boolean在mysql里是什么类型
发布时间:2025-05-12 05:04:50 发布人:远客网络
一、boolean在mysql里是什么类型
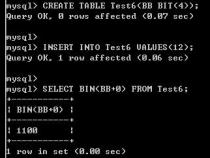
1、MySQL中boolean的类型是布尔类型。
2、在MySQL中,boolean是一种基础数据类型,用于存储逻辑值。这种数据类型可以接受两个值:TRUE或FALSE。虽然MySQL支持boolean类型,但在某些存储引擎中,它实际上是以TINYINT的形式存储的。这意味着,虽然你定义了一个列为boolean类型,但在内部,它可能以整数形式存储这些值。但在大多数情况下,特别是在使用InnoDB存储引擎时,MySQL会直接使用boolean数据类型,并以其原始形式存储TRUE或FALSE值。
3、值得注意的是,当你在SQL查询中使用boolean值时,应该确保始终使用大写字母来指定TRUE和FALSE,因为这是MySQL区分大小写的。虽然在某些情况下,你可以使用小写字母t或f来代替true和false,但为了保持代码的一致性和可读性,建议始终使用大写字母。
4、此外,当你在创建表时使用boolean数据类型时,要确保你的应用程序逻辑能够正确处理这种数据类型。由于boolean只能接受两个值,因此它非常适合用于需要二元决策的情况,例如标记某些记录为活动状态或非活动状态等。在使用boolean类型时,理解其背后的存储机制以及与应用程序逻辑的整合是非常重要的。
5、总之,在MySQL中,boolean是用于存储逻辑值的布尔类型,尽管在内部可能会有不同的存储方式,但在使用时应当注意其特性和使用场景。
二、mysql中char和varchar区别
在MySQL中,CHAR和VARCHAR是两种用于存储文本数据的数据类型,它们的区别:存储方式不同、存储空间不同、性能不同、适用场景不同。
CHAR:CHAR是固定长度的字符类型,它会在存储时自动填充空格以达到指定的长度。例如,如果定义一个CHAR(10)类型的字段,并存储“Hello”,则会在后面填充6个空格,占用总共10个字节的存储空间。
VARCHAR:VARCHAR是可变长度的字符类型,它只会存储实际使用的字符数。例如,如果定义一个VARCHAR(10)类型的字段,并存储“Hello”,则只会占用5个字节的存储空间。
CHAR:由于是固定长度,所以CHAR类型的字段会占用更多的存储空间。无论实际存储的数据长度是多少,它始终占用指定长度的存储空间。
VARCHAR:由于是可变长度,所以VARCHAR类型的字段只会占用实际数据长度的存储空间,因此在存储上更为节省空间。
CHAR:由于是固定长度,查询和检索CHAR类型的字段速度相对较快,因为每个值都具有相同的长度。
VARCHAR:由于是可变长度,查询和检索VARCHAR类型的字段相对较慢,因为需要在存储中搜索实际长度。
CHAR:适用于存储固定长度的数据,例如固定长度的代码、状态或者固定格式的字符串。
VARCHAR:适用于存储可变长度的数据,例如变长的文本、描述、用户输入等。
1、整数类型:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT。
2、浮点数类型:FLOAT、DOUBLE、DECIMAL。
3、字符类型:CHAR、VARCHAR、TEXT、TINYTEXT、MEDIUMTEXT、LONGTEXT、BLOB、TINYBLOB、MEDIUMBLOB、LONGBLOB。
4、日期和时间类型:DATE、TIME、DATETIME、TIMESTAMP、YEAR。
9、空间数据类型:GEOMETRY、POINT、LINESTRING、POLYGON。
三、mysql 有几种索引
1、如大家所知道的,Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE。
2、那么,这几种索引有什么功能和性能上的不同呢?
3、即为全文索引,目前只有MyISAM引擎支持。其可以在CREATE TABLE,ALTER TABLE,CREATE INDEX使用,不过目前只有 CHAR、VARCHAR,TEXT列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE INDEX创建FULLTEXT索引,要比先为一张表建立FULLTEXT然后再将数据写入的速度快很多。
4、全文索引并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name LIKE“%word%"这类针对文本的模糊查询效率较低的问题。在没有全文索引之前,这样一个查询语句是要进行遍历数据表操作的,可见,在数据量较大时是极其的耗时的,如果没有异步IO处理,进程将被挟持,很浪费时间,当然这里不对异步IO作进一步讲解,想了解的童鞋,自行谷哥。
5、创建ALTER TABLE table ADD INDEX `FULLINDEX` USING FULLTEXT(`cname1`[,cname2…]);
6、使用SELECT* FROM table WHERE MATCH(cname1[,cname2…]) AGAINST('word' MODE);
7、其中, MODE为搜寻方式(IN BOOLEAN MODE,IN NATURAL LANGUAGE MODE,IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION/ WITH QUERY EXPANSION)。
8、关于这三种搜寻方式,愚安在这里也不多做交代,简单地说,就是,布尔模式,允许word里含一些特殊字符用于标记一些具体的要求,如+表示一定要有,-表示一定没有,*表示通用匹配符,是不是想起了正则,类似吧;自然语言模式,就是简单的单词匹配;含表达式的自然语言模式,就是先用自然语言模式处理,对返回的结果,再进行表达式匹配。
9、对搜索引擎稍微有点了解的同学,肯定知道分词这个概念,FULLTEXT索引也是按照分词原理建立索引的。西文中,大部分为字母文字,分词可以很方便的按照空格进行分割。但很明显,中文不能按照这种方式进行分词。那又怎么办呢?这个向大家介绍一个Mysql的中文分词插件Mysqlcft,有了它,就可以对中文进行分词,想了解的同学请移步Mysqlcft,当然还有其他的分词插件可以使用。
10、Hash这个词,可以说,自打我们开始码的那一天起,就开始不停地见到和使用到了。其实,hash就是一种(key=>value)形式的键值对,如数学中的函数映射,允许多个key对应相同的value,但不允许一个key对应多个value。正是由于这个特性,hash很适合做索引,为某一列或几列建立hash索引,就会利用这一列或几列的值通过一定的算法计算出一个hash值,对应一行或几行数据(这里在概念上和函数映射有区别,不要混淆)。在java语言中,每个类都有自己的hashcode()方法,没有显示定义的都继承自object类,该方法使得每一个对象都是唯一的,在进行对象间equal比较,和序列化传输中起到了很重要的作用。hash的生成方法有很多种,足可以保证hash码的唯一性,例如在MongoDB中,每一个document都有系统为其生成的唯一的objectID(包含时间戳,主机散列值,进程PID,和自增ID)也是一种hash的表现。额,我好像扯远了-_-!
11、由于hash索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。那为什么还需要其他的树形索引呢?
12、在这里愚安就不自己总结了。引用下园子里其他大神的文章:来自 14的路的MySQL的btree索引和hash索引的区别
13、(1)Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
14、由于 Hash索引比较的是进行 Hash运算之后的 Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash算法处理之后的 Hash值的大小关系,并不能保证和Hash运算前完全一样。
15、(2)Hash索引无法被用来避免数据的排序操作。
16、由于 Hash索引中存放的是经过 Hash计算之后的 Hash值,而且Hash值的大小关系并不一定和 Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
17、(3)Hash索引不能利用部分索引键查询。
18、对于组合索引,Hash索引在计算 Hash值的时候是组合索引键合并后再一起计算 Hash值,而不是单独计算 Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用。
19、(4)Hash索引在任何时候都不能避免表扫描。
20、前面已经知道,Hash索引是将索引键通过 Hash运算之后,将 Hash运算结果的 Hash值和所对应的行指针信息存放于一个 Hash表中,由于不同索引键存在相同 Hash值,所以即使取满足某个 Hash键值的数据的记录条数,也无法从 Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
21、(5)Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
22、对于选择性比较低的索引键,如果创建 Hash索引,那么将会存在大量记录指针信息存于同一个 Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
23、愚安我稍作补充,讲一下HASH索引的过程,顺便解释下上面的第4,5条:
24、当我们为某一列或某几列建立hash索引时(目前就只有MEMORY引擎显式地支持这种索引),会在硬盘上生成类似如下的文件:
25、4bca452157d4 76#4556,77#45cc…
26、hash值即为通过特定算法由指定列数据计算出来,磁盘地址即为所在数据行存储在硬盘上的地址(也有可能是其他存储地址,其实MEMORY会将hash表导入内存)。
27、这样,当我们进行WHERE age= 18时,会将18通过相同的算法计算出一个hash值==>在hash表中找到对应的储存地址==>根据存储地址取得数据。
28、所以,每次查询时都要遍历hash表,直到找到对应的hash值,如(4),数据量大了之后,hash表也会变得庞大起来,性能下降,遍历耗时增加,如(5)。
29、BTREE索引就是一种将索引值按一定的算法,存入一个树形的数据结构中,相信学过数据结构的童鞋都对当初学习二叉树这种数据结构的经历记忆犹新,反正愚安我当时为了软考可是被这玩意儿好好地折腾了一番,不过那次考试好像没怎么考这个。如二叉树一样,每次查询都是从树的入口root开始,依次遍历node,获取leaf。
30、BTREE在MyISAM里的形式和Innodb稍有不同
31、在 Innodb里,有两种形态:一是primary key形态,其leaf node里存放的是数据,而且不仅存放了索引键的数据,还存放了其他字段的数据。二是secondary index,其leaf node和普通的BTREE差不多,只是还存放了指向主键的信息.
32、而在MyISAM里,主键和其他的并没有太大区别。不过和Innodb不太一样的地方是在MyISAM里,leaf node里存放的不是主键的信息,而是指向数据文件里的对应数据行的信息.
33、RTREE在mysql很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。
34、相对于BTREE,RTREE的优势在于范围查找.
35、(1)对于BTREE这种Mysql默认的索引类型,具有普遍的适用性
36、(2)由于FULLTEXT对中文支持不是很好,在没有插件的情况下,最好不要使用。其实,一些小的博客应用,只需要在数据采集时,为其建立关键字列表,通过关键字索引,也是一个不错的方法,至少愚安我是经常这么做的。
37、(3)对于一些搜索引擎级别的应用来说,FULLTEXT同样不是一个好的处理方法,Mysql的全文索引建立的文件还是比较大的,而且效率不是很高,即便是使用了中文分词插件,对中文分词支持也只是一般。真要碰到这种问题,Apache的Lucene或许是你的选择。
38、(4)正是因为hash表在处理较小数据量时具有无可比拟的素的优势,所以hash索引很适合做缓存(内存数据库)。如mysql数据库的内存版本Memsql,使用量很广泛的缓存工具Mencached,NoSql数据库redis等,都使用了hash索引这种形式。当然,不想学习这些东西的话Mysql的MEMORY引擎也是可以满足这种需求的。
39、(5)至于RTREE,愚安我至今还没有使用过,它具体怎么样,我就不知道了。有RTREE使用经历的同学,到时可以交流下!