怎么提取pdf中固定位置文字
发布时间:2025-05-12 05:40:03 发布人:远客网络
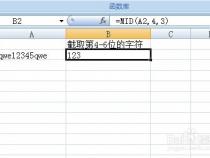
一、怎么提取pdf中固定位置文字
1、打开PDF文件,创建一个PdfFileReader对象,然后获取指定页码的PdfFilePage对象。使用此对象的extract_text方法提取该页面上的文本。例如,要提取页面2的文本,可以执行以下代码:
2、提取的文本存储在text变量中。这样,就可以将此文本用于任何需要处理PDF页面文本的应用。
3、此外,也可以使用Python的other libraries,如PyMuPDF(formerly known as fitz)来处理PDF文件。以下是使用PyMuPDF提取PDF中固定位置文字的示例代码:
4、这段代码会读取名为"example.pdf"的文件,并将所有页面的文本合并到一个字符串中。然后关闭文件以释放资源。
5、提取固定位置的文字时,还需要考虑PDF的编码类型。如果文本是Unicode编码,确保在处理文本时使用正确的格式。例如,使用Python处理时,确保文本始终使用Unicode格式。
6、使用这些库,可以轻松地在Python中提取PDF文件中的固定位置文字。根据具体需求,可以进一步优化代码,例如,处理多语言文本,处理加密PDF文件或提取特定文本格式的文本等。
二、pdf里面的文字怎么提取
1、其实咱们也不需要其他专业的程序进行提取,日常使用的百度网盘就能很好地提取PDF中的文字,接下来我教你怎么提取。
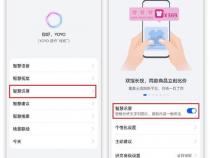
2、第一步,打开百度网盘APP,未安装的请直接在应用商店搜索即可。
3、第二步,点击首页顶部的“文档”按钮,或直接点击热门工具中的“文字识别”工具。
4、若通过顶部文档进入,则需要点击“文字识别”按钮即可进入识别界面。
5、第三步,进入扫描页面,对准PDF文件拍照或从相册中选取PDF截图。
6、第四步,将识别区域调整到需要识别的位置。
7、第五步,识别完成后可选择“复制文字”或“导出文字”。
8、是不是很简单呢?赶紧去试试吧!
三、怎样提取pdf里的文字出来
1、实现工具:Office 2003中自带的Microsoft Office Document Imaging
应用情景:目前国外很多软件的支持信息都使用PDF方式进行发布,如果没有Adobe Reader,无法查看其内容,如果没有相关的编辑软件又无法编辑PDF文件。转换为DOC格式则可以实现编辑功能。尽管有些软件也可以完成PDF转换为DOC的工作,但很多都不支持中文,我们利用Office 2003中的Microsoft Office Document Imaging组件来实现这一要求最为方便。
第一步:首先使用Adobe Reader打开待转换的PDF文件,接下来选择“文件→打印”菜单,在打开的“打印”设置窗口中将“打印机”栏中的“名称”设置为“Microsoft Office Document Image Writer”,确认后将该PDF文件输出为MDI格式的虚拟打印文件。
编辑提示:如果你在“名称”设置的下拉列表中没有找到“Microsoft Office Document Image Writer”项,那证明你在安装Office 2003的时候没有安装该组件,请使用Office 2003安装光盘中的“添加/删除组件”更新安装该组件。
第二步:运行Microsoft Office Document Imaging,并利用它来打开刚才保存的MDI文件,选择“工具→将文本发送到Word”菜单,并在弹出的窗口中勾选“在输出时保持图片版式不变”,确认后系统提示“必须在执行此操作前重新运行OCR。这可能需要一些时间”,不管它,确认即可。
编辑提示:目前,包括此工具在内的所有软件对PDF转DOC的识别率都不是特别完美,而且转换后会丢失原来的排版格式,所以大家在转换后还需要手工对其进行后期排版和校对工作。
2、实现工具:Solid Converter PDF
应用情景:利用Office 2003中的Microsoft Office Document Imaging组件来实现PDF转Word文档在一定程度上的确可以实现PDF文档到Word文档的转换,但是对于很多“不规则”的PDF文档来说,利用上面的方法转换出来的Word文档中常常是乱码一片。为了恢复PDF的原貌,推荐的这种软件可以很好地实现版式的完全保留,无需调整,而且可以调整成需要的样板形式。
1、下载安装文件Solid Converter PDF,点击安装。
编辑提示:安装前有个下载安装插件的过程,因此需要保证网络连接通畅。
2、运行软件,按工具栏要求选择需要转换的PDF文档,点击右下的“转换”(Convert)按扭,选择自己需要的版式,根据提示完成转换。说白了就是不能直接提取需要下载第三方软件!