Zookeeper客户端Curator使用详解
发布时间:2025-05-25 01:29:53 发布人:远客网络
一、Zookeeper客户端Curator使用详解
维护多个博客比较麻烦,和博客园放弃维护,后续在个人博客持续更新:
Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等。Patrixck Hunt(Zookeeper)以一句“Guava is to Java that Curator to Zookeeper”给Curator予高度评价。
Zookeeper名字的由来是比较有趣的,下面的片段摘抄自《从PAXOS到ZOOKEEPER分布式一致性原理与实践》一书:
Zookeeper最早起源于雅虎的研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型的系统需要依赖一个类似的系统进行分布式协调,但是这些系统往往存在分布式单点问题。所以雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架。在立项初期,考虑到很多项目都是用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家Raghu Ramakrishnan开玩笑说:再这样下去,我们这儿就变成动物园了。此话一出,大家纷纷表示就叫动物园管理员吧——因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而Zookeeper正好用来进行分布式环境的协调——于是,Zookeeper的名字由此诞生了。
Curator无疑是Zookeeper客户端中的瑞士军刀,它译作"馆长"或者''管理者'',不知道是不是开发小组有意而为之,笔者猜测有可能这样命名的原因是说明Curator就是Zookeeper的馆长(脑洞有点大:Curator就是动物园的园长)。
curator-framework:对zookeeper的底层api的一些封装
curator-client:提供一些客户端的操作,例如重试策略等
curator-recipes:封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等
Maven依赖(使用curator的版本:2.12.0,对应Zookeeper的版本为:3.4.x,如果跨版本会有兼容性问题,很有可能导致节点操作失败):
newClient静态工厂方法包含四个主要参数:
核心参数变为流式设置,一个列子如下:
为了实现不同的Zookeeper业务之间的隔离,需要为每个业务分配一个独立的命名空间( NameSpace),即指定一个Zookeeper的根路径(官方术语:为Zookeeper添加“Chroot”特性)。例如(下面的例子)当客户端指定了独立命名空间为“/base”,那么该客户端对Zookeeper上的数据节点的操作都是基于该目录进行的。通过设置Chroot可以将客户端应用与Zookeeper服务端的一课子树相对应,在多个应用共用一个Zookeeper集群的场景下,这对于实现不同应用之间的相互隔离十分有意义。
当创建会话成功,得到client的实例然后可以直接调用其start()方法:
**创建一个节点,初始内容为空**
注意:如果没有设置节点属性,节点创建模式默认为持久化节点,内容默认为空
创建一个节点,指定创建模式(临时节点),内容为空
创建一个节点,指定创建模式(临时节点),附带初始化内容
创建一个节点,指定创建模式(临时节点),附带初始化内容,并且自动递归创建父节点
这个creatingParentContainersIfNeeded()接口非常有用,因为一般情况开发人员在创建一个子节点必须判断它的父节点是否存在,如果不存在直接创建会抛出NoNodeException,使用creatingParentContainersIfNeeded()之后Curator能够自动递归创建所有所需的父节点。
注意,此方法只能删除叶子节点,否则会抛出异常。
删除一个节点,并且递归删除其所有的子节点
删除一个节点,强制指定版本进行删除
guaranteed()接口是一个保障措施,只要客户端会话有效,那么Curator会在后台持续进行删除操作,直到删除节点成功。
注意:上面的多个流式接口是可以自由组合的,例如:
注意,此方法返的返回值是byte[ ];
读取一个节点的数据内容,同时获取到该节点的stat
注意:该接口会返回一个Stat实例
更新一个节点的数据内容,强制指定版本进行更新
注意:该方法返回一个Stat实例,用于检查ZNode是否存在的操作.可以调用额外的方法(监控或者后台处理)并在最后调用forPath()指定要操作的ZNode
注意:该方法的返回值为List<String>,获得ZNode的子节点Path列表。可以调用额外的方法(监控、后台处理或者获取状态watch, background or get stat)并在最后调用forPath()指定要操作的父ZNode
CuratorFramework的实例包含inTransaction()接口方法,调用此方法开启一个ZooKeeper事务.可以复合create, setData, check, and/or delete等操作然后调用commit()作为一个原子操作提交。一个例子如下:
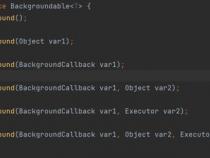
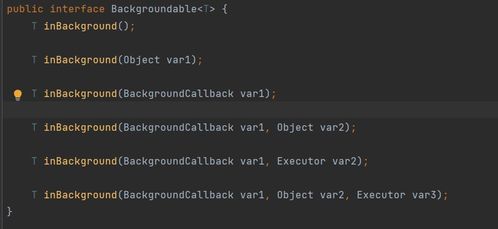
上面提到的创建、删除、更新、读取等方法都是同步的,Curator提供异步接口,引入了 BackgroundCallback接口用于处理异步接口调用之后服务端返回的结果信息。 BackgroundCallback接口中一个重要的回调值为CuratorEvent,里面包含事件类型、响应吗和节点的详细信息。
注意:如果#inBackground()方法不指定executor,那么会默认使用Curator的EventThread去进行异步处理。
提醒:首先你必须添加curator-recipes依赖,下文仅仅对recipes一些特性的使用进行解释和举例,不打算进行源码级别的探讨
重要提醒:强烈推荐使用ConnectionStateListener监控连接的状态,当连接状态为LOST,curator-recipes下的所有Api将会失效或者过期,尽管后面所有的例子都没有使用到ConnectionStateListener。
Zookeeper原生支持通过注册Watcher来进行事件监听,但是开发者需要反复注册(Watcher只能单次注册单次使用)。Cache是Curator中对事件监听的包装,可以看作是对事件监听的本地缓存视图,能够自动为开发者处理反复注册监听。Curator提供了三种Watcher(Cache)来监听结点的变化。
Path Cache用来监控一个ZNode的子节点.当一个子节点增加,更新,删除时, Path Cache会改变它的状态,会包含最新的子节点,子节点的数据和状态,而状态的更变将通过PathChildrenCacheListener通知。
通过下面的构造函数创建Path Cache:
想使用cache,必须调用它的 start方法,使用完后调用 close方法。可以设置StartMode来实现启动的模式
二、zk连接工具curator使用上的一些坑
zk的某核心开发者曾说curator对于zk的影响,就如同guava对于java的作用一样.
curator在对zk原始的api进行了大量包装,提供了一套更易用的fluent的api框架.但是使用中也存在这一些坑。
1.创建完pathChildrenCache,一定记得调用start方法!!!不然是不会生效的。
2.创建PathChildrenCache如果比较多的话,一定要记得自定义其使用的线程池参数,不然每次new出来一个PathChildrenCache,就会自行创建一个单线程池,创建不了多少就会开始抛超最多线程的个数异常.
3.失去zk连接后,如果重新创建了curatorFramework,同时也需要重新创建PathChildrenCache,之前创建的Listener是不会再有事件进来.
4.如果子节点个数太多,或者data太多,记得设置jute.maxbuffe参数,我们的项目中,节点是没有data的,但是由于一些公共服务的其consumers节点下的url实在是太多了,最多的一个consumers超过了10000个节点,而每个url的长度超过了400多个字符,超过了zk设置的4mb的数据长度,接近8mb大小,导致异常抛出.
5.如果每次去查询多个zk的结果,不一定要使用多线程,zk是支持异步调用的,使用curator时,调用inBackground时,传入BackgroundCallback就行。