ADS-B数据获取
发布时间:2025-05-25 02:00:31 发布人:远客网络
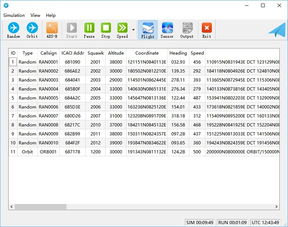
一、ADS-B数据获取
1、如果你正在寻找实时的航班飞行轨迹信息,FlightADSB是一个值得信赖的资源。这个网站提供了全球航班的动态追踪服务,通过先进的ADS-B技术,你可以直观地了解航班的实时位置、速度和高度等关键数据。访问FlightADSB,即可开始你的实时航班追踪之旅。
2、对于开发者来说,AeroAPI Developer Portal- FlightAware提供了更为丰富的航空数据接口。通过这个平台,开发者可以获取到更深层次的航班信息,包括航班历史数据、机场信息等,对构建航空数据分析或预测应用非常有帮助。你可以在这个AeroAPI Developer Portal上查找详细的开发者文档和API指南。
3、如果你对航空数据库感兴趣,Aircraft Database也是一个不错的去处。它收集了全球航班和航空器的详细资料,对于航空爱好者或是研究人员来说,是一个宝贵的参考资料库。你可以在Aircraft Database上搜索特定的飞机型号或航班编号,获取详尽的信息。
4、这些网址将为你提供丰富的航空数据,无论是追踪航班动态,还是开发相关应用,或是深入研究航空领域,都能在这些平台上找到所需的数据支持。
二、怎么往mysql中插入实时数据
您需要在您RDS for MySQL所在的云账号下开通阿里云数据传输服务。并点击此处
下载dts-ads-writer插件到您的一台服务器上并解压(需要该服务器可以访问互联网,建议使用阿里云ECS以最大限度保障可用性)。服务器上需要有Java
6或以上的运行环境(JRE/JDK)。
1.在分析型数据库上创建目标表,数据更新类型为实时写入,字段名称和MySQL中的建议均相同;
2.在阿里云数据传输的控制台上创建数据订阅通道,并记录这个通道的ID;
(见: ),
3.配置dts-ads-writer/app.conf文件,配置方式如下:
所有配置均保存在app.conf中,运行前请保证配置正确;修改配置后,请重启writer
"dtsAccessId":"",//拥有数据订阅通道的云账号的accessId,必须配置
"dtsAccessKey":"",//拥有数据订阅通道的云账号的accessKey,必须配置
"dtsTunnelId":"",//数据订阅通道的id,必须配置;注意是id,不是通道名称
"adsUserName":"",//访问您的分析型数据库的用户名(accessId),必须配置
"adsPassword":"",//访问您的分析型数据库的密码(accessKey),必须配置
"adsJdbcUrl":"",//访问分析型数据库的jdbc连接串,必须配置(格式jdbc:mysql://ip:port/dbname)
"primaryKeys":[""]//主键定义,必须配置;注意RDS和分析型数据库中的主键定义必须一致
"db":"",//源头RDS的db名称,必须配置
"table":"",//源头RDS的table名称,必须配置
"skipColumns":["col1"]//可选,若在此配置了RDS表某列名,则该列不会同步
"table":""//分析型数据库表的table名称,必须配置
"":""//rds表和ads表的列对应关系:key为rds的列名,value为分析型数据库的列名,选填,不填则按照列名一一对应
表示rds_db库下的rds_table表对应ads_table表,并且rds_table表的col1列对应ads_table表的col1_ads列,
rds_table表的col2列对应ads_table表的col2_ads列
1)RDS for MySQL表和分析型数据库中表的主键定义必须完全一致;如果不一致会出现数据不一致问题。如果需要调整RDS/分析型数据库表的主键,建议先停止writer进程;
2)一个插件进程中分析型数据库db只能是一个,由adsJdbcUrl指定;
3)一个插件进程只能对应一个数据订阅通道;如果更新通道中的订阅对象时,需要重启进程
4)RDS for MySQL中DDL操作不做同步处理;
5)更新app.conf需要重启插件进程才能生效;
6)如果工具出现bug或某种其它原因需要重新同步历史数据,只能回溯最近24小时的数据(在阿里云数据传输的控制台中修改消费位点);
7)插件的最大同步性能与运行插件的服务器的互联网带宽和磁盘IOPS成正比。
4.运行dts-ads-writer/bin/startup.sh(sh bin/startup.sh);
5.配置监控程序监控进程存活和日志中的常见错误码。
logs目录下的日志中的异常信息均以ErrorCode=XXXX ErrorMessage=XXXX形式给出,可以进行监控
三、数据库主要的模型有哪些
1、定义和限制条件:有且仅有一个节点,无父节点,此节点为树的根;其他节点有且仅有一个父节点;
2、②利用指针记录边向联系,查询效率高;
3、①只能表示1:N的联系。尽管有许多辅助手段实现M:N的联系,但比较复杂,不易掌握。
4、②层次模型的树是有序树(层次顺序)。对任一结点的所有子树都规定了先后次序,这一限制隐含了对数据库存取路径的控制。
5、③树中父子结点之间只存在一种联系,因此,对树中的任一结点,只有一条自根结点到达它的路径。
6、网状模型的2个特征:允许一个以上的节点无双亲;一个节点可以有多于一个的双亲;
7、①可以更加清晰表达现实,符合现实中的数据关系;
8、②不易掌握,网状模型的DDL,DDM复杂,并且并且要嵌入某一种高级语言(COBOL,c),用户不易掌握;
9、③应用程序复杂,记录之间的联系通过存取路径实现的,应用程序在访问数据时必须选择合适的存取路径,因此用户必须了解系统结构的细节,加重编写应用程序的负担;
10、现实世界的实体以及实体间的各种联系均用关系来表示,从用户角度看,关系模型中数据的逻辑结构是一张二维表。
11、①数据结构单一,关系模型中,不管是实体还是实体之间的联系,都用关系来表示,而关系都对应一张二维数据表,数据结构简单、清晰。
12、②关系规范化,并建立在严格的理论基础上,构成关系的基本规范要求关系中每个属性不可再分割,同时关系建立在具有坚实的理论基础的严格数学概念基础上。
13、③概念简单,操作方便,关系模型最大的优点就是简单,用户容易理解和掌握,一个关系就是一张二维表格,用户只需用简单的查询语言就能对数据库进行操作。
14、①查询效率不如格式化数据模型;
15、②为了提高性能,数据库管理系统需要优化用户查询,增加了数据库管理系统的开发难度;

