Java 中是如何获取 IP 属地的
发布时间:2025-05-25 07:25:01 发布人:远客网络
一、Java 中是如何获取 IP 属地的
获取 Java中 IP属地的步骤简洁明了。首先,通过 HttpServletRequest对象捕获用户的 IP地址。接着,利用这个地址,我们能够获取对应的省份和城市信息。
在实现这一功能时,我们通常会借助一个专门的工具类,以确保在每次请求中都能准确地获取到客户端 IP地址。这一过程中,我们需考虑到几个关键的 HTTP请求头信息,如 X-Forwarded-For、X-Real-IP和 Proxy-Client-IP等,它们帮助我们获取到最原始的客户端 IP地址。
为了进一步处理这些 IP地址并获取相关地域信息,我们可以借助一个名为 Ip2region的工具。这是一个基于离线的 IP地址定位库,其准确率高达 99.9%,查询速度极快,仅需 0.0x毫秒。Ip2region提供了包括 Java、PHP、C、Python、Node.js、Golang、C#等多种语言的查询接口。
数据的聚合来自多个知名 IP查询服务,包括淘宝 IP地址库、GeoIP、纯真 IP库等,确保了数据的准确性。尽管数据更新依赖于上述服务的开放 API,但 Ip2region的数据覆盖了全球大部分国家和地区,精确度达到了城市级,且数据库文件大小控制在数 MB,优化了性能和存储。
为了提高查询效率,Ip2region内置了三种查询算法:memory、binary和 b-tree算法,分别对应不同场景的优化,使得查询响应时间在 0.x毫秒级别,显著提升了性能。
集成 Ip2region到项目中,我们只需要引入 Maven依赖即可。针对国内和国外用户的 IP属地显示需求,我们还需对 IP地址处理方法进行封装,以适应不同场景。
实践证明,使用 Ip2region可以高效、准确地获取 IP属地信息。无论是在国内还是国外,都能获取到相应的省份或国家信息。通过封装处理,我们可以轻松地在应用中实现这一功能。
对于更多关于 Ip2region的功能和用法,我们推荐访问其 GitHub项目页面进行深入学习。在这里,你可以找到详细的文档、示例代码以及社区支持,进一步探索 IP地址定位的更多可能性。
二、请问jvmcardtable和rset的工作原理
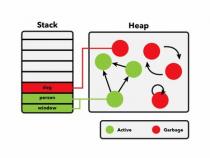
1、跨代引用概述,在Java堆内存中,年轻代和老年代之间存在的对象相互引用,这导致了在进行新生代的垃圾回收(GC)时,必须遍历整个老年代以识别存活对象,效率低下。为解决此问题,引入了卡表(Card Table)和记忆集(Remember Set,简称RSet)。
2、卡表用于跟踪年轻代对象被老年代对象引用的情况。内存被划分为一系列固定大小的区域(卡片),记录年轻代对象与老年代对象的引用关系。在老年代GC时,垃圾收集器扫描卡表以确定存活对象,提高效率。卡表大小通常为512字节,每次扫描的卡数量(stride)默认为256,以平衡扫描效率和线程切换开销。
3、伴随G1垃圾收集器的诞生,老年代和新生代物理空间变为不连续的region。为此,JVM使用了CSet(Collection Set)来存储任意年代的region信息。逻辑上,每个region都有一个RSet,用于记录其他region对自身对象的引用。RSet是一个哈希表,记录了指向自身对象的Card表索引,帮助识别跨代引用。
4、RSet、Card和Region的关系如下图所示,相互引用的三个region中,R1和R3细分为Card表级别,R2被R1和R3的某些区域引用,因此R2的RSet记录了R1和R2区域的索引,形成了循环引用。一个region的RSet有值,说明该区域有引用;无值则表明该区域不可达,可不进行扫描,减少GC工作量。
5、在YGC时,使用选定的年轻代region的RSet作为根集,避免扫描整个老年代。而在混合GC中,老年代记录了老代之间的引用,年轻代的引用由扫描所有年轻代region(的卡表)得出,大大减少了GC工作量。处理器屏障用于监测对象引用修改,通知垃圾收集器更新引用关系,确保跨代引用正确处理。
6、卡表解决年轻代GC扫描老年代的问题,RSet则解决所有region的扫描问题。卡表提示应扫描哪些区域,RSet提示应扫描哪些区域,减少无效扫描,提高GC效率。跨代引用的垃圾回收是Java虚拟机中的关键问题,通过优化数据结构和并发技术,可确保高效稳定的垃圾回收,提升Java应用程序性能和可靠性。
7、参考资源:infoq.com/articles/tuni... oracle.com/webfolder/te...
三、深入浅出之ip2region实现
在移动互联网应用中,用户的位置信息统计分析是一个常见的需求。获取用户位置信息通常有GPS定位和IP地址两种途径,但GPS定位受用户行为限制,精确度要求较低时,通过IP地址定位更为合适。要实现IP到地理位置的映射,需要构建IP和地理信息的对应库,并基于此提供定位服务。本文从实际需求出发,以GitHub上广受欢迎的ip2region库为例,探讨映射关系库设计以及IP快速转换为地理位置的方法。
市面上提供IP定位服务的公司众多,包括阿里、高德、百度等,也有免费服务如GeoIP、纯真IP等。这些服务通常通过HTTP请求获取地理位置信息,受限于API的访问频率限制和一次请求的必要性,对于大规模数据处理需求难以满足。
对于日常处理大量用户请求日志中的IP地址转为地理位置信息的需求,简单粗暴的方法是预先通过API获取所有公网IP地址对应的位置信息。然而,以访问淘宝IP地址库为例,遍历3.3亿国内IP地址需要约10年时间,即使是高德的企业用户,也需要大约11天。尽管这个时间在一定程度上是可以接受的,但这种方法在实际应用中并不高效。
为解决数据量大、处理速度快的难题,可以考虑生成IP库文件,直接存储IP地址与地理位置的对应关系。然而,直接存储大量IP字符串会占用大量存储空间,例如最短的IP地址“0.0.0.0”占用17个字节,最长的IP地址“111.111.111.111”占用15个字节,若将它们转换为整型存储,可以大幅减少空间消耗。
优化IP库文件的方法包括将拥有相同地理位置的连续IP地址合并为一条记录,以及将IP地址从字符串转换为整型存储。同时,可以只在内存中保留一份地理位置信息,并使用指针或文件偏移量+数据长度来访问对应信息。通过这些优化,最终生成的IP库文件大小显著减小,如ip2region库中最新版本的ip.merge.txt文件大小仅为39MB。
ip2region库的结构分为四个部分:super块、header索引区、数据区和索引区。该库提供了内存二分搜索、b+tree搜索和基于内存的二分搜索三种查询算法,均能在毫秒级时间内返回结果,满足快速搜索需求。
总结,ip2region库成功解决了IP定位问题,通过优化设计和高效算法实现了小内存占用、快速搜索和多语言支持,从而在GitHub上获得了8.4k星。其支持的语言包括Java、C#、PHP、C、Python、Node.js、PHP扩展(PHP5和PHP7)、Go、Rust、Lua、Lua_c以及Nginx等,满足了不同开发者的需求。