kettle怎样连接数据库连接
发布时间:2025-05-25 11:53:20 发布人:远客网络
一、kettle怎样连接数据库连接
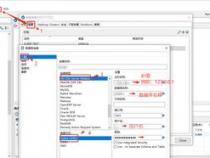
java调用kettle数据库类型资源库中的ktr此问题在1个月前或许已经接触,单是一直木有怎么用到,就被耽搁至今;问题的解决要来源于网络,其实我还想说问题的解决的是要靠我们自己的思想,不过多的言情,我们接下来直接进入主题吧!环境:kettle-spoon4.2.0,oracle11g,myeclipse6.5,sqlserver2008前提:在kettle图形界面spoon里面已经做好了一个ktr转换模型,此时我的ktr信息如下图:Step1:在myeclipse创建project,导入kettle集成所需要的包Step2:重点解析与code源码//定义ktr名字privatestaticStringtransName="test1";//初始化kettle环境KettleEnvironment.init();//创建资源库对象,此时的对象还是一个空对象KettleDatabaseRepositoryrepository=newKettleDatabaseRepository();//创建资源库数据库对象,类似我们在spoon里面创建资源库DatabaseMetadataMeta=newDatabaseMeta("enfo_bi","Oracle","Native","ip","sid","port","username","password");//资源库元对象,名称参数,id参数,描述等可以随便定义KettleDatabaseRepositoryMetakettleDatabaseMeta=newKettleDatabaseRepositoryMeta("enfo_bi","enfo_bi","kingdescription",dataMeta);//给资源库赋值repository.init(kettleDatabaseMeta);//连接资源库repository.connect("admin","admin");//根据变量查找到模型所在的目录对象RepositoryDirectoryInterfacedirectory=repository.findDirectory("/enfo_worker/wxj");//创建ktr元对象TransMetatransformationMeta=((Repository)repository).loadTransformation(transName,directory,null,true,null);//创建ktrTranstrans=newTrans(transformationMeta);//执行ktrtrans.execute(null);//等待执行完毕trans.waitUntilFinished();上面的两个步骤才可以确定是资源库中的那个路径下的ktr和我们用命令执行一样的-dir,-tran-job附上源码:packagekettle;importorg.pentaho.di.core.KettleEnvironment;importorg.pentaho.di.core.database.DatabaseMeta;importorg.pentaho.di.core.exception.KettleException;importorg.pentaho.di.repository.Repository;importorg.pentaho.di.repository.RepositoryDirectoryInterface;importorg.pentaho.di.repository.kdr.KettleDatabaseRepository;importorg.pentaho.di.repository.kdr.KettleDatabaseRepositoryMeta;importorg.pentaho.di.trans.Trans;importorg.pentaho.di.trans.TransMeta;/***Title:java调用kettle4.2数据库型资料库中的转换*Description:*Copyright:Copyright()2012*/publicclassExecuteDataBaseRepTran{privatestaticStringtransName="test1";publicstaticvoidmain(String[]args){try{//初始化kettle环境KettleEnvironment.init();//创建资源库对象,此时的对象还是一个空对象KettleDatabaseRepositoryrepository=newKettleDatabaseRepository();//创建资源库数据库对象,类似我们在spoon里面创建资源库DatabaseMetadataMeta=newDatabaseMeta("enfo_bi","Oracle","Native","ip","sid","port","username","password");//资源库元对象,名称参数,id参数,描述等可以随便定义KettleDatabaseRepositoryMetakettleDatabaseMeta=newKettleDatabaseRepositoryMeta("enfo_bi","enfo_bi","kingdescription",dataMeta);//给资源库赋值repository.init(kettleDatabaseMeta);//连接资源库repository.connect("admin","admin");//根据变量查找到模型所在的目录对象,此步骤很重要。RepositoryDirectoryInterfacedirectory=repository.findDirectory("/enfo_worker/wxj");//创建ktr元对象TransMetatransformationMeta=((Repository)repository).loadTransformation(transName,directory,null,true,null);//创建ktrTranstrans=newTrans(transformationMeta);//执行ktrtrans.execute(null);//等待执行完毕trans.waitUntilFinished();if(trans.getErrors()>0){System.err.println("TransformationrunFailure!");}else{System.out.println("Transformationrunsuccessfully!");}}catch(KettleExceptione){e.printStackTrace();}}}
二、kettle调度监控最佳实践
1、Kettle,这款用户规模最多的开源ETL工具,因其强大的功能而深受ETL从业者的喜爱。然而,Kettle的调度监控功能相对薄弱,Pentaho官方甚至推荐使用crontab(Unix平台)和计划任务(Windows平台)来实现调度功能。以下几种调度方式是常见实践:
2、一、spoon程序调用Job(kjb作业)
3、这是一条直接从Kettle内部调度的方式,可实现基本的定时调度功能,如按月、周、日、时点等方式启动。执行速度较快,但对ETL作业来说,它本质是后台数据处理,却要求spoon桌面程序持续运行。这对平台稳定性及自动化管理标准来说,是不理想的,因此企业通常不会选择此方案。
4、二、官方建议的crontab或计划任务
5、这是目前较为流行的方案,适合一般用户的基本调度需求。然而,对于复杂调度逻辑(如依赖、互斥、自定义条件分支、错误重试、断点续跑等高级特性)则难以应对。每次调用转换或作业,需要消耗大量时间(>10秒)来初始化新的Kettle运行环境。并行调用多个Kettle作业时,尤其是调用数据资源库中的作业,容易引发系统级错误,带来不稳定性。此外,初始化Kettle运行环境实质上是启动一个JVM进程,多个作业同时运行可能导致系统内存溢出,例如测试中5个转换的简单文本操作就已耗尽2GB内存。因此,此方案不适合并行调用多个Kettle作业。
6、三、自主开发Java程序调用Kettle类库
7、虽然可以提高调度效率,但自主开发解决方案需要投入较大的人力成本,特别是面对大规模作业调度需求时。这种方式还需额外开发监控和日志查看功能,后续维护成本也将显著增加。此外,即使采用流行框架如oozie,开发周期也可能长达6个人月。
8、针对调度监控需求,存在更敏捷适用的解决方案,如TASKCTL。它实现了对Kettle作业的实时调度监控管理,提供了全面的调度核心,包括依赖、互斥、串并引用策略、排程计划策略、容错策略、自定义策略等。并且,它具备企业级特性,支持跨平台、分布式、高可靠管理,无论在Linux还是Windows系统上的Kettle作业都能统一监控。此外,它还提供了灵活的人工干预功能,如运行任意流程分支、断点、暂停、强制通过、重跑等,并且调度效率得到大幅度提升。使用TASKCTL调度Kettle,运行相同ktr的60次,传统方式耗时约21分15秒,而采用TASKCTL则不到5秒(并行度为20)。此外,TASKCTL提供了实时刷新、图形、多角度多口径统计以及短信等全方位实时监控方式,以便用户及时掌握作业运行状态。
9、为了解决调度监控问题,首先需要安装TASKCTL服务端、桌面客户端及Kettle插件和实例流程。对于具备一定Linux基础的用户,整个部署过程预计在30分钟内完成。
三、Kettle简介
1、Kettle,作为一款开源的ETL工具,对于数据处理、转换和迁移至关重要。它由纯Java编写,支持跨平台运行,且无需安装,以高效稳定著称。中文名称“水壶”的灵感来源于其创始人MATT的理念,旨在将各种数据整合到一个统一的“壶”中,以预设的格式输出。
2、Kettle的结构包括Spoon,一个图形化工具,用于设计和管理ETL作业与转换,通过拖拽实现,可调用数据集成引擎或集群。另外,Data Integration Server是一个专用的ETL服务器,拥有企业控制台,提供证书管理、监控和远程服务器活动的管理功能。
3、核心组件包括Job和Transformation,Job负责工作流程的控制,而Transformation则负责数据的基本转换,通过步骤完成读取、过滤、清洗和加载操作。数据流以行的形式在步骤间传递,通过"跳"定义单向数据通道。步骤是转换的基础,每个步骤都有独特名称,处理数据并连接到输出"跳"。
4、下载Kettle后,需要配置JDK和环境变量。通过Spoon.bat启动后,即可直观体验,如从CSV导入数据到Excel。Kettle利用可视化编程,通过图形化界面构建复杂的ETL工作流,降低维护难度。数据类型丰富多样,包括字符串、数字、日期等,每个步骤都有元数据描述,支持并行处理,以高效处理大量数据。