datax传递多个参数到json
发布时间:2025-05-23 11:04:37 发布人:远客网络
一、datax传递多个参数到json
1、《data x传递两个参数到json》。DataX是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。DataX一般和DataX-Web联合使用,实现对任意数据库之间数据同步的调度执行。对于数据的同步,可以是全量更新和增量更新两种方式,对于大数据量的事物数据,例如:销售记录数据的同步,一般都是选择增量更新方式。
2、DataX-Web提供的增量更新支持基于自增ID的增量更新和基于时间的增量更新。在调度执行job任务时,dataX-Web会动态生成参数并在调用DataX执行时传入,例如:Python/opt/module/datax/bin/datax.py-p"-DlastTime=2022-01-01-DcurrentTime=2022-06-04"登录后复制DataX会把传入的参数写入环境变量,读入json脚本时会通过正则表达式查找${}包含的变量,并搜索环境变量进行替换。通过以上代码分析,可知在json任意的位置定义${}变量,都能够被替换,如:DataX的动态变量替换机制不够灵活,只能实现简单的变量替换,如果需要复杂的变量支持时,DataX就无法实现。例如:DataX-Web只能提供lastTime和currentTime两个参数,如果还需要支持其他参数,就没有办法了。针对这块考虑对DataX进行修改,引入avaitor表达式框架,通过Avaitor表达式丰富的功能,实现复杂的动态参数机制。祝您生活愉快,谢谢提问😊
二、mysql 中用正则表达式如何取一个字符串中指定的字段,
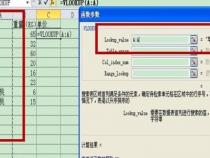
IN p_str VARCHAR(50),/*原始字符串*/
IN p_begin_str VARCHAR(50),/*要匹配的起始字符串*/
IN p_end_str VARCHAR(50))/*要匹配的结束字符串*/
OUT p_result VARCHAR(50))/*返回结果*/
DECLARE m_index INT DEFAULT 0;
/*计算第一个匹配字符串的索引位置*/
select locate(p_begin_str,p_str)+char_length(p_begin_str) into m_index;
/*计算第一个匹配字符串的长度*/
select locate(p_end_str,p_str,m_index) into m_len;
select SUBSTRING(p_str,m_index,m_len-m_index) INTO p_result;
CALL sp_str('[]abcd[12345]aa[]ss','abcd[',']',@result);
call sp_str('[]abcd[sdww]aa[]ss','abcd[',']',@result);
如果不用存储过程,可以直接写sql语句实现:
locate('abcd[',']abcd[12345]111[]')+CHAR_LENGTH('abcd['),
locate(']',']abcd[12345]111[]',CHAR_LENGTH('abcd['))-
(select locate('abcd[',']abcd[12345]111[]')+CHAR_LENGTH('abcd['))
返回子串substr在字符串str第一个出现的位置,如果substr不是在str里面,返回0.
mysql> select LOCATE('bar','foobarbar');
mysql> select LOCATE('xbar','foobar');
该函数是多字节可靠的。 LOCATE(substr,str,pos)
返回子串substr在字符串str第一个出现的位置,从位置pos开始。如果substr不是在str里面,返回0。
mysql> select LOCATE('bar','foobarbar',5);
SUBSTRING(str FROM pos FOR len)
从字符串str返回一个len个字符的子串,从位置pos开始。使用FROM的变种形式是ANSI SQL92语法。
mysql> select SUBSTRING('Quadratically',5,6);
三、hive json解析+正则匹配 双保险少踩坑
1、Hive JSON解析与正则匹配:双重保障,避免解析陷阱
2、当处理JSON数据时,可能会遇到解析问题,如不规范的埋点或上报数据中的特殊字符导致解析失败。为确保数据完整性,我们需要采取双重策略:一是使用自动化工具排查和修复,二是利用Hive的JSON解析函数和正则表达式进行兜底。
3、首先,遇到解析问题时,应利用json识别工具定位问题源头,可能是录入错误,如额外的空格。建议产研团队优化录入界面,同时在底层进行过滤和规范化处理,减少这类问题的发生。
4、在Hive中,get_json_object函数是常见工具,例如`get_json_object('{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}','$.rate')`可以获取'rate'的值。对于多列返回,可以使用`json_tuple`。对于数组,需先转为array类型,通过`explode()`函数处理,例如去除中括号和逗号,然后用`split()`函数分隔。
5、在某些特殊情况下,如遇到非标准JSON格式,正则匹配是个兜底选项。例如,通过`COALESC(json方法,正则方法)`,在JSON解析失败时,使用正则表达式识别数据,确保数据的准确性。具体正则内容和相关函数可参考相关文档。
6、总之,通过结合自动化工具排查、Hive的JSON解析技巧以及正则匹配,我们可以有效减少在处理JSON数据时的陷阱,确保数据的完整性和准确性。持续关注,我将定期分享更多关于机器学习、数据分析和实践应用的内容。