Vue做出Observer有哪些方法
发布时间:2025-05-25 13:39:13 发布人:远客网络
一、Vue做出Observer有哪些方法
这次给大家带来Vue做出Observer有哪些方法,Vue做出Observer的注意事项有哪些,下面就是实战案例,一起来看一下。
本文是对 Vue官方文档深入响应式原理()的理解,并通过源码还原实现过程。
响应式原理可分为两步,依赖收集的过程与触发-重新渲染的过程。依赖收集的过程,有三个很重要的类,分别是 Watcher、Dep、Observer。本文主要解读 Observer。
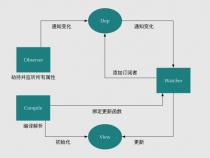
这篇文章讲解上篇文章没有覆盖到的 Observer部分的内容,还是先看官网这张图:
Observer最主要的作用就是实现了上图中touch-Data(getter)- Collect as Dependency这段过程,也就是依赖收集的过程。
还是以下面的代码为例子进行梳理:
(注:左右滑动即可查看完整代码,下同)
this.fullName= val+'TalkingData';
})在源码中,通过还原Vue进行实例化的过程,从开始一步一步到Observer类的源码依次为(省略了很多不在本篇文章讨论的代码):
if(process.env.NODE_ENV!=='production'&&
warn('Vue is a constructor and should be called with the `new` keyword')
Vue.prototype._init= function(options?: Object){
exportfunctioninitState(vm: Component){
functioninitData(vm: Component){
data= vm._data= typeofdata==='function'
observe(data, true/* asRootData*/)
}在initData方法中,开始了对data项中的数据进行“观察”,会将所有数据的变成observable的。接下来看observe方法的代码:
functionobserve(value: any, asRootData:?boolean): Observer| void{
if(!isObject(value)|| value instanceofVNode){
if(hasOwn(value,'__ob__')&& value.__ob__ instanceofObserver){
//确保value是单纯的对象,而不是函数或者是Regexp等情况
(Array.isArray(value)|| isPlainObject(value))&&
}observe方法的作用是给data创建一个Observer实例并返回,如果data有ob属性了,说明已经有Observer实例了,则返回现有的实例。Vue的响应式数据都会有一个ob的属性,里面存放了该属性的Observer实例,防止重复绑定。再来看new Observer(value)过程中发生了什么:
vmCount: number;// number of vms that has this object as root$data
def(value,'__ob__', this)
for(leti= 0; i< keys.length; i++){
defineReactive(obj, keys[i], obj[keys[i]])
observeArray(items: Array<any>){
for(leti= 0, l= items.length; i< l; i++){
}通过源码可以看到,实例化Observer过程中主要是做了两个判断。如果是数组,则对数组里面的每一项再次调用oberser方法进行观察;如果是非数组的对象,遍历对象的每一个属性,对其调用defineReactive方法。这里的defineReactive方法就是核心!通过使用Object.defineProperty方法对每一个需要被观察的属性添加get/set,完成依赖收集。依赖收集过后,每个属性都会有一个Dep来保存所有Watcher对象。按照文章最开始的例子来讲,就是对firstName和fullName分别添加了get/set,并且它们各自有一个Dep实例来保存各自观察它们的所有Watcher对象。下面是defineReactive的源码:
constproperty= Object.getOwnPropertyDeor(obj, key)
if(property&& property.configurable=== false){
// cater for pre-defined getter/setters
//检查属性之前是否设置了 getter/setter
//如果设置了,则在之后的 get/set方法中执行设置了的 getter/setter
constgetter= property&& property.get
constsetter= property&& property.set
//通过对属性再次调用 observe方法来判断是否有子对象
//如果有子对象,对子对象也进行依赖搜集
letchildOb=!shallow&& observe(val)
Object.defineProperty(obj, key,{
get: functionreactiveGetter(){
//如果属性原本拥有getter方法则执行
constvalue= getter? getter.call(obj): val
//如果有子对象,对子对象也进行依赖搜集
//如果属性是数组,则对每一个项都进行依赖收集
set: functionreactiveSetter(newVal){
//如果属性原本拥有getter方法则执行
//通过getter方法获取当前值,与新值进行比较
//如果新旧值一样则不需要执行下面的操作
constvalue= getter? getter.call(obj): val
/* eslint-disable no-self-compare*/
if(newVal=== value||(newVal!== newVal&& value!== value)){
/* eslint-enable no-self-compare*/
if(process.env.NODE_ENV!=='production'&& customSetter){
//如果属性原本拥有setter方法则执行
//如果原本没有setter则直接赋新值
//判断新的值是否有子对象,有的话继续观察子对象
childOb=!shallow&& observe(newVal)
}相信看了本文案例你已经掌握了方法,更多精彩请关注Gxl网其它相关文章!
二、vue原理相关总结
一、vue2.0的双向绑定是怎么实现的
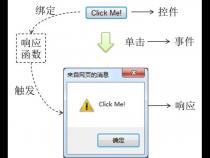
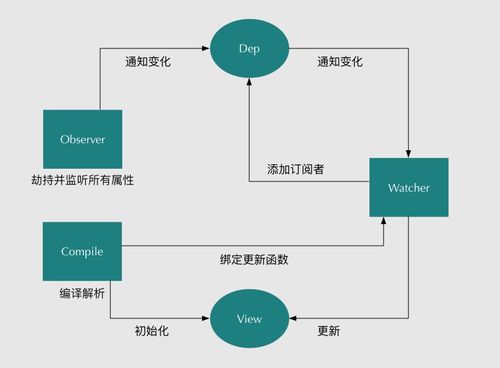
2、observer,compile,watcher
(1)observe是一个数据监听器,核心方法是Object.defineProperty
(3)compile是一个指令解析器,对需要监听的节点和属性进行扫描和解析。
3、此模式的优点:不需要显式调用,可以直接通知变化,更新视图;劫持了属性setter,不需要额外的diff操作
(2)不能监听整个对象,只能监听属性
(3)不能监听属性的增删,只能监听变化
(2)可直接监听整个对象,不用层层递归属性
(3)get和set时候直接有参数,不需要单独存储变量
(4)new Proxy()会返回一个新对象,不会污染源对象。
1、更新的原理:在数据读取时收集依赖,在赋值时通知依赖更新。
2、object有defineProperty方法,通过getter,setter只监听了属性的读取和赋值,但是新增属性和删除属性没有检测,所以专门提供了$set和$delete来实现
3、array,没有defineProperty方法,没有setter,通过get和新建数组方法拦截器修改原生方法push,pop,shift,unshift,splice,sort,reserve来实现监听,而通过修改数组下标操作数组的不会被检测,所以专门提供了$set和$delete来实现
4、$set(target, key, value)和$delete(target, propertyName/index)方法原理
(1)判断target是否是undefined,null,或者原始类型,或者vue实例,或者vue实例的跟数据对象
(2)target为数组,则还是通过调用splice操作索引更新数据
(3)target为对象,且为响应式,则调用defineReactive操作数据
(1)设计初衷:为了使模板中的逻辑运算更简单
(2)适用于数据被重复使用或者计算复杂费时的场景;依赖其他数据的场景
(3)读取缓存,依赖不变,则不需重新计算。(根据dirty标志判断)
相同点:都会观察页面的数据变化
不同点:(1)computed是读取缓存,watch每次都要重新执行;
(2)watch更适合数据变化时的异步操作和开销较大的操作。
computed依赖缓存,可以定义getter和setter,但是methods不行
1、abstract:非浏览器环境下使用
(1)默认。监听hashchange实现。
(1)h5新增的。允许开发者直接修改前端路由而不重新触发请求页面
(2)实现原理:监听popstate事件。能监听到用户点击浏览器的前进后退事件或者手动调用go,back,forward事件;不能监听到pushState和replaceState事件。
(3)为了避免浏览器刷新出现的404页面,需要在服务端配置兼容。
(4)如果浏览器不支持,会降级到hash模式
*通过vue.use插件机制和vue.mixin将store在beforeCreate和destroyed生命周期进行混入。
1、vuex解决了vue项目中的数据状态管理问题
3、原理:创建了单一的状态树,包含state,mutation,action,getter,module。
4、view(dispatch)action(commit)mutation(mutate)state(render)view
5、通过vue的data和computed,让state变成响应式,
6、通过vue.use插件机制和vue.mixin将store在beforeCreate生命周期进行混入。
1、作用:将回调延迟到下次DOM更新循环之后执行
2、原因:VUE在更新DOM时是异步的,vue检测到数据变化后,不会立即更新DOM,而是会开启一个事件队列,并缓冲同一时间循环中的所有数据变更,在下一次tick中,执行更新DOM。
3、js的运行机制:js是单线程的,基于事件循环,有宏任务和微任务。
(1)能力检测:Promise.then(微), MutationObserve(微),setImmediate(微),setTimeout(宏)
(2)将回调函数推入回调队列,锁上易步锁,执行回调。
七、keep-alive内置组件和LRU算法(队列)
1、自身不会渲染成DOM,没有常规的标签,是个函数组件,被他包裹的组件,切换时会被缓存在内存中,而不是销毁。
(1)可以有条件的缓存:include(匹配到的缓存),exclude(匹配到的不缓存),max(最多可以缓存多少组件实例)
2、原理:内部维护了this.cache(缓存的组件对象)和this.keys(this.cache中的key),运用LRU策略。
(1)命中了缓存的组件要调整组件key的顺序。
(2)缓存的组件数量如果超过this.max时,要删除第一个缓存组件。
(3)LRU(Least recently used,最近最少使用):根据数据的历史访问记录来进行淘汰数据。“如果数据最近被访问过,那么将来被访问的几率也更高。”
3、生命周期钩子:activated和deactivated,被keep-alive包括的组件激活和停用时调用。先停用组件的deactivated,再激活组件的activated
三、cxf怎样提高webservice性能,及访问速度调优
1、启用FastInfoset(快速信息集)
webservice的性能实在是不敢恭维。曾经因为webservice吞吐量上不去,对webservice进行了一些性能方面的优化,采用了FastInfoset,效果很明显,极端条件下的大数据量传输,性能提高60%,他可以减少传输成本,序列化成本和xml解析成本。
Cxf提供了FastInfoset协商机制,实现类见org.apache.cxf.feature.FastInfosetFeature,在bus中启用如下配置:
<cxf:features><cxf:fastinfoset force="false"/></cxf:features>
Force=false表示服务端和客户端第一次通信时会协商(通过检查标准的HTTP头的Accept字段,值为MIME类型的application/fastinfoset)是否启用FastInfoset支持,如果客户端不支持,则不启用快速信息集。
<groupId>com.sun.xml.fastinfoset</groupId>
<artifactId>FastInfoset</artifactId>
<version>1.2.9</version>
<scope>compile</scope>
FastInfoset参考:
客户端和服务器端是否使用Gzip压缩,也是基于http协议协商的(检查请求header中是否有Accept-encoding:gzip)。但是这里需要仔细权衡下。对于小数据量,启用gzip压缩支持是吃力不讨好的行为,数据量很小的时候,gzip压缩结果不明显,还浪费cpu。我们需要权衡数据大小,按照经验设置threshold为10*1024byte。
<bean class="org.apache.cxf.transport.common.gzip.GZIPFeature">
<property name="threshold"><value>10240</value></property>
官方文档指定是是配置org.apache.cxf.transport.http.gzip.GZIPFeature,但是这个类会找不到,可能是官方文档年久失修,造成一些混乱。官方文档中也没提示指定threshold,请参考GZIPFeature源代码。
参考
3、使用slf4j代替cxf默认日志组件
CXF默认使用 java.util.logging作为日志打印组件,其性能我就不过多评价,也不太便于我们做统一日志管理。目前系统使用的slf4j作为日志打印组件,替换如下:
在classpath中加入 META-INF/cxf/org.apache.cxf.Logger文件,文件内容为
org.apache.cxf.common.logging.Slf4jLogger
bus中加入<cxf:logging/>,请在测试环境中启用有助于debug
请求在service中处理遇到异常后,会调用请求链中所有拦截器的handleFault方法,参考PhaseInterceptorChain#unwind,然后判断请求是否单向请求,如果不是,则构建异常请求链,并构建异常message对象,调用异常请求链中的handleMessage方法(参考:AbstractFaultChainInitiatorObserver)
JAXWSMethodInvoker转发soap请求到指定对象的方法,如果在请求处理失败,调用updateHeader方法,把请求时的soap header放入返回header中。但是不同通过继承JAXWSMethodInvoker来实现清除异常时soap header也返回给客户端的问题,因为JAXWSMethodInvoker没有采用注入的机制(JaxWsServerFactoryBean#createInvoker)也没有chain.异常时,会由这些拦截器处理返回请求:
setup [ServerPolicyOutFaultInterceptor]
prepare-send [MessageSenderInterceptor, Soap11FaultOutInterceptor]
pre-stream [LoggingOutInterceptor, StaxOutInterceptor]
pre-protocol [WebFaultOutInterceptor]
拦截器初始化类OutFaultChainInitiatorObserver
我们可以在异常链中加入清理soap header的拦截器SoapHeaderOutFilterInterceptor,清理掉在系统异常时soapheader中有信息的问题。
返回错误状态码,在执行Soap11FaultOutInterceptor拦截器中被写死。
message.put(org.apache.cxf.message.Message.RESPONSE_CODE, new Integer(500));
为了使返回数据中有错误码,需要在Soap11FaultOutInterceptor后面加入拦截器
2、在项目测试时遇到一个报错invalid LOC header(bad signature),这个问题是因为jar包损坏照成的,虽然构建路径中有这个jar,但是还是会出现loadClass失败,清理maven本地仓库目录的jar,修改pom(比如加上一空行)让m2e重新加载。
3、Cxf中有一个很不错的特性,支持javascript访问soap webservice,客户端访问类似的请求,会生成javascript客户端,js编程时就可以使用此客户端提供的对象,启用此功能需要在引入
<import resource="classpath:META-INF/cxf/cxf-extension-javascript-client.xml"/>并且在依赖中加入:
<groupId>org.apache.cxf</groupId>
<artifactId>cxf-rt-javascript</artifactId>
<version>2.4.1</version>
<scope>compile</scope>