要使Kettle能正常连接到数据库,需要给Kettle配置()
发布时间:2025-05-24 08:41:51 发布人:远客网络
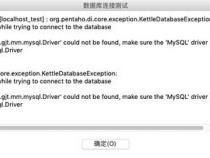
一、要使Kettle能正常连接到数据库,需要给Kettle配置()
为了使Kettle能够与数据库成功连接,需要给它配置一下数据库连接。具体而言,需要进行以下步骤:
3.在"数据库类型"下拉框中选择相应的数据库类型,如MySQL、Oracle等。
4.填写"主机名"、"端口号"、"数据库名称"等数据库的连接信息。
5.填写"用户名"和"密码",进行身份验证。
6.测试连接,确认数据库连接信息的准确性。
完成以上步骤后,Kettle就可以成功连接到相应的数据库,并进行数据读取和写入等操作。需要注意的是,每个不同类型的数据库在连接时需要填写的信息和参数不同,因此需要根据具体情况进行配置。
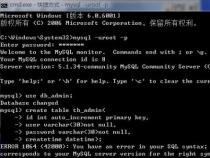
二、kettle如何连接oracle数据库
1、Kettle是一款开源的ETL工具,可以用于数据抽取、转换和加载。下面是连接Oracle数据库的步骤:
2、下载并安装Oracle JDBC驱动,可以从Oracle官网下载。
3、点击左侧的Database,选择Oracle。
4、在连接Oracle数据库的页面,填写以下信息:
5、Host name: Oracle数据库所在的主机名或IP地址。
6、Port number: Oracle数据库的监听端口号,默认为1521。
7、Database name:要连接的Oracle数据库名称。
8、User name:连接Oracle数据库的用户名。
9、Password:连接Oracle数据库的密码。
10、点击Test按钮,测试连接是否成功。
11、连接成功后,就可以在Trans中使用Oracle数据库了。
12、需要将Oracle JDBC驱动的jar包复制到Kettle的lib目录下。
13、在连接Oracle数据库时,需要保证Oracle数据库已经启动,并且监听程序也已经启动。
三、kettle怎样连接数据库连接
java调用kettle数据库类型资源库中的ktr此问题在1个月前或许已经接触,单是一直木有怎么用到,就被耽搁至今;问题的解决要来源于网络,其实我还想说问题的解决的是要靠我们自己的思想,不过多的言情,我们接下来直接进入主题吧!环境:kettle-spoon4.2.0,oracle11g,myeclipse6.5,sqlserver2008前提:在kettle图形界面spoon里面已经做好了一个ktr转换模型,此时我的ktr信息如下图:Step1:在myeclipse创建project,导入kettle集成所需要的包Step2:重点解析与code源码//定义ktr名字privatestaticStringtransName="test1";//初始化kettle环境KettleEnvironment.init();//创建资源库对象,此时的对象还是一个空对象KettleDatabaseRepositoryrepository=newKettleDatabaseRepository();//创建资源库数据库对象,类似我们在spoon里面创建资源库DatabaseMetadataMeta=newDatabaseMeta("enfo_bi","Oracle","Native","ip","sid","port","username","password");//资源库元对象,名称参数,id参数,描述等可以随便定义KettleDatabaseRepositoryMetakettleDatabaseMeta=newKettleDatabaseRepositoryMeta("enfo_bi","enfo_bi","kingdescription",dataMeta);//给资源库赋值repository.init(kettleDatabaseMeta);//连接资源库repository.connect("admin","admin");//根据变量查找到模型所在的目录对象RepositoryDirectoryInterfacedirectory=repository.findDirectory("/enfo_worker/wxj");//创建ktr元对象TransMetatransformationMeta=((Repository)repository).loadTransformation(transName,directory,null,true,null);//创建ktrTranstrans=newTrans(transformationMeta);//执行ktrtrans.execute(null);//等待执行完毕trans.waitUntilFinished();上面的两个步骤才可以确定是资源库中的那个路径下的ktr和我们用命令执行一样的-dir,-tran-job附上源码:packagekettle;importorg.pentaho.di.core.KettleEnvironment;importorg.pentaho.di.core.database.DatabaseMeta;importorg.pentaho.di.core.exception.KettleException;importorg.pentaho.di.repository.Repository;importorg.pentaho.di.repository.RepositoryDirectoryInterface;importorg.pentaho.di.repository.kdr.KettleDatabaseRepository;importorg.pentaho.di.repository.kdr.KettleDatabaseRepositoryMeta;importorg.pentaho.di.trans.Trans;importorg.pentaho.di.trans.TransMeta;/***Title:java调用kettle4.2数据库型资料库中的转换*Description:*Copyright:Copyright()2012*/publicclassExecuteDataBaseRepTran{privatestaticStringtransName="test1";publicstaticvoidmain(String[]args){try{//初始化kettle环境KettleEnvironment.init();//创建资源库对象,此时的对象还是一个空对象KettleDatabaseRepositoryrepository=newKettleDatabaseRepository();//创建资源库数据库对象,类似我们在spoon里面创建资源库DatabaseMetadataMeta=newDatabaseMeta("enfo_bi","Oracle","Native","ip","sid","port","username","password");//资源库元对象,名称参数,id参数,描述等可以随便定义KettleDatabaseRepositoryMetakettleDatabaseMeta=newKettleDatabaseRepositoryMeta("enfo_bi","enfo_bi","kingdescription",dataMeta);//给资源库赋值repository.init(kettleDatabaseMeta);//连接资源库repository.connect("admin","admin");//根据变量查找到模型所在的目录对象,此步骤很重要。RepositoryDirectoryInterfacedirectory=repository.findDirectory("/enfo_worker/wxj");//创建ktr元对象TransMetatransformationMeta=((Repository)repository).loadTransformation(transName,directory,null,true,null);//创建ktrTranstrans=newTrans(transformationMeta);//执行ktrtrans.execute(null);//等待执行完毕trans.waitUntilFinished();if(trans.getErrors()>0){System.err.println("TransformationrunFailure!");}else{System.out.println("Transformationrunsuccessfully!");}}catch(KettleExceptione){e.printStackTrace();}}}