrimkeys(self,key,start,end):"""在key对应的list中移除没有在start- end索引之间的值:param key::param start:索引的开始位置:param end:索引的结束位置:return:""" return self.rd.ltrim(key,start,end) def lindexkeys(self,key,index):"""在name对应的list中根据索引获取列表元素:param key::param index::return:""" return self.rd.lindex(key,index) def rpoplpushkeys(self,srckey,dstkey):"""将元素从一个表移动到另一个表中(从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边):param srckey::param detkey::return:""" return self.rd.rpoplpush(srckey,dstkey) def brpoplpushkeys(self,srckey,dstkey,timeout=0):"""从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧,可以设置超时:param srckey::param dstkey::param timeout:当seckey对应的list中没有数据时,阻塞等待其有数据的超时时间单位为秒,0表示永远阻塞:return:""" return self.rd.brpoplpush(srckey,dstkey,timeout) def blpopkeys(self,keys,timeout):"""将多个列表排序,按照从左到右去pop对应的list元素:param keys::param timeout:超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0表示永远阻塞:return:""" return self.rd.blpop(keys,timeout) def brpopkeys(self,keys,timeout):"""将多个列表排序,按照从右到左去pop对应的list元素:param keys::param timeout:超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0表示永远阻塞:return:""" return self.rd.brpop(keys,timeout) def llenkeys(self,key):"""返回key的数据长度:param key::return:""" return self.rd.llen(key) def lrangekeys(self,key,start=0,end=-1):"""获取key的全部数据值通常与llen联用:param key::param start:起始位置(包括):param end:结束位置(包括):return:""" return self.rd.lrange(key,start,end) def listiterkeys(self,key):""" list增量迭代:param key::return:返回yield生成器""" list_count= self.rd.llen(key) for index in range(list_count): yield self.rd.lindex(key,index)# set操作 def saddkeys(self,key,values):""":key对应的集合中添加元素,重复的元素将忽略 saddkeys(‘xxx‘,1,2,3,4,5):param key::param values::return:""" return self.rd.sadd(key,values) def scardkeys(self,key):"""获取元素个数,类似于len:param key::return:""" return self.rd.scard(key) def smemnerkeys(self,key):"""获取key对应的集合的所有成员:param key::return:""" return self.rd.smembers(key) def sscankeys(self, key, cursor=0, match=None, count=None):"""获取集合中所有的成员--元组形式:param key::param cursor::param match::param count::return:""" return self.rd.sscan(key,cursor,match,count) def sscaniterkeys(self,key,match=0,count=None):"""获取集合中所有的成员--迭代器方式:param key::param match::param count::return:""" return self.rd.sscan_iter(key,match,count) def sdiffkeys(self,keys,*args):"""在第一个key对应的集合中且不在其他key对应的集合的元素集合 sdiffkeys(‘a‘,‘b)在集合a中并且不再集合b中:param keys::param args::return:""" return self.rd.sdiff(keys,args) def sdiffstorekeys(self,dstkey,keys,*args):"""获取第一个key对应的集合中且不在其他name对应的结合,在将其加入到dstkey对应的集合中:param dstkey::param keys::param args::return:""" res= self.rd.sdiffstore(dstkey,keys,args) return res def sinterkeys(self,keys,*args):"""获取多个keys对应集合的交集:param keys::param args::return:""" return self.rd.sinter(keys,args) def sinterstorekeys(self,dstkey,keys,*args):"""获取多个keys对应集合的交集,再将其加入到dstkey对应的集合中:param dstkey::param keys::param args::return:""" res= self.rd.sinterstore(dstkey,keys,args) return res def sunionkeys(self,keys,*args):"""获取多个key对应的集合的并集:param keys::param args::return:""" return self.rd.sunion(keys,args) def sunionstorekeys(self,dstkey,keys,*args):"""获取多个key对应集合的并集,并将其结果保存到dstkey对应的集合中:param dstkey::param keys::param args::return:""" return self.rd.sunionstore(dstkey,keys,args) def sismemberkeys(self,key,value):"""检查value是否是key对应的结合的成员,结果返回True or False:param key::param value::return: True or False""" return self.rd.sismember(key,value) def smovekeys(self,srckey,dstkey,value):"""将某个成员从一个集合中移动到另一个集合:param srckey::param dstkey::param value::return:""" return self.rd.smove(srckey,dstkey,value) def spopkeys(self,key):"""从集合移除一个成员,并将其返回,说明一下,集合是无序的,所有都是随机删除的:param key::return:""" return self.rd.spop(key) def sremkeys(self,key,values):"""在key对应的集合中删除某些值 sremkeys(‘xx‘,‘a‘,‘b‘):param key::param values::return:""" return self.rd.srem(key,values)#有序集合 zset操作 def zaddkeys(self,key,mapping):"""在key对应的有序集合中添加元素 zaddkeys(‘xx‘,{‘k1‘:1,‘k2‘:2}):param key::param args::param kwargs::return:""" return self.rd.zadd(key,mapping) def zcardkeys(self,key):"""获取有序集合元素的个数:param key::return:""" return self.rd.zcard(key) def zrangekeys(self,key,start,stop,desc=False,withscores=False,score_cast_func=float):"""获取有序集合索引范围内的元素:param key::param start:索引起始位置:param stop:索引结束位置:param desc:排序规则,默认按照分数从小到大排序:param withscores:是否获取元素的分数,默认之火去元素的值:param score_cast_func:对分数进行数据转换的函数:return:""" return self.rd.zrange(key,start,stop,desc,withscores,score_cast_func) def zrevrangekeys(self,key,start,end,withscores=False,score_cast_func=float):"""从大到小排序:param key::param start::param end::param withscores::param score_cast_func::return:""" return self.rd.zrevrange(key,start,end,withscores,score_cast_func) def zrangebyscorekeys(self,key,min,max,start=None,num=None,withscores=False,score_cast_func=float):"""按照分数返回获取key对应的有序集合的元素 zrangebyscore("zset3", 15, 25))##在分数是15-25之间,取出符合条件的元素 zrangebyscore("zset3", 12, 22, withscores=True)#在分数是12-22之间,取出符合条件的元素(带分数):param key::param min::param max::param start::param num::param withscores::param score_cast_func::return:""" return self.rd.zrangebyscore(key,min,max,start,num,withscores,score_cast_func) def zrevrangebyscorekeys(self,key,max,min,start=None,num=None,withscores=False,score_cast_func=float):"""按照分数范围获取有序集合的元素并排序(默认按照从大到小排序):param key::param max::param min::param start::param num::param withscores::param score_cast_func::return:""" return self.rd.zrevrangebyscore(key,max,min,start,num,withscores,score_cast_func) def zscankeys(self,key,cursor=0,match=None,count=None,score_cast_func=float):"""获取所有元素--默认按照分数顺序排序:param key::param cursor::param match::param count::param score_cast_func::return:""" return self.rd.zscan(key,cursor,match,count,score_cast_func) def zscaniterkeys(self,key,match=None,count=None,score_cast_func=float):"""获取所有元素的迭代器:param key::param match::param count::param score_cast_func::return:""" return self.rd.zscan_iter(key,match,count,score_cast_func) def zcountkeys(self,key,min,max):"""获取key对应的有序集合中分数在[min,max]之间的个数:param key::param min::param max::return:""" return self.rd.zcount(key,min,max) def zincrbykey(self,key,value,amount=1):"""自增key对应的有序集合key对应的分数:param key::param value::param amount::return:""" return self.rd.zincrby(key,amount,value) def zrankeys(self,key,value):"""获取某个值在key对应的有序集合中的索引(从0开始),默认是从小到大顺序:param key::param value::return:""" return self.rd.zrank(key,value) def zrevrankey(self,key,value):"""获取某个值在key对应的有序集合中的索引,默认是从大到小顺序:param key::param value::return:""" return self.rd.zrevrank(key,value) def zremkeys(self,key,values):"""删除key对应的有序集合中值是value的成员:param key::param value::return:""" return self.rd.zrem(key,values) def zremrangebyrankeys(self,key,min,max):"""删除根据排行范围删除,按照索引删除:param key::param min::param max::return:""" return self.rd.zremrangebyrank(key,min,max) def zremrangebyscoreskeys(self,key,min,max):"""删除根据分数范围删除,按照分数范围删除:param key::param min::param max::return:""" return self.rd.zremrangebyscore(key,min,max) def zscoreskeys(self,key,value):"""获取key对应有序集合中value对应的分数:param key::param value::return:""" return self.rd.zscore(key,value)#其他常用操作 def deletekeys(self,*keys):"""根据删除redis中的任意数据类型 deletekeys(‘gender‘,‘cname‘)可以删除多个key:param keys::return:""" return self.rd.delete(*keys) def existskeys(self,key):"""检测redis的key是否存在,存在就返回True,False则不存在:param key::return:""" return self.rd.exists(key) def getkeys(self,pattern=""):"""根据模型获取redis的key getkeys*匹配数据库中所有 key。 getkeys h?llo匹配 hello, hallo和 hxllo等。 getkeys hllo匹配 hllo和 heeeeello等。 getkeys h[ae]llo匹配 hello和 hallo,但不匹配 hillo:param pattern::return:""" return self.rd.keys(pattern) def expirekeys(self,key,time):"""设置超时时间,为某个key设置超时时间:param key::param time:秒:return:""" return self.rd.expire(key,time) def renamekeys(self,srckey,dstkey):"""对key进行重命名:param srckey::param dstkey::return:""" return self.rd.rename(srckey,dstkey) def randomkeys(self):"""随即获取一个key(不删除):return:""" return self.rd.randomkey() def getkeytypes(self,key):"""获取key的类型:param key::return:""" return self.rd.type(key) def scankeys(self,cursor=0,match=None,count=None):"""查看所有key,终极大招:param cursor::param match::param count::return:""" return self.rd.scan(cursor,match,count) def scaniterkeys(self,match=None,count=None):"""查看所有key的迭代器,防止内存被撑爆:param match::param count::return:""" return self.rd.scan_iter(match,count) def dbsizekeys(self):"""当前redis包含多少条数据:return:""" return self.rd.dbsize() def savekeys(self):"""将数据刷入磁盘中,保存时阻塞:return:""" return self.rd.save() def flushdbkeys(self,asynchronous=False):"""清空当前数据库的所有数据,请谨慎使用:param asynchronous:异步:return:""" return self.rd.flushdb(asynchronous) def flushallkeys(self,asynchronous=False):"""清空redis所有库中的数据,不到最后时刻请不要使用:param asynchronous:异步:return:""" return self.rd.flushall(asynchronous)#创建管道""" redis默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline是原子性操作。管道(pipeline)是redis在提供单个请求中缓冲多条服务器命令的基类的子类。它通过减少服务器-客户端之间反复的TCP数据库包,从而大大提高了执行批量命令的功能。""" def createpipe(self):""" pipeline(transaction=False)#默认的情况下,管道里执行的命令可以保证执行的原子性,执行pipe= r.pipeline(transaction=False)可以禁用这一特性。 pipe= r.pipeline()#创建一个管道 pipe.set(‘name‘,‘jack‘) pipe.set(‘role‘,‘sb‘) pipe.sadd(‘faz‘,‘baz‘) pipe.incr(‘num‘)#如果num不存在则vaule为1,如果存在,则value自增1 pipe.execute() pipe.set(‘hello‘,‘redis‘).sadd(‘faz‘,‘baz‘).incr(‘num‘).execute():return:""" return self.rd.pipeline() def disconectkeys(self): return self.connPoor.disconnect()class QueryAllData(): def __init__(self): self.show_tables= config.mysql_show_tables self.desc_table= config.mysql_desc_table self.query_info= config.mysql_query_info def query_tables_info(self): mhelper= MySQLHelper() tables_list= mhelper.queryTableNums(self.show_tables) tables_attr={} for table in tables_list: rows= mhelper.queryAll(self.query_info%table) tables_attr[table]= rows mhelper.close() return tables_attr def mysql2redis(self,redisobj): mysql_data= self.query_tables_info() for keys, values in mysql_data.items():# keys为表名字 for val in values:# val为每一行的数据 keysorted= sorted(val.keys()) for s in keysorted:#s为数据的key item=‘%s:%s‘%(keys,str(val[‘id‘])) ischange= redisobj.hgetkey(item,s) if ischange!= val[s]: redisobj.hsetkey(item,s,val[s])if __name__=="__main__": queryalldata= QueryAllData() rhelper= RedisHelper() while True: queryalldata.mysql2redis(rhelper)
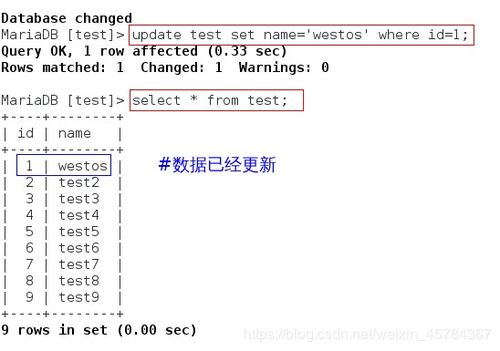
2、将mysql数据库中的单个库的数据同步到redis数据库中
3、标签:pipeline打印取数据countversion清空memberscores==
4、标签 pipeline打印取数据 count version清空 members cores==
二、Redis 如何保持和 MySQL 数据一致
redis在启动之后,从数据库加载数据。
不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取
数据首先都写到数据库,之后更新redis(先写redis再写mysql,如果写入失败事务回滚会造成redis中存在脏数据)
在并发不高的情况下,读操作优先读取redis,不存在的话就去访问MySQL,并把读到的数据写回Redis中;写操作的话,直接写MySQL,成功后再写入Redis(可以在MySQL端定义CRUD触发器,在触发CRUD操作后写数据到Redis,也可以在Redis端解析binlog,再做相应的操作)
在并发高的情况下,读操作和上面一样,写操作是异步写,写入Redis后直接返回,然后定期写入MySQL
1.当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
2.在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
遇到这种情况,可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后对队列个数取摸,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据,一般情况下是可以取到的。
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时间内返回,该解决方案最大的风险在于可能数据更新很频繁,导致队列中挤压了大量的更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库,像遇到这种情况,一般要做好足够的压力测试,如果压力过大,需要根据实际情况添加机器。
这里还是要做好压力测试,多模拟真实场景,并发量在最高的时候QPS多少,扛不住就要多加机器,还有就是做好读写比例是多少
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上
4、热点商品的路由问题,导致请求的倾斜
某些商品的读请求特别高,全部打到了相同的机器的相同丢列里了,可能造成某台服务器压力过大,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是很大,但是确实有可能某些服务器的负载会高一些。
搜索微信号(ID:芋道源码),可以获得各种 Java源码解析。
并且,回复【书籍】后,可以领取笔者推荐的各种 Java从入门到架构的书籍。
三、redis如何与数据库数据同步
1、我们大多倾向于使用这种方式,也就是将数据库中的变化同步到Redis,这种更加可靠。Redis在这里只是做缓存。
2、方案1(推荐学习:Redis视频教程)
3、做缓存,就要遵循缓存的语义规定:
4、读:读缓存redis,没有,读mysql,并将mysql的值写入到redis。
5、写:写mysql,成功后,更新或者失效掉缓存redis中的值。
6、对于一致性要求高的,从数据库中读,比如金融,交易等数据。其他的从Redis读。
7、这种方案的好处是由mysql,常规的关系型数据库来保证持久化,一致性等,不容易出错。
8、这里还可以基于binlog使用mysql_udf_redis,将数据库中的数据同步到Redis。
9、但是很明显的,这将整体的复杂性提高了,而且本来我们在系统代码中能很轻易完成的功能,现在需要依赖第三方工具,而且系统的整个边界扩大了,变得更加不稳定也不好管理了。