es数据库是什么
发布时间:2025-05-24 05:11:41 发布人:远客网络
一、es数据库是什么
1、ElasticSearch(es)数据库是一个分布式、高扩展、高实时的搜索与数据分析引擎。
2、它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用ElasticSearch的水平伸缩性,能使数据在生产环境变得更有价值。ElasticSearch的实现原理主要分为以下几个步骤,首先用户将数据提交到Elastic Search数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
3、Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
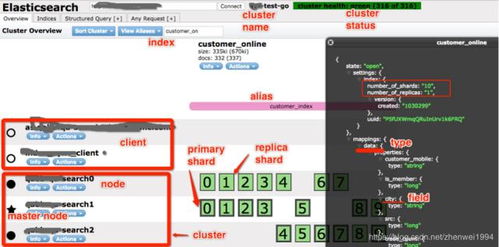
4、Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。”Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
5、Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。
6、另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务
二、【elasticsearch】elasticsearch查询报错问题整理
问题一:1. http_code: 4092.报错内容:Caused by: org.elasticsearch.search.query.QueryPhaseExecutionException: Result window is too large, from+ size must be less than or equal to: [20000] but was [83440000]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.at org.elasticsearch.search.DefaultSearchContext.preProcess(DefaultSearchContext.java:203)~[elasticsearch-5.6.4.jar:5.6.4]at org.elasticsearch.search.query.QueryPhase.preProcess(QueryPhase.java:95)~[elasticsearch-5.6.4.jar:5.6.4]at org.elasticsearch.search.SearchService.createContext(SearchService.java:497)~[elasticsearch-5.6.4.jar:5.6.4]at org.elasticsearch.search.SearchService.createAndPutContext(SearchService.java:461)~[elasticsearch-5.6.4.jar:5.6.4]at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:257)~[elasticsearch-5.6.4.jar:5.6.4]at org.elasticsearch.action.search.SearchTransportService$6.messageReceived(SearchTransportService.java:343)~[elasticsearch-5.6.4.jar:5.6.4]at org.elasticsearch.action.search.SearchTransportService$6.messageReceived(SearchTransportService.java:340)~[elasticsearch-5.6.4.jar:5.6.4]at com.floragunn.searchguard.ssl.transport.SearchGuardSSLRequestHandler.messageReceivedDecorate(SearchGuardSSLRequestHandler.java:178)~[?:?]at com.floragunn.searchguard.transport.SearchGuardRequestHandler.messageReceivedDecorate(SearchGuardRequestHandler.java:107)~[?:?]at com.floragunn.searchguard.ssl.transport.SearchGuardSSLRequestHandler.messageReceived(SearchGuardSSLRequestHandler.java:92)~[?:?]at com.floragunn.searchguard.SearchGuardPlugin$5$1.messageReceived(SearchGuardPlugin.java:493)~[?:?]at org.elasticsearch.transport.RequestHandlerRegistry.processMessageReceived(RequestHandlerRegistry.java:69)~[elasticsearch-5.6.4.jar:5.6.4]3.查询语句source={"from": 83438000,"size": 2000,"query":{"bool":{"must": [{"range":{"createTime":{"from": 1631807999000,"to": 1631894399000,"include_lower": true,"include_upper": false,"boost": 1.0}}}],"disable_coord": false,"adjust_pure_negative": true,"boost": 1.0}},"_source":{"includes": ["companyId","riskLabel"],"excludes": [ ]}}}]4.报错原因:
Elasticsearch查询索引结果时,用于分页的两个属性 from和size。可以使用from和size参数对结果进行分页。该from参数定义了您要获取的第一个结果的偏移量。该size参数允许您配置要返回的最大命中数。
Elasticsearch查询索引结果时,用于分页的两个属性 from和size。可以使用from和size参数对结果进行分页。该from参数定义了您要获取的第一个结果的偏移量。该size参数允许您配置要返回的最大命中数。
虽然from和size可以设置为请求参数,但也可以在搜索正文中设置。from默认为0,size默认为10。
注意,from+size不能超过index.max_result_window默认为 10,000的索引设置。目前ES集群返回结果最大值为20,000
而业务方却要求83438000行。故ES抛出异常。
参考:
并且这种分页也是浅分页,可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。
并且越往后的分页,执行的效率越低。总体上会随着from的增加,消耗时间也会增加。而且数据量越大,效果越明显!
scroll:游标查询允许我们先做查询初始化,然后再批量地拉取结果。这有点儿像传统数据库中的 cursor。
游标查询会取某个时间点的快照数据。查询初始化之后索引上的任何变化会被它忽略。它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引视图一样。
在不改变业务原意的情况下,建议使用scroll API
order_record_id字段类型为text类型,针对text类型的FIleData默认是禁用的,ElasticSearch无法对类型为text的字段进行聚合查询/排序。
避免使用text字段,使用keyword等别的字段进行代替。
对text字段类型开启filedata属性。(不推荐)
sentiment_rw?用户没有写入索引的权限功能。
业务方写入索引时,应检查自己的权限。
该查询特别长,这里只是截取了一点点。
查询sql语句过长,超出lucene的最大子句限制(1024)。
规范查询,尽量在上线前,提前进行测试。
三、Elasticsearch通关教程(五):如何通过SQL查询Elasticsearch
这篇博文本来是想放在全系列的大概第五、六篇的时候再讲的,毕竟查询是在索引创建、索引文档数据生成和一些基本概念介绍完之后才需要的。当前面的一些知识概念全都讲解完之后再讲解查询是最好的,但是最近公司项目忙经常加班,毕竟年底了。但是不写的话我怕会越拖越久,最后会不了了之了,所以刚好上海周末下雪,天冷无法出门,就坐在电脑前敲下了这篇博文。因为公司的查询这块是我负责的所以我研究了比较多点,写起来也顺手些。那么进入正文。
前面的文章介绍过,Elasticsearch的官方查询语言是 Query DSL,既然是官方指定的,说明最吻合 ES的强大功能,为ES做支撑。那么我们为什么还用 SQL查询?这是否是多此一举了呢?
其实,存在毕竟有存在的道理,存在即合理。SQL作为一个数据库查询语言,它语法简洁,书写方便而且大部分服务端程序员都清楚了解和熟知它的写法。但是作为一个 ES萌新来说,就算他已经是一位编程界的老江湖,但是如果他不熟悉 ES,那么他如果要使用公司已经搭好的 ES服务,他必须要先学习 Query DSL,学习成本也是一项影响技术开发进度的因素而且不稳定性高。但是如果 ES查询支持 SQL的话,那么也许就算他是工作一两年的同学,他虽然不懂 ES的复杂概念,他也能很好的使用 ES而且顺利的参加到开发的队伍中,毕竟SQL谁不会写呢?
我们正式介绍下我们的主角- Elasticsearch-SQL,Elasticsearch-SQL不属于 Elasticsearch官方的,它是 NLPChina(中国自然语言处理开源组织)开源的一个 ES插件,主要功能是通过 SQL来查询 ES,其实它的底层是通过解释 SQL,将SQL转换为 DSL语法,再通过DSL查询。
Elasticsearch-SQL目前已经支持大概所有版本的 ES,而且最近的6.5.x的也在支持的范围了,所以可以看得出来维护的还是蛮频繁的。
由于 ES 2.x和 5.x的版本区别(详细参考:版本选择),我们安装 ES插件是有点区别的,
在 5.0之前的安装方式为:plugin install
./bin/plugin install
在5.0之后(包括6.x)的安装方式为:elasticsearch-plugin install
./bin/elasticsearch-plugin install
如果我们安装不成功,我们可以直接下载 Elasticsearch-SQL插件的压缩包,然后解压,完成之后重命名文件夹为 sql,放到 ES的安装路径的 plugins目录中,例如:..\elasticsearch-6.4.0\plugins\sql。
完成此操作后,需要重新启动Elasticsearch服务器,否则会报错:Invalid index name [sql], must not start with‘‘];","status":400}。
Elasticsearch-SQL插件提供了可视化的界面,方便你执行SQL查询,界面如下:
在 elasticsearch 1.x/ 2.x,你可以直接访问如下地址:
而在 elasticsearch 5.x/6.x,这需要安装 node.js和下载及解压site,然后像这样启动web前端:
经过以上的操作之后,如果没出问题,现在就可以使用 SQL查询 ES了,其中有些是正常的 SQL语法,还有些是超越SQL语法的,相当于是对 SQL语法的增强,ES的查询格式是:
* from indexName limit 10
SELECT fields from indexName WHERE conditions
可以看到,我们以前的查询语句中,表名 tableName的地方现在改为了索引名 indexName,如果有索引Type,还可以这样写:
SELECT fields from indexName/type WHERE conditions
也可以同时查询索引的多个类型,语法如下:
SELECT fields from indexName/type1,indexName/type2 WHERE conditions
如果想知道当前SQL是如何将SQL解释为Elasticsearch的Query DSL,可以这样通过关键字explain。
* from indexName limit 10
select COUNT(*),SUM(age),MIN(age) as m, MAX(age),AVG(age)
FROM bank GROUP BY gender ORDER BY SUM(age), m DESC
SELECT address FROM bank WHERE address= matchQuery('880 Holmes Lane') ORDER BY _score DESC LIMIT 3
range age group 20-25,25-30,30-35,35-40
SELECT COUNT(age) FROM bank GROUP BY range(age, 20,25,30,35,40)
SELECT online FROM online GROUP BY date_histogram(field='insert_time','interval'='1d')
range date group by your config
SELECT online FROM online GROUP BY date_range(field='insert_time','format'='yyyy-MM-dd','2014-08-18','2014-08-17','now-8d','now-7d','now-6d','now')
Elasticsearch可以把地理位置、全文搜索、结构化搜索和分析结合到一起。而Elasticsearch-sql也基本支持所有地理位置相关的查询,对应 Elasticsearch的章节内容为Geolocation。
地理坐标盒模型过滤器(Geo Bounding Box Filter),指定一个矩形的顶部,底部,左边界和右边界,然后过滤器只需判断坐标的经度是否在左右边界之间,纬度是否在上下边界之间。
GEO_BOUNDING_BOX(fieldName,topLeftLongitude,topLeftLatitude,bottomRightLongitude,bottomRightLatitude)
SELECT* FROM location WHERE GEO_BOUNDING_BOX(center,100.0,1.0,101,0.0)
地理距离过滤器( geo_distance),以给定位置为圆心画一个圆,来找出那些地理坐标落在指定距离范围的文档。
GEO_DISTANCE(fieldName,distance,fromLongitude,fromLatitude)
SELECT* FROM location WHERE GEO_DISTANCE(center,'1km',100.5,0.5)
范围距离过滤器(Range Distance filter),以给定位置为圆心,分别以两个给定的距离画圆,找出与指定点距离在给定最小距离和最大距离之间的点,和geo_distance filter的唯一差别在于Range Distance filter是一个环状的,它会排除掉落在内圈中的那部分文档。
GEO_DISTANCE_RANGE(fieldName,distanceFrom,distanceTo,fromLongitude,fromLatitude)
SELECT* FROM location WHERE GEO_DISTANCE_RANGE(center,'1m','1km',100.5,0.50001)
4、Polygon filter(works on points)
找出落在多边形中的点。这个过滤器使用代价很大。当你觉得自己需要使用它,最好先看看 geo-shapes。
GEO_POLYGON(fieldName,lon1,lat1,lon2,lat2,lon3,lat3,...)
SELECT* FROM location WHERE GEO_POLYGON(center,100,0,100.5,2,101.0,0)
5、GeoShape Intersects filter(works on geoshapes)
这里需要使用WKT表示查询时的形状。
GEO_INTERSECTS(fieldName,'WKT')
SELECT* FROM location WHERE GEO_INTERSECTS(place,'POLYGON((102 2, 103 2, 103 3, 102 3, 102 2))
更多关于地理的查询可以参考这里。
我们以本系列的第一篇教程中我们创建的索引 nba来作示例,如下:
* from nba limit 10
2、查询当家球星是詹姆斯的球队信息
* from nba where topStar="勒布朗·詹姆斯"
* from nba order by date desc
4、查询拥有总冠军超过5个的球队信息
* from nba where championship>= 5
5、查询总冠军数量分别在1-5,5-10,10-15,15-20范围之间球队的数量
COUNT(championship) FROM nba GROUP BY range(championship, 1,5,10,15,20)
当然还有更多的写法,具体实现在这里就不多诉了,感兴趣的读者可以自己搭建个项目然后尝试下,更多特色SQL写法可以参考这里:
上面已经介绍了 Elasticsearch-SQL的安装和使用,那么我们如何在项目中使用它,Elasticsearch-SQL底层是使用Java语言开发的,通过解析SQL转换为 DSL语言,然后得出查询结果,解析结果成key-value的固定格式返回。
<groupId>org.nlpcn</groupId>
<artifactId>elasticsearch-sql</artifactId>
<version>x.x.x.0</version>
版本号(x.x.x)需要和 Elasticsearch的版本对应上,具体的对应关系大致可以参考下图:
但是不是所有的版本,我们都可以从Maven Repository里获取到,我们如果直接从Maven仓库里面只能获取如下几个版本的依赖,其中缺少很多版本:
那如果我们使用的是其他版本的 ES如何解决依赖 jar包问题呢?还记得我们开始下载插件解压后的sql文件夹吗?例如6.5.0版本的插件的解压后文件夹内容如下:
这里面就有我们需要的 jar包,有了 jar包就好办了,我们可以直接加入到项目中,当然最好的方式是上传到公司的私有仓库里面,然后通过pom文件依赖进来。
jar包问题解决之后就可以正式进入开发阶段了,新建一个springboot项目,引入各项依赖,一切准备就寻后,如何连接ES呢?
这里有两种方式可以实现我们的功能,一个是通过JDBC的方式,连接数据库一样连接ES。还有一种就是通过 tansport client方式。
public void testJDBC() throws Exception{
Properties properties= new Properties();
properties.put("url","jdbc:elasticsearch://192.168.3.31:9300,192.168.3.32:9300/"+ TestsConstants.TEST_INDEX);
DruidDataSource dds=(DruidDataSource) ElasticSearchDruidDataSourceFactory.createDataSource(properties);
Connection connection= dds.getConnection();
PreparedStatement ps= connection.prepareStatement("SELECT gender,lastname,age from"+ TestsConstants.TEST_INDEX+" where lastname='Heath'");
ResultSet resultSet= ps.executeQuery();
List<String> result= new ArrayList<String>();
System.out.println(resultSet.getString("lastname")+","+ resultSet.getInt("age")+","+ resultSet.getString("gender"))
这种方式是最直观的,用到了Druid连接池,所以我们还需要在项目中引入druid依赖,而且需要注意依赖的版本,否则会报错。
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.15</version>
这种方式很好理解,而且开发也方便,但是我在项目中应用了发现它有很多不足,所以我最后还是自己看了下源码,通过API的方式重新封装调用。
其实 elasticsearch-sql没有提供开发的文档,并没有介绍如何通过调用 Java API方式开发,我们需要阅读 elasticsearch-sql的源代码来发现它的service,然后包装成我们需要的,通过阅读源码我们发现了如下一个功能明显的Service类。
private static final Set<String> END_TABLE_MAP= new HashSet<>();
public SearchDao(Client client){
* Prepare action And transform sql
*@param sql SQL query to execute.
public QueryAction explain(String sql) throws SqlParseException, SQLFeatureNotSupportedException{
return ESActionFactory.create(client, sql);
SearchDao类中有一个explain方法,接收的参数就是一个字符串sql,返回结果是 QueryAction,QueryAction是一个抽象类,它又有如下子类
可以看出,每个子类对应的就是一个查询的功能,聚合查询,默认查询,删除,哈希连接查询,连接查询,嵌套查询等等。
获得的 QueryAction我们可以通过 QueryActionElasticExecutor类的executeAnyAction方法来接受,并内部处理,然后就能获得相应的执行结果。
public static Object executeAnyAction(Client client, QueryAction queryAction) throws SqlParseException, IOException{
if(queryAction instanceof DefaultQueryAction)
return executeSearchAction((DefaultQueryAction) queryAction);
if(queryAction instanceof AggregationQueryAction)
return executeAggregationAction((AggregationQueryAction) queryAction);
if(queryAction instanceof ESJoinQueryAction)
return executeJoinSearchAction(client,(ESJoinQueryAction) queryAction);
if(queryAction instanceof MultiQueryAction)