java中几种Map在什么情况下使用,并简单介绍原因及原理
发布时间:2025-05-23 19:22:12 发布人:远客网络
一、java中几种Map在什么情况下使用,并简单介绍原因及原理
一、Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。Map接口定义了如下常用的方法:
1、void clear():删除Map中所以键值对。
2、boolean containsKey(Object key):查询Map中是否包含指定key,如果包含则返回true。
3、boolean containsValue(Object value):查询Map中是否包含指定value,如果包含则返回true。
4、Set entrySet():返回Map中所包含的键值对所组成的Set集合,每个集合元素都是Map.Entry对象(Entry是Map的内部类)。
5、Object get(Object key):返回指定key所对应的value,如Map中不包含key则返回null。
6、boolean isEmpty():查询Map是否为空,如果空则返回true。
7、Set keySet():返回该Map中所有key所组成的set集合。
8、Object put(Object key,Object value):添加一个键值对,如果已有一个相同的key值则新的键值对覆盖旧的键值对。
9、void putAll(Map m):将指定Map中的键值对复制到Map中。
10、Object remove(Object key):删除指定key所对应的键值对,返回可以所关联的value,如果key不存在,返回null。
11、int size():返回该Map里的键值对的个数。
12、Collection values():返回该Map里所有value组成的Collection。
Map中包含一个内部类:Entry。该类封装了一个键值对,它包含了三个方法:
1、Object getKey():返回该Entry里包含的key值。
2、Object getValeu():返回该Entry里包含的value值。
3、Object setValue(V value):设置该Entry里包含的value值,并返回新设置的value值。
二、HashMap和Hashtable实现类:
1)同步性:Hashtable是同步的,这个类中的一些方法保证了Hashtable中的对象是线程安全的。而HashMap则是异步的,因此HashMap中的对象并不是线程安全的。因为同步的要求会影响执行的效率,所以如果你不需要线程安全的集合那么使用HashMap是一个很好的选择,这样可以避免由于同步带来的不必要的性能开销,从而提高效率。
2)值:HashMap可以让你将空值作为一个表的条目的key或value,但是Hashtable是不能放入空值的。HashMap最多只有一个key值为null,但可以有无数多个value值为null。
2、性能:HashMap的性能最好,HashTable的性能是最差(因为它是同步的)
1)用作key的对象必须实现hashCode和equals方法。
3)尽量不要使用可变对象作为它们的key值。
它的父类是HashMap,使用双向链表来维护键值对的次序,迭代顺序与键值对的插入顺序保持一致。LinkedHashMap需要维护元素的插入顺序,so性能略低于HashMap,但在迭代访问元素时有很好的性能,因为它是以链表来维护内部顺序。
Map接口派生了一个SortMap子接口,SortMap的实现类为TreeMap。TreeMap也是基于红黑树对所有的key进行排序,有两种排序方式:自然排序和定制排序。Treemap的key以TreeSet的形式存储,对key的要求与TreeSet对元素的要求基本一致。
1、Map.Entry firstEntry():返回最小key所对应的键值对,如Map为空,则返回null。
2、Object firstKey():返回最小key,如果为空,则返回null。
3、Map.Entry lastEntry():返回最大key所对应的键值对,如Map为空,则返回null。
4、Object lastKey():返回最大key,如果为空,则返回null。
5、Map.Entry higherEntry(Object key):返回位于key后一位的键值对,如果为空,则返回null。
6、Map.Entry lowerEntry(Object key):返回位于key前一位的键值对,如果为空,则返回null。
7、Object lowerKey(Object key):返回位于key前一位key值,如果为空,则返回null。
8、NavigableMap subMap(Object fromKey,boolean fromlnclusive,Object toKey,boolean toInciusive):返回该Map的子Map,其key范围从fromKey到toKey。
9、SortMap subMap(Object fromKey,Object toKey);返回该Map的子Map,其key范围从fromkey(包括)到tokey(不包括)。
10、SortMap tailMap(Object fromkey,boolean inclusive):返回该Map的子Map,其key范围大于fromkey(是否包括取决于第二个参数)的所有key。
11、 SortMap headMap(Object tokey,boolean inclusive):返回该Map的子Map,其key范围小于tokey(是否包括取决于第二个参数)的所有key。
WeakHashMap与HashMap的用法基本相同,区别在于:后者的key保留对象的强引用,即只要HashMap对象不被销毁,其对象所有key所引用的对象不会被垃圾回收,HashMap也不会自动删除这些key所对应的键值对对象。但WeakHashMap的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被回收。WeakHashMap中的每个key对象保存了实际对象的弱引用,当回收了该key所对应的实际对象后,WeakHashMap会自动删除该key所对应的键值对。
IdentityHashMap与HashMap基本相似,只是当两个key严格相等时,即key1==key2时,它才认为两个key是相等的。IdentityHashMap也允许使用null,但不保证键值对之间的顺序。
1、EnumMap中所有key都必须是单个枚举类的枚举值,创建EnumMap时必须显示或隐式指定它对应的枚举类。
2、EnumMap根据key的自然顺序,即枚举值在枚举类中定义的顺序,来维护键值对的次序。
3、EnumMap不允许使用null作为key值,但value可以。
二、工作中你是如何用Java 遍历 Map的呢
1、在java中遍历Map有不少的方法。我们看一下最常用的方法及其优缺点。
2、既然java中的所有map都实现了Map接口,以下方法适用于任何map实现(HashMap, TreeMap, LinkedHashMap, Hashtable,等等)
3、方法一、在for-each循环中使用entries来遍历
4、这是最常见的并且在大多数情况下也是最可取的遍历方式。在键值都需要时使用。
5、注意:for-each循环在java 5中被引入所以该方法只能应用于java 5或更高的版本中。如果你遍历的是一个空的map对象,for-each循环将抛出NullPointerException,因此在遍历前你总是应该检查空引用。
6、方法二、在for-each循环中遍历keys或values
7、如果只需要map中的键或者值,你可以通过keySet或values来实现遍历,而不是用entrySet。
8、该方法比entrySet遍历在性能上稍好(快了10%),而且代码更加干净。
9、你也可以在keySet和values上应用同样的方法。
10、该种方式看起来冗余却有其优点所在。首先,在老版本java中这是惟一遍历map的方式。另一个好处是,你可以在遍历时调用iterator.remove()来删除entries,另两个方法则不能。根据javadoc的说明,如果在for-each遍历中尝试使用此方法,结果是不可预测的。
11、从性能方面看,该方法类同于for-each遍历(即方法二)的性能。
12、方法四、通过键找值遍历(效率低)
13、作为方法一的替代,这个代码看上去更加干净;但实际上它相当慢且无效率。因为从键取值是耗时的操作(与方法一相比,在不同的Map实现中该方法慢了20%~200%)。如果你安装了FindBugs,它会做出检查并警告你关于哪些是低效率的遍历。所以尽量避免使用。
14、如果仅需要键(keys)或值(values)使用方法二。如果你使用的语言版本低于java 5,或是打算在遍历时删除entries,必须使用方法三。否则使用方法一(键值都要)。
三、求java里面的Hash<Map>的用法和基本解释,谢谢
HashMap和 HashSet是 Java Collection Framework的两个重要成员,其中 HashMap是 Map接口的常用实现类,HashSet是 Set接口的常用实现类。虽然 HashMap和 HashSet实现的接口规范不同,但它们底层的 Hash存储机制完全一样,甚至 HashSet本身就采用 HashMap来实现的。
通过 HashMap、HashSet的源代码分析其 Hash存储机制
实际上,HashSet和 HashMap之间有很多相似之处,对于 HashSet而言,系统采用 Hash算法决定集合元素的存储位置,这样可以保证能快速存、取集合元素;对于 HashMap而言,系统 key-value当成一个整体进行处理,系统总是根据 Hash算法来计算 key-value的存储位置,这样可以保证能快速存、取 Map的 key-value对。
在介绍集合存储之前需要指出一点:虽然集合号称存储的是 Java对象,但实际上并不会真正将 Java对象放入 Set集合中,只是在 Set集合中保留这些对象的引用而言。也就是说:Java集合实际上是多个引用变量所组成的集合,这些引用变量指向实际的 Java对象。
就像引用类型的数组一样,当我们把 Java对象放入数组之时,并不是真正的把 Java对象放入数组中,只是把对象的引用放入数组中,每个数组元素都是一个引用变量。
当程序试图将多个 key-value放入 HashMap中时,以如下代码片段为例:
HashMap<String, Double> map= new HashMap<String, Double>();
HashMap采用一种所谓的“Hash算法”来决定每个元素的存储位置。
当程序执行 map.put("语文", 80.0);时,系统将调用"语文"的 hashCode()方法得到其 hashCode值——每个 Java对象都有 hashCode()方法,都可通过该方法获得它的 hashCode值。得到这个对象的 hashCode值之后,系统会根据该 hashCode值来决定该元素的存储位置。
我们可以看 HashMap类的 put(K key, V value)方法的源代码:
//如果 key为 null,调用 putForNullKey方法进行处理
//根据 key的 keyCode计算 Hash值
int hash= hash(key.hashCode());
//搜索指定 hash值在对应 table中的索引
int i= indexFor(hash, table.length);
//如果 i索引处的 Entry不为 null,通过循环不断遍历 e元素的下一个元素
for(Entry<K,V> e= table[i]; e!= null; e= e.next)
//找到指定 key与需要放入的 key相等(hash值相同
if(e.hash== hash&&((k= e.key)== key
//如果 i索引处的 Entry为 null,表明此处还没有 Entry
addEntry(hash, key, value, i);
上面程序中用到了一个重要的内部接口:Map.Entry,每个 Map.Entry其实就是一个 key-value对。从上面程序中可以看出:当系统决定存储 HashMap中的 key-value对时,完全没有考虑 Entry中的 value,仅仅只是根据 key来计算并决定每个 Entry的存储位置。这也说明了前面的结论:我们完全可以把 Map集合中的 value当成 key的附属,当系统决定了 key的存储位置之后,value随之保存在那里即可。
上面方法提供了一个根据 hashCode()返回值来计算 Hash码的方法:hash(),这个方法是一个纯粹的数学计算,其方法如下:
h ^=(h>>> 20) ^(h>>> 12);
return h ^(h>>> 7) ^(h>>> 4);
对于任意给定的对象,只要它的 hashCode()返回值相同,那么程序调用 hash(int h)方法所计算得到的 Hash码值总是相同的。接下来程序会调用 indexFor(int h, int length)方法来计算该对象应该保存在 table数组的哪个索引处。indexFor(int h, int length)方法的代码如下:
static int indexFor(int h, int length)
这个方法非常巧妙,它总是通过 h&(table.length-1)来得到该对象的保存位置——而 HashMap底层数组的长度总是 2的 n次方,这一点可参看后面关于 HashMap构造器的介绍。
当 length总是 2的倍数时,h&(length-1)将是一个非常巧妙的设计:假设 h=5,length=16,那么 h& length- 1将得到 5;如果 h=6,length=16,那么 h& length- 1将得到 6……如果 h=15,length=16,那么 h& length- 1将得到 15;但是当 h=16时, length=16时,那么 h& length- 1将得到 0了;当 h=17时, length=16时,那么 h& length- 1将得到 1了……这样保证计算得到的索引值总是位于 table数组的索引之内。
根据上面 put方法的源代码可以看出,当程序试图将一个 key-value对放入 HashMap中时,程序首先根据该 key的 hashCode()返回值决定该 Entry的存储位置:如果两个 Entry的 key的 hashCode()返回值相同,那它们的存储位置相同。如果这两个 Entry的 key通过 equals比较返回 true,新添加 Entry的 value将覆盖集合中原有 Entry的 value,但 key不会覆盖。如果这两个 Entry的 key通过 equals比较返回 false,新添加的 Entry将与集合中原有 Entry形成 Entry链,而且新添加的 Entry位于 Entry链的头部——具体说明继续看 addEntry()方法的说明。
当向 HashMap中添加 key-value对,由其 key的 hashCode()返回值决定该 key-value对(就是 Entry对象)的存储位置。当两个 Entry对象的 key的 hashCode()返回值相同时,将由 key通过 eqauls()比较值决定是采用覆盖行为(返回 true),还是产生 Entry链(返回 false)。
上面程序中还调用了 addEntry(hash, key, value, i);代码,其中 addEntry是 HashMap提供的一个包访问权限的方法,该方法仅用于添加一个 key-value对。下面是该方法的代码:
void addEntry(int hash, K key, V value, int bucketIndex)
//获取指定 bucketIndex索引处的 Entry
Entry<K,V> e= table[bucketIndex];//①
//将新创建的 Entry放入 bucketIndex索引处,并让新的 Entry指向原来的 Entry
table[bucketIndex]= new Entry<K,V>(hash, key, value, e);
//如果 Map中的 key-value对的数量超过了极限
//把 table对象的长度扩充到 2倍。
上面方法的代码很简单,但其中包含了一个非常优雅的设计:系统总是将新添加的 Entry对象放入 table数组的 bucketIndex索引处——如果 bucketIndex索引处已经有了一个 Entry对象,那新添加的 Entry对象指向原有的 Entry对象(产生一个 Entry链),如果 bucketIndex索引处没有 Entry对象,也就是上面程序①号代码的 e变量是 null,也就是新放入的 Entry对象指向 null,也就是没有产生 Entry链。
在 JDK安装目录下可以找到一个 src.zip压缩文件,该文件里包含了 Java基础类库的所有源文件。只要读者有学习兴趣,随时可以打开这份压缩文件来阅读 Java类库的源代码,这对提高读者的编程能力是非常有帮助的。需要指出的是:src.zip中包含的源代码并没有包含像上文中的中文注释,这些注释是笔者自己添加进去的。
根据上面代码可以看出,在同一个 bucket存储 Entry链的情况下,新放入的 Entry总是位于 bucket中,而最早放入该 bucket中的 Entry则位于这个 Entry链的最末端。
* size:该变量保存了该 HashMap中所包含的 key-value对的数量。
* threshold:该变量包含了 HashMap能容纳的 key-value对的极限,它的值等于 HashMap的容量乘以负载因子(load factor)。
从上面程序中②号代码可以看出,当 size++>= threshold时,HashMap会自动调用 resize方法扩充 HashMap的容量。每扩充一次,HashMap的容量就增大一倍。
上面程序中使用的 table其实就是一个普通数组,每个数组都有一个固定的长度,这个数组的长度就是 HashMap的容量。HashMap包含如下几个构造器:
* HashMap():构建一个初始容量为 16,负载因子为 0.75的 HashMap。
* HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75的 HashMap。
* HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
当创建一个 HashMap时,系统会自动创建一个 table数组来保存 HashMap中的 Entry,下面是 HashMap中一个构造器的代码:
//以指定初始化容量、负载因子创建 HashMap
public HashMap(int initialCapacity, float loadFactor)
throw new IllegalArgumentException(
//如果初始容量大于最大容量,让出示容量
if(initialCapacity> MAXIMUM_CAPACITY)
initialCapacity= MAXIMUM_CAPACITY;
if(loadFactor<= 0|| Float.isNaN(loadFactor))
throw new IllegalArgumentException(
//计算出大于 initialCapacity的最小的 2的 n次方值。
while(capacity< initialCapacity)
//设置容量极限等于容量*负载因子
threshold=(int)(capacity* loadFactor);
table= new Entry[capacity];//①
上面代码中粗体字代码包含了一个简洁的代码实现:找出大于 initialCapacity的、最小的 2的 n次方值,并将其作为 HashMap的实际容量(由 capacity变量保存)。例如给定 initialCapacity为 10,那么该 HashMap的实际容量就是 16。
程序①号代码处可以看到:table的实质就是一个数组,一个长度为 capacity的数组。
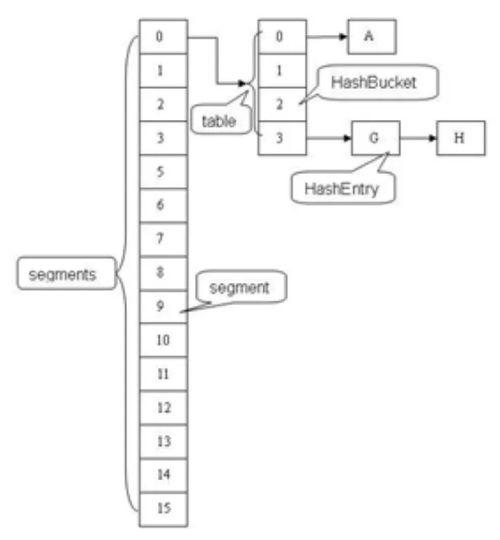
对于 HashMap及其子类而言,它们采用 Hash算法来决定集合中元素的存储位置。当系统开始初始化 HashMap时,系统会创建一个长度为 capacity的 Entry数组,这个数组里可以存储元素的位置被称为“桶(bucket)”,每个 bucket都有其指定索引,系统可以根据其索引快速访问该 bucket里存储的元素。
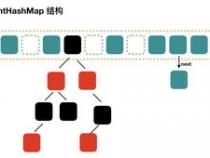
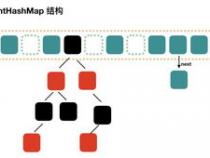
无论何时,HashMap的每个“桶”只存储一个元素(也就是一个 Entry),由于 Entry对象可以包含一个引用变量(就是 Entry构造器的的最后一个参数)用于指向下一个 Entry,因此可能出现的情况是:HashMap的 bucket中只有一个 Entry,但这个 Entry指向另一个 Entry——这就形成了一个 Entry链。如图 1所示:
当 HashMap的每个 bucket里存储的 Entry只是单个 Entry——也就是没有通过指针产生 Entry链时,此时的 HashMap具有最好的性能:当程序通过 key取出对应 value时,系统只要先计算出该 key的 hashCode()返回值,在根据该 hashCode返回值找出该 key在 table数组中的索引,然后取出该索引处的 Entry,最后返回该 key对应的 value即可。看 HashMap类的 get(K key)方法代码:
//如果 key是 null,调用 getForNullKey取出对应的 value
//根据该 key的 hashCode值计算它的 hash码
int hash= hash(key.hashCode());
//直接取出 table数组中指定索引处的值,
for(Entry<K,V> e= table[indexFor(hash, table.length)];
//如果该 Entry的 key与被搜索 key相同
if(e.hash== hash&&((k= e.key)== key
从上面代码中可以看出,如果 HashMap的每个 bucket里只有一个 Entry时,HashMap可以根据索引、快速地取出该 bucket里的 Entry;在发生“Hash冲突”的情况下,单个 bucket里存储的不是一个 Entry,而是一个 Entry链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry为止——如果恰好要搜索的 Entry位于该 Entry链的最末端(该 Entry是最早放入该 bucket中),那系统必须循环到最后才能找到该元素。
归纳起来简单地说,HashMap在底层将 key-value当成一个整体进行处理,这个整体就是一个 Entry对象。HashMap底层采用一个 Entry[]数组来保存所有的 key-value对,当需要存储一个 Entry对象时,会根据 Hash算法来决定其存储位置;当需要取出一个 Entry时,也会根据 Hash算法找到其存储位置,直接取出该 Entry。由此可见:HashMap之所以能快速存、取它所包含的 Entry,完全类似于现实生活中母亲从小教我们的:不同的东西要放在不同的位置,需要时才能快速找到它。
当创建 HashMap时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:增大负载因子可以减少 Hash表(就是那个 Entry数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap的 get()与 put()方法都要用到查询);减小负载因子会提高数据查询的性能,但会增加 Hash表所占用的内存空间。
掌握了上面知识之后,我们可以在创建 HashMap时根据实际需要适当地调整 load factor的值;如果程序比较关心空间开销、内存比较紧张,可以适当地增加负载因子;如果程序比较关心时间开销,内存比较宽裕则可以适当的减少负载因子。通常情况下,程序员无需改变负载因子的值。
如果开始就知道 HashMap会保存多个 key-value对,可以在创建时就使用较大的初始化容量,如果 HashMap中 Entry的数量一直不会超过极限容量(capacity* load factor),HashMap就无需调用 resize()方法重新分配 table数组,从而保证较好的性能。当然,开始就将初始容量设置太高可能会浪费空间(系统需要创建一个长度为 capacity的 Entry数组),因此创建 HashMap时初始化容量设置也需要小心对待。